

해당 논문은 video들 간의 similarity를 계산하기 위해 방법론인 ViSiL을 제안한 논문입니다. 주로 video-to-video retrieval시 video의 전체 frame에서 spatio-temporal한 정보를 추출하고 이를 aggregate하여 하나의 vector로 만들게 됩니다. 그러나 저자가 생각하기에 이는 frame-level에서 지역적인 정보를 잃어버린다고 생각하였으며 이를 보완하고자 aggregate 이전에 video 들의 모든 feature tensor들간의 similarity matrix를 활용하는 방법을 고안해내었습니다.
1. Preliminaries
논문에서 제안된 방법론에 대해 설명드리기 앞서 간단한 두가지의 개념을 먼저 설명드리려합니다.
- Tensor Dot (TD)
이는 간단히 고차원의 tensor를 곱하여 표현한 것으로 크기가 a x b x c 인 A tensor와 크기가 c x d x e 인 B tensor의 TD는 크기가 a x b x d x e 인 tensor라는 점만 알아두시면 편할 듯 합니다.
- Chamfer Similarity (CS)
이는 Chamfer distance의 반대되는 값입니다. 만약 크기가 N인 집합과 크기가 M인 집합이 있으면 이 둘 간의 similarity matrix는 NxM의 크기로 나타낼 수 있게 됩니다. 이렇게 matrix를 만들었을 때 각 열 중의 가장 큰 값을 모으게 되면 N 개의 max similarity가 나오게 되고 이들의 평균을 CS라고 합니다. 그러나 열이 아닌 행 중의 가장 큰 값을 모아 M 개의 값의 평균은 열로 구했을 때와 같은 값으로 성립하지 않습니다. 이렇게 symmetric한 성질을 적용하기 위해 열과 행 기준으로 구한 값의 평균을 SCS라고 정의했습니다.
2. ViSiL decription
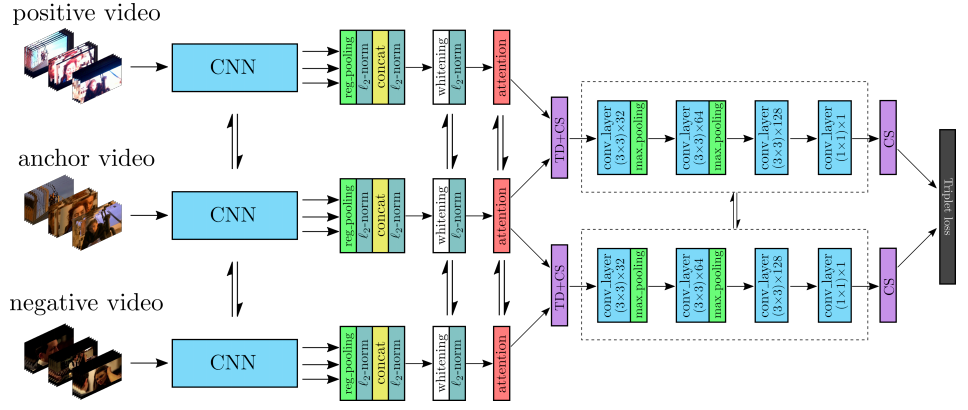
Fig 2에서는 ViSiL의 전체 network 구조를 확인할 수 있습니다. Feature extraction 과 region polling 과정을 거친 feature map에 PCA와 weighted attention mechanism을 적용시킵니다. 이와 같이 frame-level의 feature가 나오게 되고 이 feature에 TD와 CS를 적용시켜 모든 feature 간의 similarity matrix를 구하게 됩니다. 이렇게 구한 matrix로 CNN network를 태워 video-level의 similarity model을 triplet loss로 학습 시키게 됩니다.
2.1 Frame-to-frame similarity
Extraction 과정을 거친 후 나온 frame-level 의 feature가 크기가 NxNxC인 M_{d}, M_{b} 라고 한다면 이들의 similarity matrix를 구하기에는 3d라 어려움이 있을 수 있습니다. 이를 해결하기 위해 각각 NxN개의 크기가 C인 vector로 표현하고 이 M_{d}과 M_{b} 에서 생긴 NxN개의 vector를 각각 dot 연산한다면 (NxN) x (NxN) 크기의 결과가 나오는 TD가 가능해지고 이를 통해 CS를 구할 수 있게 됩니다.
2.2 Video-to-video similarity
앞선 frame-to-frame similarity 과정에서 구한 TD에 CS를 결합해 새롭게 4개의 layer로 구성된 convolution layer를 통과시키게 됩니다. 이렇게 두 개의 video q와 p에서 나온 결과 값은 S_{v}^{qp}로 표현되며 여기에 아래와 같이 hard tanh 적용해 범위를 제한하여 video-level의 CS를 구하게 됩니다.
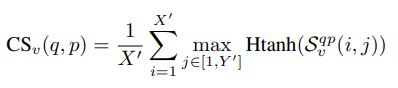
2.3 Loss function
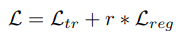
Loss function은 위 식 (2)와 같이 두 개의 term으로 구성됩니다. 우선 L_{tr} 은 triplet margin loss 이며 식(3) 처럼 anchot video (v) 와 positive video (v^{+}), negative video (v^{-}) 간의 CS로 구성됩니다.
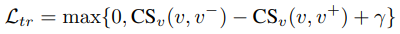
L_{reg} 는 Video-to-video similarity 모듈에서 CS 계산시 hard tanh를 사용할 때 높은 값에 페널티를 줘 정규화를 시켜주게 됩니다. 이는 식 (4)와 같이 구성됩니다.
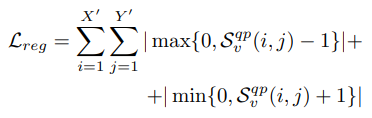
3. Experiments
- Ablation study
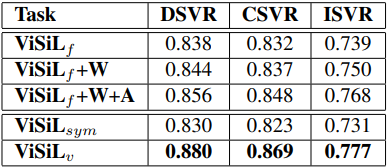
해당 논문은 FIVR-200K의 subset인 FIVR-5K를 처음으로 사용하고 이를 이용해 각 모듈 별로 ablation study를 진행하였습니다. f 는 frame-to-frame similarity를 의미하고 v는 video-to-video similarity 도 사용해 refine 한 것을 의미합니다. 또한 sym은 video-to-video similarity 도 사용할 때 CS 대신 SCS를 사용한 것을 의미합니다.
- Near-duplicate video retrieval
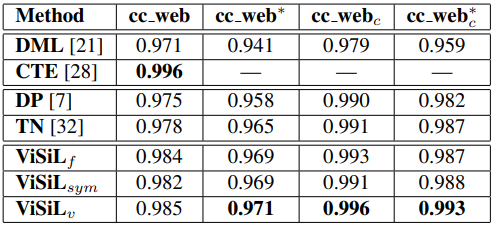
아주 유사한 video 끼리 묶여있는 데이터 셋인 CC_WEB_VIDEO의 여러 버전으로 mAP를 측정한 결과 입니다. ViSiL이 거의 수렴되있는 성능들에서도 좀 더 높은 값을 나타낸 것을 확인할 수 있습니다.
- Fine-grained incident, Event, Action video retrieval
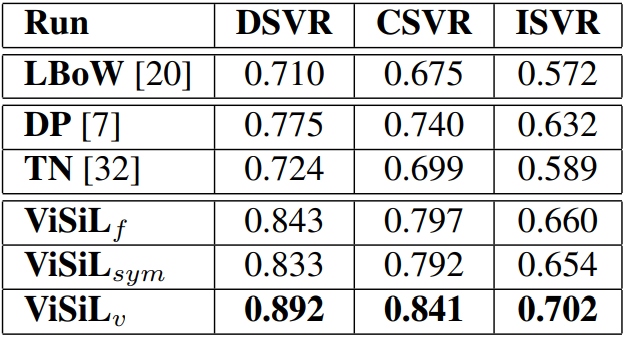

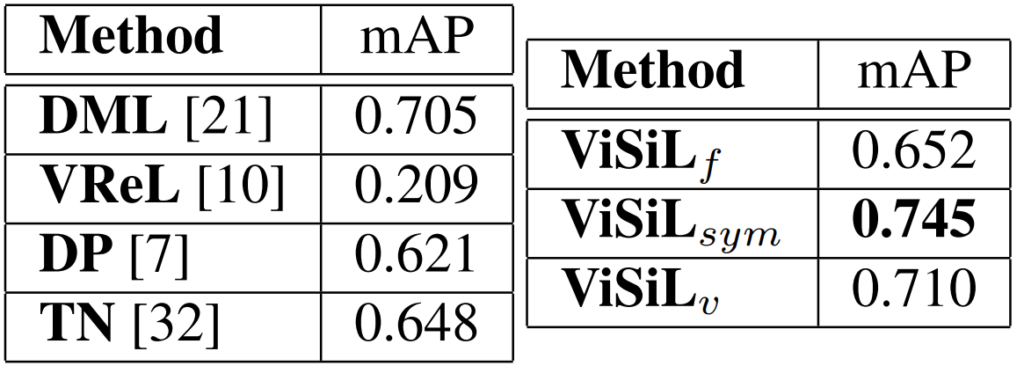
Table 3, 4, 5는 각각 Fine-grained incident, Event, Action video retrieval에 대해 mAP로 측정한 결과 입니다. 여러 데이터셋에서 ViSiL이 좋은 성능을 보이는 것을 확인할 수 있습니다.
4. Reference
[1] https://arxiv.org/pdf/1908.07410.pdf