해당 리뷰는 현재 Image Classification task에서 SOTA를 달성한 ViT를 이해와 attention에 대한 이해, ViT를 보고 타 task와 vision task의 접목이 연구 방향성과 결과에 큰 영향을 준다는 것을 보고 미뤄두었던 NLP 공부를 하기위해 리뷰를 하였습니다. (ViT는 NLP의 큰 획을 그은 Transformer 방법론을 vision task에 접목한 방법론이며, 최대한 Transformer 방법론을 벗어나지 않도록 적용하였다고 합니다.)
Natural Language Processing
NLP는 인간의 언어 형상을 컴퓨터와 같은 기계를 이용해서 모사 할 수 있도록 연구하고 이를 구현하는 분야입니다. 인간의 언어는 어절의 최소 의미 단위인 형태소로 나눌 수 있으며, 각각의 형태소는 서로 연속적인 연관성을 가진 sequence data로 기존 Neural Network나 기계 학습 방법들로는 모든 규칙성을 가진 모델링 하기 어려웠습니다. 하지만 이전 정보를 기억하면 학습 하는 순환 신경망 계열의 딥러닝 모델이 등장하면서, NLP 연구 분야의 도약을 가져왔습니다.
우선 순환 신경망 계열의 딥러닝 모델의 근간이 되는 RNN을 먼저 소개하도록 하겠습니다.
Recurrent Neural Network (RNN)
RNN, 순환신경망은 시퀀스한 데이터를 모델링 하기 위한 모델입니다. RNN은 사람이 문장을 말하면서 이전에 말한 문장들을 기억하며 다음 문장을 말하는 것과 같이 이전의 정보를 ‘기억'(hidden stat, h) 하는 것을 모사하는 방법을 사용합니다. 이는 Fig 0 오른쪽 그림과 같은 형태를 취합니다. 이를 간략하게 표현하면 왼쪽 그림과 같은 구조가 되며, 이전 정보를 순환하며 사용하여 순환 신경망으로 불리웁니다.
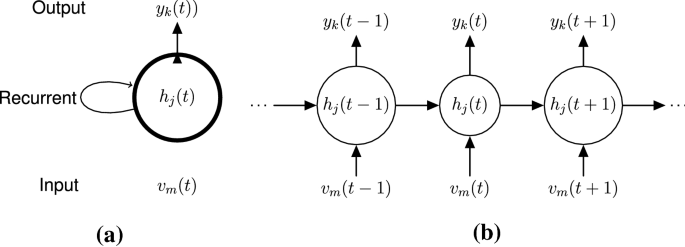
이전의 정보를 기억함으로써, 연속적인 데이터의 연속성에 대해 학습이 가능하게 되었습니다. 하지만 NLP에서는 짧은 문장 뿐만이 아니라 문장들로 구성된 글에 대해서도 성과를 얻고자 했습니다. 그러나 RNN은 입력되는 값의 길이가 길어지면 길어질 수록 역전파에서의 미분값이 작아지는 Gradient Vanishing 문제를 겪게 되었습니다. 이를 해결하고자 제안된 방법이 LSTM입니다.
Long-Short Term Memory(LSTM)

LSTM에 대해 말씀드리기에 앞서 RNN의 hidden stat의 구조(Fig 1, 왼쪽)에 대해 이야기하고 넘어가도록 하겠습니다.
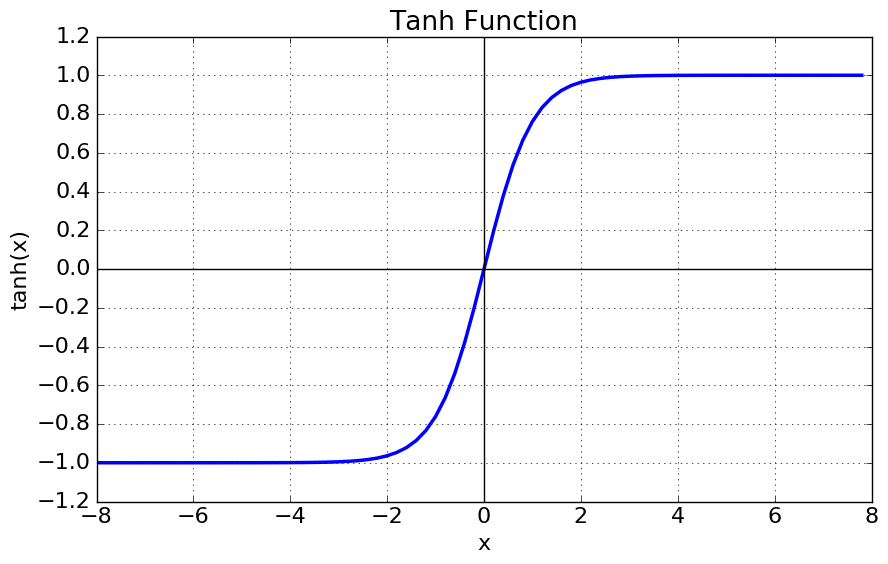
RNN의 hidden stat은 이전의 정보와 현재 입력값을 각각 weight를 곱합 후, tanh를 activation function 사용하여 비선형을 준 후, 다음 정보 값을 예측하는 방법을 사용합니다.
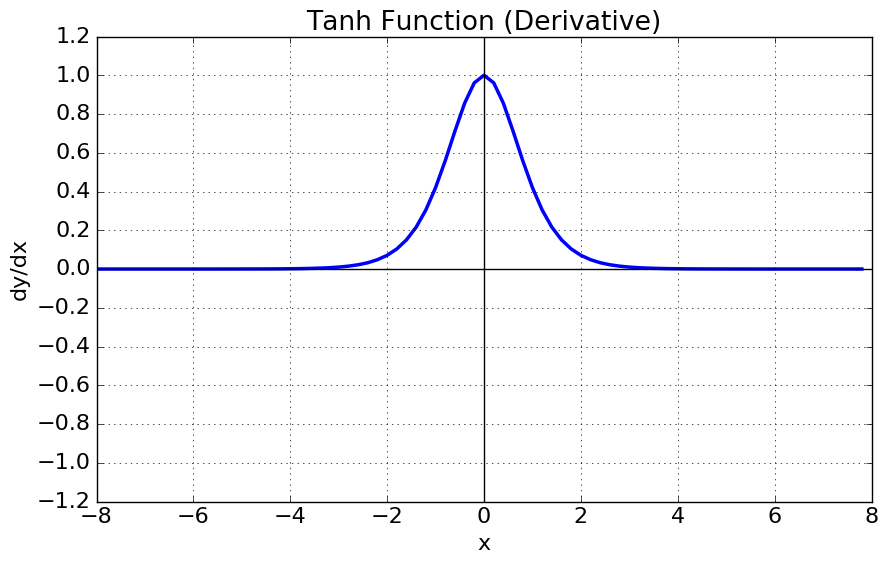
짧은 문장을 가진다면 문제가 발생하지 않겠지만, 문장이 길어질 수 록 gradient가 손실되거나 지그재그로 분산되는 현상이 발생합니다. 이에 대한 원인은 tanh 특성과 역전파시 chain rule로 생성되는 값이 층이 깊어질 수 록 변화량이 0에 가까워지는 형상이 발생하면서 발생합니다.
(tanh 특성은 Fig3-1,2를 보면 쉽게 이해 할 수 있습니다. 만약 |x|값이 일정값 이상 크다면, tanh의 미분 값이 소실되는 것을 확인 할 수 있습니다.
++ (이후 RNN과 LSTM의 확장된 버전에서는 tanh이 아닌 ReLU variants를 사용함으로써 activation function에서 발생하는 문제를 해결합니다.) )
LSTM은 기존 RNN의 오래된 기억들의(층이 깊어져 발생하는) gradient vanishing 문제를 해결하기위해 cell-state를 추가한 구조입니다. 사람이 오랜 시간 기억을 하기위해 이전의 기억 일부를 잊고, 현재의 정보를 기억함으로써, 이전의 중요한 기억들을 오래 기억하는 방법을 모사하여 방법론을 적용하였습니다. 즉 cell-state는 ‘과거 정보를 잊기’ 위한 forget gate와 ‘현재 정보를 기억’하기 위한 input gate로 구성함으로써 오래된 주요 기억을 오랫동안 기억 할 수 있게됩니다. 보다 자세한 내용은 LSTM 쉽게 이해하기 – 허민석 (Youtube) 을 참고 하시기 바랍니다.
Sequence-to-Sequence(seq2seq)
앞서 설명한 RNN과 LSTM은 고정된 입력값 크기와 입력값 크기와 동일한 출력값을 가져하는 제약과 cell-state에도 불구하고 순환 신경망의 고질적인 문제인 gradient vanishing 문제가 여전히 남아있었습니다.
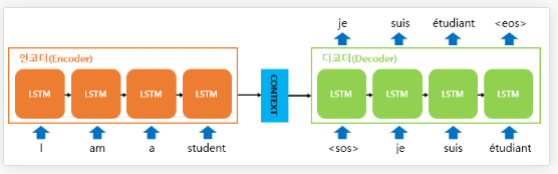
이를 해결하기 위해 seq2seq는 순차적으로 입력된 문장을 압축하여(임베딩하여) 하나의 벡터(Context Vector)로 만드는 Encoder와 임베딩된 벡터를 추론할 값으로 출력하는 Decoder로 만드면서 입력 크기와 출력 크기가 다른 문제를 해결합니다. 자세한 내용은 딥 러닝을 이용한 자연어 처리 입문 – Seq2Seq을 참고하시기 바랍니다.
Seq2Seq는 vision task에서 빗대어 영상을 하나의 vector로 표현하는 global descriptor와 유사하며, 시퀀스 데이터의 길이와 순서 상관없이 전체적인 맥락을 파악하는 Context Vector를 사용하는 방식이라고 이해할 수 있습니다. 하지만 Seq2Seq 모델은 LSTM의 한계와 마찬가지로 입력 문장이 매우 길면 효율적인 학습이 힘들어 집니다.
Attention Mechanism
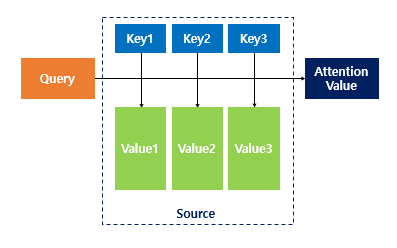
앞서 설명한 RNN에 기반한 Seq2Seq는 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니 정보 손실이 발생하고, RNN 기반 방법론의 고질적인 문제인 Vanishing gradient 문제가 발생합니다. 이러한 현상을 보정하기 위해 중요한 단어에 집중하여 Decoder에 전달하는 Attention Mechanism이 등장합니다.
Attention Mechanism의 핵심은 디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고해야하는 단점을 해결하고자, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보고자하는 것에 있습니다.
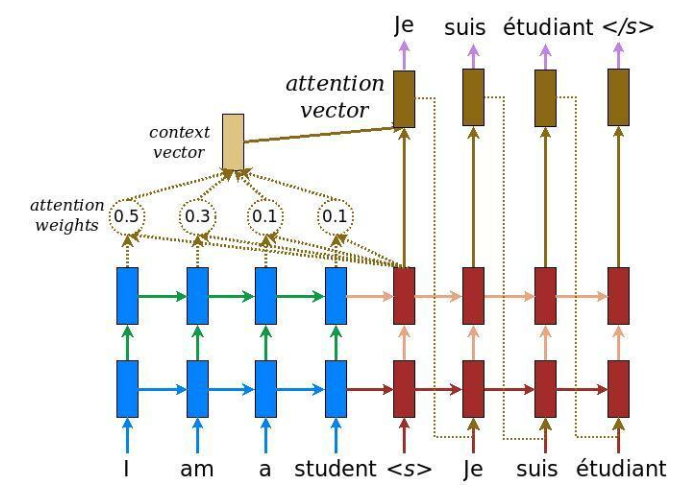
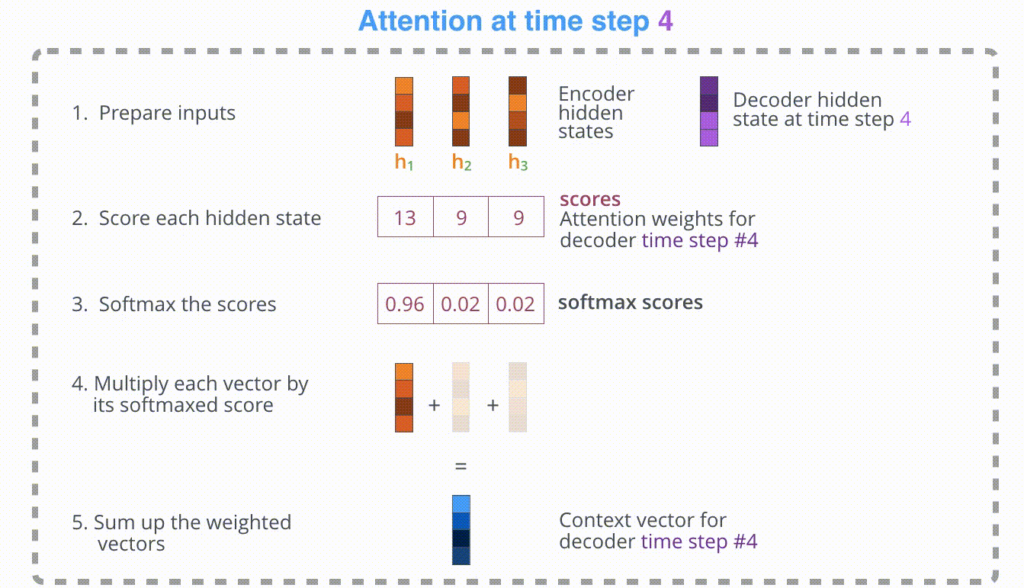
먼저 Encoder를 통해 1. hidden states들을 구한 후, Decoder의 h_t-1와 dot-product를 하여 2. attention score를 구합니다. 3. attention score을 Softmax에 태워 확률적 정보를 가진 score를 구합니다. 4. 각각 해당하는 encoder의 vector와 3의 score를 곱하여 weigh-sum을 합니다. 5. attention mechanism이 적용된 Context vector가 생성됩니다.
이를 통해 decoder가 값을 추론할 때, encoder의 전체 값을 참고하는 것이 아닌 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀더 집중해서 보게 됩니다.
참고자료