현재 이미지 분류 분야에서 SOTA를 달성한 “AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE “(ViT)는 NLP의 “Attention is all you need” (이하 Transformer )방법론을 vision classification task에 적용함으로써 달성하였습니다. 이를 통해 다른 분야를 아는 것도 매우 중요한 것이라는 깨달음을 주었습니다.
그럼으로 오늘은 이전에 리뷰한 NLP에 이어 Transformer 에 대해 리뷰하고자 합니다.
Transformer
Intro
Transformer에 대해 간단하게 소개하자면 2017년 구글에서 발표한 모델로 NLP에서 주로 사용되던 RNN (Recurrent Neural Network )을 사용하지 않고, 인코더-디코더를 따르면서 attention 만으로 구현된 모델입니다.
Sequence data를 처리하기 위해서 많이 사용되는 RNN은 t 번째의 output을 출력하기 위해서 t 번째 input과 t-1 번째 hidden state를 이용하여 문장의 순차적인 특성을 유지하며 학습 및 추론이 가능하도록 합니다.
하지만 RNN은 long-term dependency에 취약하다는 단점을 가지고 있습니다. long-term dependency problem이란 과거 정보를 토대로 미래 정보를 예측할 수 있지만, 과거 정보의 기간이 길어질수록, 정보 소실이 일어나, 미래 정보 예측이 어려워지는 문제를 말합니다. 그러므로 RNN은 순차적인 특성이 유지되지만, long-term dependency problem이 생기는 단점이 있습니다.
Transform은 recurrence를 사용하지 않고, attention mechanism만을 이용해 input과 output의 dependency를 포착하여 속도와 성능을 향상 시키는 방법을 사용합니다.
++ Transformers는 Google의 BERT와 최근 발표되면서 큰 이슈를 가져온 OpenAI의 GPTv3의 근간이 되는 방법론이기도 합니다. BERT는 Transformers의 attention 기반의 Encoder만 사용하고 pre-trained 방법과 fine-tunning을 개선하는 것으로 성능을 크게 개선한 방법론이며, GPT는 Transformers의 Decoder 부분을 사용하며, 문장을 순서대로 입력하는 방법 추구합니다.
Model Architecture
RNN은 recurrent를 가지기 위해 계산을 순서대로 합니다. 그로인하여 속도가 느려지는 단점이 있습니다. Transform은 recurrent를 제거하여 attention만 사용하는 방법으로 속도를 크게 향상 시켰습니다. 또한 transform 학습시 행렬 연산의 특성을 이용하여, encoder에서는 position에 대해, 즉 각각의 단어 대해 attention을 해주고, decoder에서는 masking 기법을 이용하여 병렬 처리가 가능하게 됩니다.
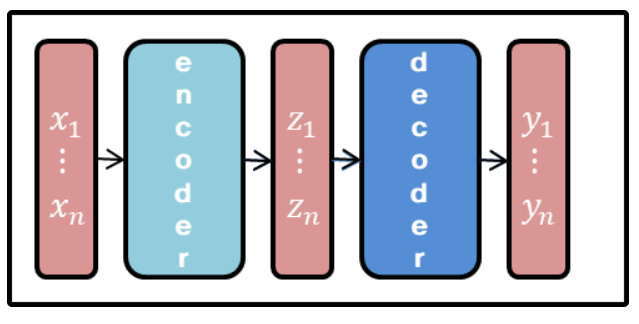
모델의 구조는 Seq2Seq에서 소개한 Encoder and Decoder 형태를 띕니다. Encoder는 연속적인 입력값(x1,…, xn)을 feature map(z1, …, zn)으로 변경 후, decoder를 통해 연속적인 출력값(y1, …, yn)하는 형태를 가집니다.
Positional Encoding
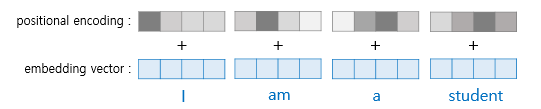
Transform은 RNN의 recurrence를 대체 하기 위해서, 즉 시간에 따른 정보의 흐름, 혹은 위치를 알고 있어야 합니다. Transform에서는 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용합니다. 이를 Positional encoding 이라고 합니다.
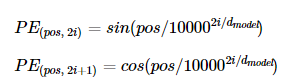
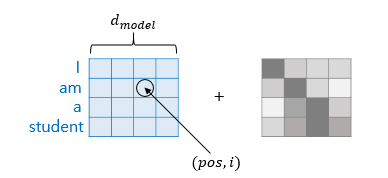
pos : 입력 문장에서의 위치
i : 임베딩 벡터 내의 차원의 인덱스
d_model : 표현 가능한 문장의 개수(논문에서는 512 차원)
Encoder
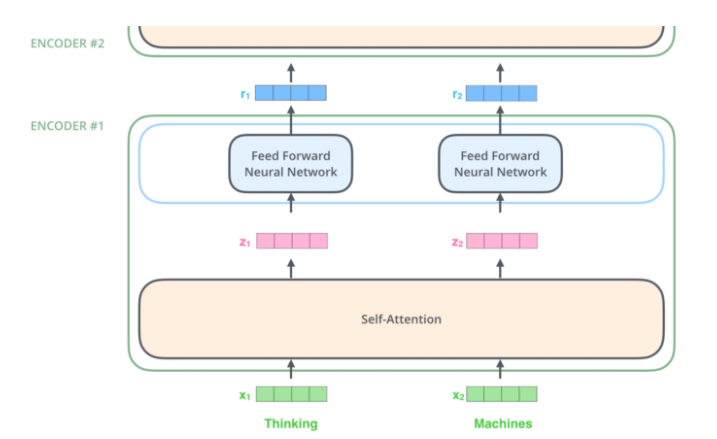
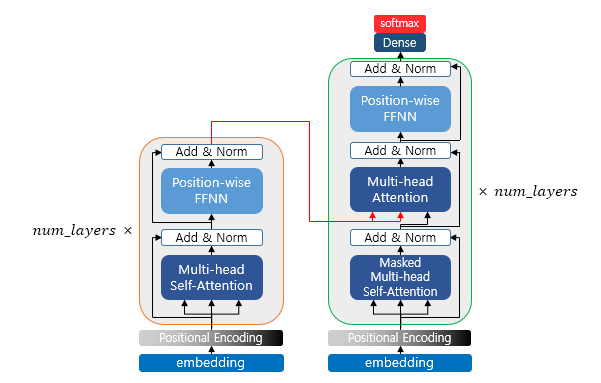
Transformer의 Encoder는 Fig 2와 같이 self-attention layer와 feed-forward neural network로 이뤄져 있습니다.
먼저 self-attention layer를 먼저 살펴보겠습니다.
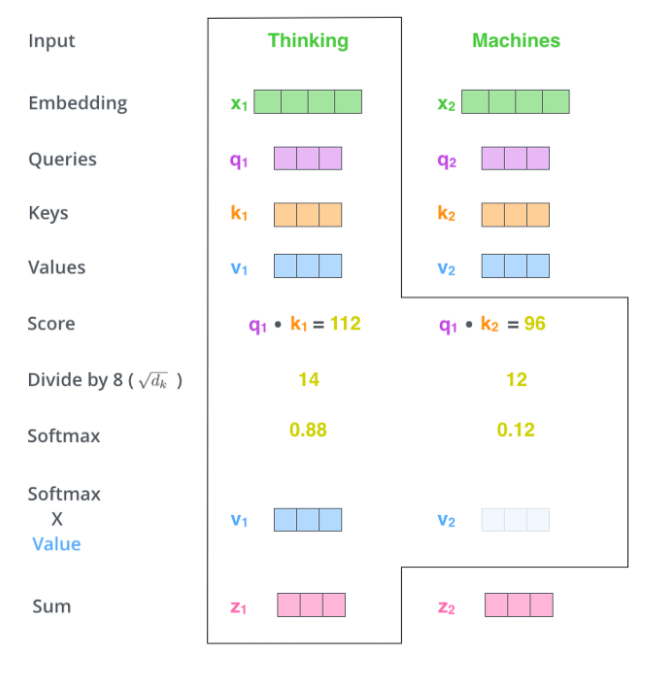
self-attention layer (Scaled Dot-Product Attention)
Queries(q)는 영향을 받는 단어 A를 나타내는 변수, Key(k)는 영향을 주는 단어 B를 나타내는 변수, Value(v)는 q-k간 영향에 대한 가중치, Embedding(x)는 단어 A의 임베딩 벡터 입니다. dim(q) = dim(k) = 64 dim, dim(x) = 512을 가집니다.
두 단어의 유사도에 대한 Score는 q와 k의 dot-product로 계산이 됩니다. 그 후, dim(q)^1/2로 scaling을 해주고 softmax로 확률적인 연산 후, 가중치인 V를 dot-product하여 attention score Z를 계산합니다.
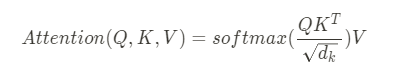
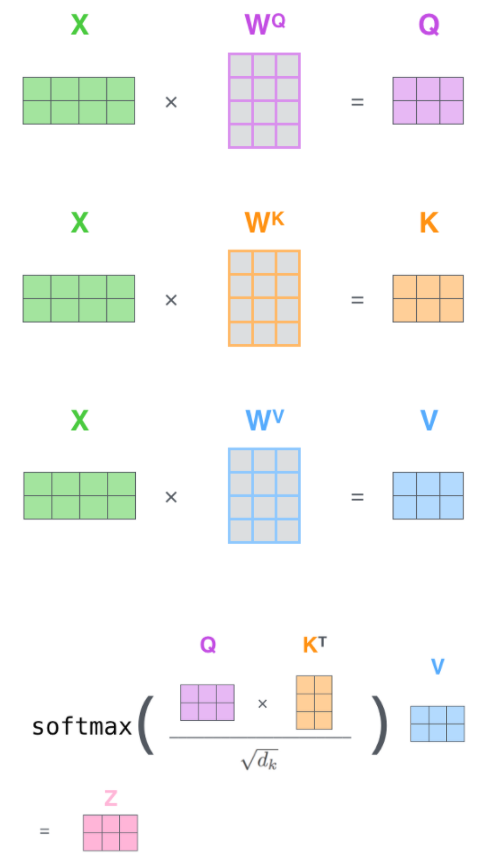
Q, K, V
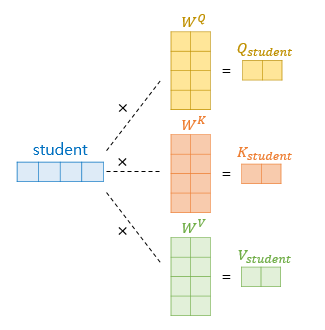
각 가중치는 d_model x (d_model/num_heads) 차원을 가집니다. num_heads는 아래에서 설명드릴 Multi-Head Attention의 개수이며, 논문에서는 8개를 가집니다. 그럼으로 512 x 512/8 = 512 x 64 차원을 가진 가중치 행렬 나옵니다. 각 단어들은 position encoding이 더해진 512차원의 임베팅 벡터와 가중치 행렬(512 x 64) dot-product를 함으로써 64차원을 가진 Q, K V 벡터가 나옵니다.
Multi-Head Attention
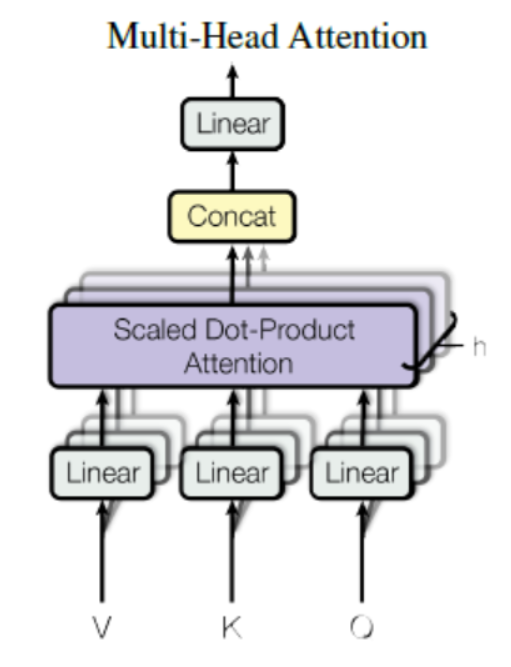
Transformer는 self-attention layer를 다중으로 구현한 Multi-head attention을 제시 했습니다.
Multi-head attention의 장점은 다른 포지션에 attention하는 모델의 능력을 향상시켰습니다. self-attention은 다른 단어들과의 관계들도 보지만, 막상 들여다보면 자기 자신의 단어에 더 많은 영향을 받는 것은 사실입니다. 여러 개의 “representation sub-spaces”를 생성할 수 있습니다. 무슨 뜻이냐면 여러 개의 Attention을 가진 Head는 각각 무작위로 Query, Key, Value가 초기화되므로, 각각 다른 표현 subspace에 embedding을 투영하기 때문입니다.
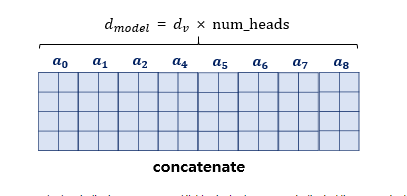
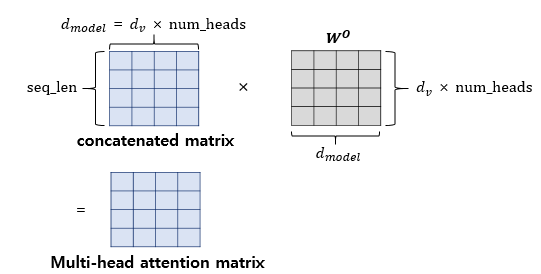
여러 head가 생기면서 Sum z vector 가 많아지면서 차원이 맞지 않아 decoder에서 사용하기 힘들어집니다. 이를 W(weight matrix)를 곱해줘서 차원을 맞춰 해결합니다.
Padding Mask
Transformer에서는 long-term dependency problem 해결하기 위한 방법으로 <pad>라는 문장을 중간 중간 추가함으로써, 성능 향상을 가져옵니다. 예를 들자면
- 철수는 배가 고프다.
- 그는 식당을 가려고 한다.
- 식당이 문을 닫아 __는 슬프다.
다음 위의 예시에서 우리는 빈 칸이 그녀나 또 다른 이름이 아닌 그 혹은 철수라는 것을 연속적인 문장 데이터를 토대로 이해 할 수 있습니다. Padding mask 는 사람이 가진 연속적인 문장으로부터 빈 내용을 추론하는 능력을 착안하여 가져온 기법입니다.
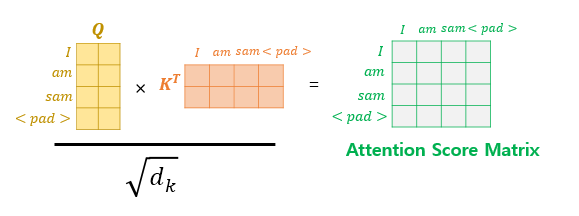
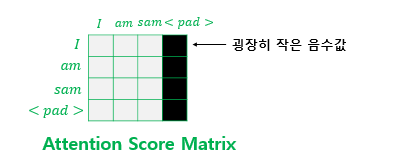
Padding mask 는 Self-Attention에서 계산되어집니다. <pad>라는 문장이 Padding mask에 해당합니다. 해당 값은 -1e9라는 아주 작은 음수 값으로 대체 되며, Q, K가 dot-product가 되면서 Fig 9-1과 같이 아주 작은 값을 가지게 되며, 0에 가까운 값을 가지면서, 마스킹을 하게 됩니다.
Position-wise FFNN + Residual connection + Layer Normalization
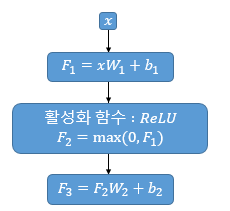
Position-wise FFNN는 쉽게 혹은 다르게 표현하자면 MLP, Fully-connected NN입니다. Multi-head Self-Attention으로 된 값이 사용되며, Fig 10-2에서는 따로 표현되어 서로 다른 layer로 보이지만, 실제로는 weight, bias를 공유하는 하나의 층입니다.
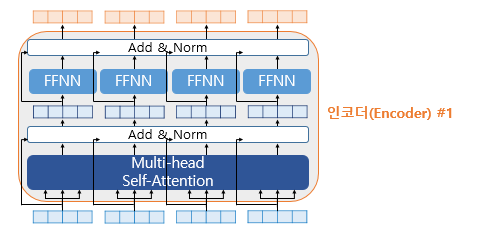
각 들은 vanishing을 줄이기 위해 Residual connection + Layer Normalization 방법을 사용합니다. 구조는 Fig 10-2에서 확인 가능 합니다.
Decoder
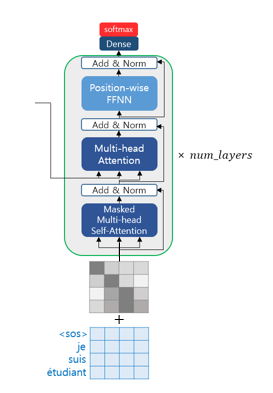
Decoder에서도 Encoder와 유사한 구조를 가졌으며, 입력 문장에 포지셔닝 인코딩을 거친 값들이 입력 데이터로 사용됩니다. Encoder와의 차이점은 입력 문장 행렬로부터 각 시점의 단어를 예측하도록 훈련이 됩니다. 하지만 아쉽게도 기존 방법과 동일하게 모든 문장간 dot-product 이용한 연산의 특성상 미래 시점의 단어까지도 참고할 수 있는 현상이 발생합니다. 이를 해결 하고자 Transformer에서는 look-ahead mask를 사용합니다.
look-ahead mask
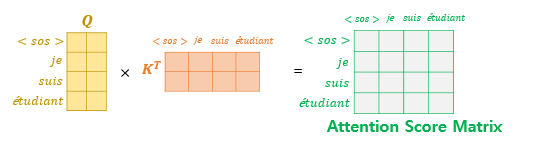
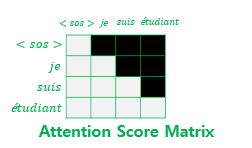
look-ahead mask는 이전에 설명드린 Padding mask와 동일한 방법론이며, 단지 미래 시점 부분을 가린다는 부분에서 다른 점을 가집니다.
Encoder-Decoder attention
Encoder의 마지막 층의 값 중 Key K, Value V 값이 입력 값으로 들어가며, look-ahead mask를 통해 미래 시점의 값이 mask된 Query Q 값이 입력값을 사용되어집니다. 그럼으로써 Decoder는 미래 시점 예측을 학습 할 수 있도록 됩니다.
++ 손실 함수는 task에 맞게 다르게 사용됩니다. e.g. 분류 문제 -> 크로스 엔트로피
vanishing을 줄이기 위해 Residual connection + Layer Normalization을 사용한다고 하셨는데 해당 방법들을 사용하면 vanishing이 사라지는 이유가 뭔가요??
제가 대신 답변드리면, 먼저 Residual connection은 layer가 깊어질수록 학습이 잘 안되는 gradient vanishing을 해결하고자 고안된 기법입니다.(기법에 대한 설명은 해당 링크에 설명이 잘 나와있어서 올립니다.https://ganghee-lee.tistory.com/41)
또한 Layer Normalization 역시 학습이 안정하게 되기 위해 사용되는 batch normalization과 유사한 기법으로, 활성함수의 변경이 아닌 입력 feature들의 분포를 정규화하여 gradient vanishing 문제를 해결하는 기법입니다.