Chengxu Zhuang Tianwei She Alex Andonian Max Sobol Mark Daniel Yamins
Stanford University MIT
Introduction
1.비디오의 temporal sequence엔 (그것이 무질서한 형태로 존재했을 대 보다 더 풍부한)중요한 실제 세계에 관한 움직임,이벤트 정보가 들어있다 ->sequence가 중요하다
2.예를 들어,물체나 동인(agent)이 움직이고 서로 상호작용할 때,그들은 시각적 변화(그들의 시각과 강하게 연관되어 있는 물체 범주, 기하학적 모양, 질감, 질량, 변형성, 움직임을 포함한 물리적 정체성 경향, 그리고 많은 다른 특성들)의 특징적인 패턴을 낳는다.->sequence가 중요한 예시
3.따라서 그것(보편적으로 사용가능한 내추럴한 비디오는 정적,동적인 visual representation의 비지도 학습을 위한 강력한 signal의 역할을 할 수있다.)은 매력적인 가설이다.
4.그러나 (라벨이 없는 )비디오 데이터를 소비하여 (유용한 특성) 표현을 학습할 수 있는 견고한 신경망에서 이 가설을 구현하는 것은 어려웠으며, 특히 실제 적용의 맥락에서 더욱 그러했다.
5.그러나 아마도 비지도 비디오 학습을 진척시키는데 있어서 가장 큰 어려움은, 비지도 학습이 하나의 정적 이미지의 경우에도 만만치 않기때문이다.
6.심지어 하나의 정적인 이미지들에 대해서도,표현력(지도 비지도 학습에 의한 feature) 차이는 상당하다
7.그러나 최근의 deep visual embedding을 동반한 학습의 진보는 지도학습에 필적하는 비지도 학습 표현을 생산하기 시작했다.
8.이러한 방법은 데이터 분리 및 클러스터링에 대한 단순하지만 분명한 경험적 접근성을 활용하여 반복적으로 feature representations을 처리함으로써 미묘한 자연 이미지 통계를 더욱 잘 포착할 수 있다.->?약갼의 이해 더 필요
9.결과적으로 이제는 뛰어난 비지도학습기반 deep convolutional network을 얻는것이 가능하다.
10.더불어,지도 학습기반 video classification,action recognition and video captioning 에서의 work들은 새로운 조합(2d 3d)의 구조를 제안해왔고 그것들은 점점 video feature extraction에 잘 들어맞는다.
11.In this work,우리는 the idea of deep unsupervised embeddings 가 비디오로 부터 feature를 학습하는데 어떻게 쓰일 수 있는지 말한다.Video Instance Embedding (VIE)framework를 소개하면서
12.VIE에서,비디오들은 (유사한 비디오가 수집되고 다른 비디오가 분리될 수 있도록 임베디드 비디오 인스턴스를 최적으로 배포하도록 매개 변수를 조정된)deep neural network에 의해 compact latent space 로 투영된다.
13.우리는 발견했다 VIE 는 (Kinetics datasets의 action recognition 뿐만 아니라 ImageNet datasets의 object classification 전이학습을 위한 )powerful representation을 학습한다.
14.더욱이,직접적으로 비교가능한 이전 방법들에 비해 VIE는 SOTA에서 성능을 상당히 향상시켰다.
15.우리는 비지도 학습 VIE loss function의 몇몇의 가능성 을 평가했다.VIE loss function이 video context에서 최고로 효율적인 것을 밝히면서
16.우리는 또한 몇몇의 neural network embedding and frame sampling
architectures을 실험하며 different temporal sampling 전략은 서로 다른 temporal 샘플링 통계가 서로 다른 transfer tasks에 더 적절한 방법이며, 두 경로의 정적 샘플링 아키텍처가 최적의 방법임을 알아냈다.
17.마지막으로,우리는 모델이 어떻게 작동하는지 직관적으로 보여주는 learned representation에 대한 분석과 주요 구조 선택의 중요성을 보여주는 일련의 절제(ablation) 연구를 제시한다.
Methods
VIE Embedding framework
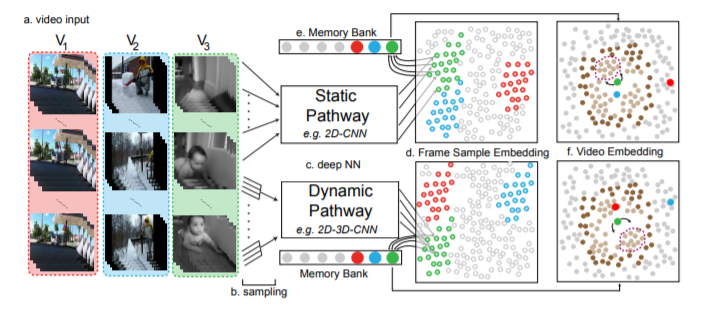
1.비디오로부터 비지도 학습의 일반적인 문제는 입력 비디오(V = {vi|i = 1, 2, ..N})로부터 파라미터화된 함수 φθ(·)를 학습하는 것으로 공식화될 수 있다. 이때 (vi=a sequence of frames {(fi,1), (fi,2), …, (fi,mi)})
2.우리의 전반적인 접근 방식은 비디오 {vi}을(를) D-dimension 유닛 영역SD = {x ∈ RD+1 with ||x||22 = 1}에 feature 벡터 E = {ei}(으)로 포함하려고 함
3.이 임베딩은 신경망 φθ : vi→ SD,가중치 파라미터 θ에 의해 실현되고 ,입력으로 sequence of frames f = {f1, f2, …, fL}을 받고 출력으로 e = φθ(f) ∈ SD를 낸다.
4.비록 한 비디오의 프레임 수는 임의적이고 잠재적으로 클 수 있지만, L은 대부분의 deep neural networks를 위해 고정되어야 한다.
5.따라서 단일 inference pass에 대한 입력 f는 프레임 샘플링 전략 ρ에 따라 선택한 v의 프레임 부분 집합, 즉 ρ(v)에서 추출한 모든 샘플에 대해 v’⊂ v for all samples v’ drawn from ρ(v)와 같은 임의의 변수 함수로 제한된다.
6.그런 다음 ρ에 따라 비디오 v에 대한 관련 VIE(Video Instance Embedding) e를 ρ에 따른 e의 표준(벡터 값) 기대값으로 정의한다.
이 비디오 리트리벌은 얼마만큼의 텀을 보조하며, 그에 관한 결과가 없는것 같습니다 성능에 관한 리포팅이 궁금합니다
해당 내용 보충해서 추가작성하도록 하겠습니다!