이번주차에서는 Data augmentation에 대해서 다루어보겠습니다.
Data augmentation을 통해 엄청난 성능의 향상 효과를 가져오기는 사실상 힘들지만, 그래도 어느정도 robust성을 향상시키는데 도움을 줄 수 있습니다. 특히나 training image에 noise(회전, 블러, 안개 등…)가 많이 있는 경우에 적용하면 효과적일 수 있습니다.

해당 사진은 Dacon training set에 있던 사진중 일부입니다. 일부 training data의 사진이 90도 회전되어 있었습니다. 또한 일부 training data에는 모자이크, 블러 처리가 된 부분이 있었습니다. 이뿐만 아니라 다양한 scale에서의 robustness를 보장하기 위해선 data augmentation이 필요합니다.
제가 소개할 방법은 파이토치 라이브러리중 하나인 albumentations 입니다. 이미 자세히 알고 계신분들은 뒤로가기를 누르셔도 좋습니다.
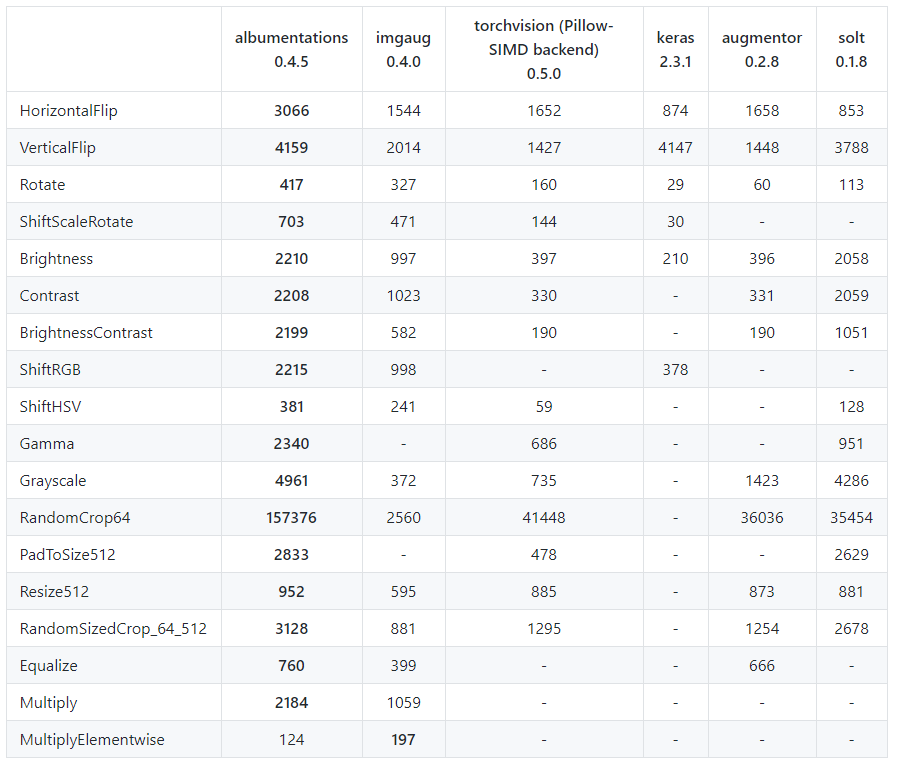
“위의 표는 ImageNet의 validation set 2000장에 대해 Intel Xeon Platinum 8168 CPU로 test한 결과이며 표의 값은 single core에서 초당 처리되는 image의 수를 나타내고 있습니다. 거의 모든 transform에서 많게는 2배 이상 빠른 처리 속도를 보여주고 있습니다.”
그럼 이제 사용법을 알아봅시다.
해당 링크는 튜토리얼 노트북입니다. 직접 시현해보고 싶으신분들은 참고하시면 좋을거 같아서 가지고 왔습니다.
Data augmentation에 대해 무지했었는데, 이번에 데이콘을 하며 data augmentation을 적용하기 위해 구글링을 해봤었습니다. 그래서 발견한게 torchvision이었기 때문에 torchvision이 가장흔한 data augmentation 라이브러리라고 가정하고 글을 작성하겠습니다.
가장흔한? torchvision에서 제공하는 transform 함수를 이용하면 아래 코드와 같이 간단하게 data augmentation을 구현할 수 있습니다. 이에 익숙하신 분들은 albumentations 을 쉽게 사용하실 수 있으실 겁니다. 그 이유는 아래의 코드 예시에서 찾을 수 있습니다.
토치비전을 이용한 data augmentation
torchvision_transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
위와 같은 data augmentation을 albumentations로 대체한 코드
albumentations_transform = albumentations.Compose([
albumentations.Resize(256, 256),
albumentations.RandomCrop(224, 224),
albumentations.HorizontalFlip(), # Same with transforms.RandomHorizontalFlip()
albumentations.pytorch.transforms.ToTensor()
])거의 비슷한 방식으로 사용되는것을 볼 수 있고 torchvision보다 더 많은 기능을 가지고 있습니다. 속도또한 수배에서 30배 가량 빠르다고 하니 albumentations 라이브러리를 사용하는 것은 꽤나 많은 이점이 있는거 같습니다.
다음으로는 실제 데이콘 작업을 할때, 적용했던 data augmentation코드를 보여드리겠습니다. training data에 대해서 resize와 randomcrop을 적용하였고, test data에 대해서는 resize와 centre crop을 적용했습니다. 이후 다양한 조건에 대해 학습하기 위해 Oneof 라는 함수를 사용하였습니다.
if args.mode == ‘train’:
transform = albumentations.Compose([
albumentations.Resize(args.img_w, args.img_h),
albumentations.RandomCrop(args.crop_w, args.crop_h),
albumentations.OneOf([
albumentations.HorizontalFlip(p=1),
albumentations.RandomRotate90(p=1),
albumentations.VerticalFlip(p=1)
], p=1),
albumentations.OneOf([
albumentations.MotionBlur(p=1),
albumentations.OpticalDistortion(p=1),
albumentations.GaussNoise(p=1)
], p=1),
albumentations.pytorch.ToTensor()
])
elif args.mode == ‘submit’:
transform = albumentations.Compose( albumentations.Resize(args.img_w, args.img_h), albumentations.Centercrop(args.crop_w, args.crop_h), albumentations.pytorch.ToTensor() )
mode가 training에서 Compose 로 묶어져있는 부분은 위의 예시와 동일합니다. 그렇다면 OneOf함수는 어떠한 역할을 할까요?
해당 코드에서 OneOf는 리스트로 입력을 받습니다. 그 입력값은 […, p=1]와 같은 형태를 띕니다. 이는 p의 확률로 … 안에 있는 조건들 중 한개를 수행하는 것을 의미합니다. 즉 위의 코드에서는 resize와 randomcrop을 한 후에 100%의 확률로 HorizontalFlip, RandomRotate90, VerticalFlip 중 1개를 수행합니다. 이 후, 다시 100%의 확률로 MotionBlur, OpticalDistortion, GaussNoise을 수행합니다.
생각보다 내용이 쉬워서 글이 짧게 마무리가 되었네요. 도움되신 분들이 있었으면 좋겠습니다. 다음주 x-review부터는 3D pose estimation을 위한 커리큘럼을 따라갈 생각입니다. 첫 주제가 뭐가 될지는 아직 모르겠네요.
좋은 글 감사합니다.
다른 data augmentation library들과 비교한 table을 보니 albumentations library가 상당히 매력적으로 다가오는군요.
해당 library가 일반적으로 자주 쓰이는 torchvision보다 좋길래 출처가 서로 다른 library인 줄 알았으나 albumentations도 pytorch에서 제공한다고 적혀있어서 질문드립니다.
해당 library가 torchvision보다 더 빠르다는 강점이 존재한다면 왜 아직까지 pytorch에서는 torchvision의 data augmentation을 제공하는 걸까요..? 제 개인적인 생각엔 albumentations 라이브러리에서는 없는, torchvision data augmentation만의 강점이 있을 것이라고 생각이 드는데 혹시 아시는게 있으실까요?
“albumentations도 pytorch에서 제공한다고 적혀있어서 질문드립니다.” 이부분에 대해서는 제가 잘못적은것 같습니다. 아마도 torchvision보다 albumentations 라이브러리가 좀 더 최신 라이브러리라서 그런거지 않을까 싶습니다.
튜토리얼 노트북까지 만드시다니 정말 대단합니다.
튜토리얼 노트북은 제가 직접 작성한 노트북이 아닙니다.
실제로 적용한 후, 성능적인 면에서 torchvision과 비교한 자료는 따로 없을 까요?
++ ‘제가 소개할 방법은 파이토치 라이브러리 중 하나인 albumentations 입니다. 이미 자세히 알고 계신분들은 뒤로가기를 누르셔도 좋습니다.’ 파이토치 라이브러리가 맞는지 확인이 필요 할 것 같습니다.
참고
https://www.mdpi.com/2078-2489/11/2/125
https://hoya012.github.io/blog/albumentation_tutorial/
속도를 제외한 성능적인 면은 논문에 실려있지 않았습니다. interpolation 하는 방식에 있어서 차이가 있어서 어느정도의 성능 차이가 날지는 모르겠습니다. 저자가 강조하는 주된 contribution은 속도와 기능의 다양성에 있었습니다. 정확한건 실험을 해봐야 알 수 있겠지만, Pytorch torchvision과의 성능차이는 dataset마다 다르고, 미미한 수준이지 않을까 싶습니다.