이번주차 x-review에서는 현재 진행중인 Dacon 관련 프로젝트에 관해서 설명드리겠습니다.
Dacon은 한국형 Kaggle로 다양한 챌린지를 진행하는데 그 중 하나가 이번에 참가중인 “랜드마크 분류 AI 경진대회” 입니다. 이와 비슷한 Landmark challenge는 구글에서도 2018년부터 2020년 까지 총 3회에 걸쳐서 진행을 했었습니다. 그 규모에 비하면 작지만, 국내의 landmark challenge중에선 상당히 큰 규모입니다. 챌린지는 한국형 랜드마크 데이터셋을 제공하고 test 데이터에 대한 prediction값을 예측하는 형태입니다. 즉, image recognition, classification문제 입니다.
1. 규칙
– 일일 제출 가능 회수 : 5회
- – Public Score: 전체 테스트 데이터 중 30%로 채점, 대회 기간 중 공개
- – Private Score: 나머지 테스트 데이터로 채점, 대회 종료 직후 공개
- – 참가자는 제출 창에서 자신이 최종적으로 채점 받고 싶은 파일을 선택해야 함.
- (최종 파일 미선택시 처음으로 제출한 파일로 자동 선택됨)
- – 대회 직후 공개되는 Private 랭킹은 최종 순위가 아니며 코드 검증 후 수상자가 결정됨
- – 제출 코드는 리더보드 점수를 복원할 수 있어야 함
- – 모든 코드는 오류 없이 실행되어야 함 (라이브러리 로딩 코드 포함)
- -외부데이터 사용불가
규칙들을 보면 구글랜드마크 챌린지와 상당히 유사합니다. 구글랜드마크 챌린지에 대한 글은 제가 저번주에 적은 x-review를 참고하시면 알 수 있습니다. 그 때 제 글에 private와 public score를 나누는 이유에 대한 질문이 달렸었는데, 곰곰히 생각해보니 submission을 통한 튜닝으로 성능을 향상시키는 cheating을 막기위함이라고 생각됩니다.
2. 데이터셋
- 1) train.zip(22GB) : 학습용 데이터셋 88,102장
- 2) test.zip(9.4GB) : 테스트용 데이터셋 37,964장
- 3) train.csv(2.5M) : 파일명과 랜드마크 아이디의 메타데이터
- 4) sample submission.csv
- – 제출용 csv 파일
- – conf 컬럼은 GAP 산정 시 정렬을 위한 값으로 모델의 확률 예측값(Softmax)
- 5) category.json
- – 클래스별 인덱스 값
데이터는 이와같이 주어지며 총 1049개의 class로 이루어져있습니다. 심사는 Global Average Precision 으로 이루어지며, 심사방식에 대한 코드는 데이콘측에서 제공을 하고 있습니다. 또한, dataloader를 코딩할때, 좀 더 편하도록 이미지 파일들의 경로가 담긴 csv 파일도 제공을 하고 있습니다.
구글랜드마크 챌린지의 데이터로 쓰인 GLDv1 과 GLDv2의 규모에 비하면 아주 작은 데이터 셋 입니다.
| 1위 | 0.99705 |
| 2위 | 0.99599 |
| 3위 | 0.99532 |
현재 1위팀은 99.705%를 달성 했으며, 12위 팀까지 99%대의 성능을 보이고있습니다. 이토록 성능이 상향평준화 된것은 데이터셋의 크기가 작고, 노이즈가 적기 때문이라고 생각합니다.
현재 저희팀에서는 0.98299로 30위를 기록하고 있습니다. 하지만, 이는 복잡한 파이프라인 구축없이 pre-trained된 resnext모델을 불러와 시험상 제출해본 score입니다. 해당 과정은 test data들을 분석하기 위해 진행했습니다. 예측한 test data들 중 confidence가 낮은 사진을 가지고 온 결과 아래와 유형들과 같습니다.

나무에 가려져서 건물이 거의 보이지 않습니다.

국민대학교로 라벨링 되었으나, 사실상 연못밖에 보이지 않습니다.

금나래아트홀 도서관으로 라벨링 되었으나, 계단밖에 보이지 않습니다. 또한, 모자이크된 부분이 있어서 이 또한 노이즈로 작용했을 것 입니다.

숲에 가려져셔 거의 보이지 않습니다.

사람이 봐도 어느 랜드마크인지 분간이 힘든 경우도 있었습니다.

위와 마찬가지로 나무에 가려져 보이지 않습니다. 대다수의 치명적인 노이즈는 나무에 의한 시야가림인거 같습니다.
데이터를 분석한 이후, pipeline을 대거 수정했습니다.
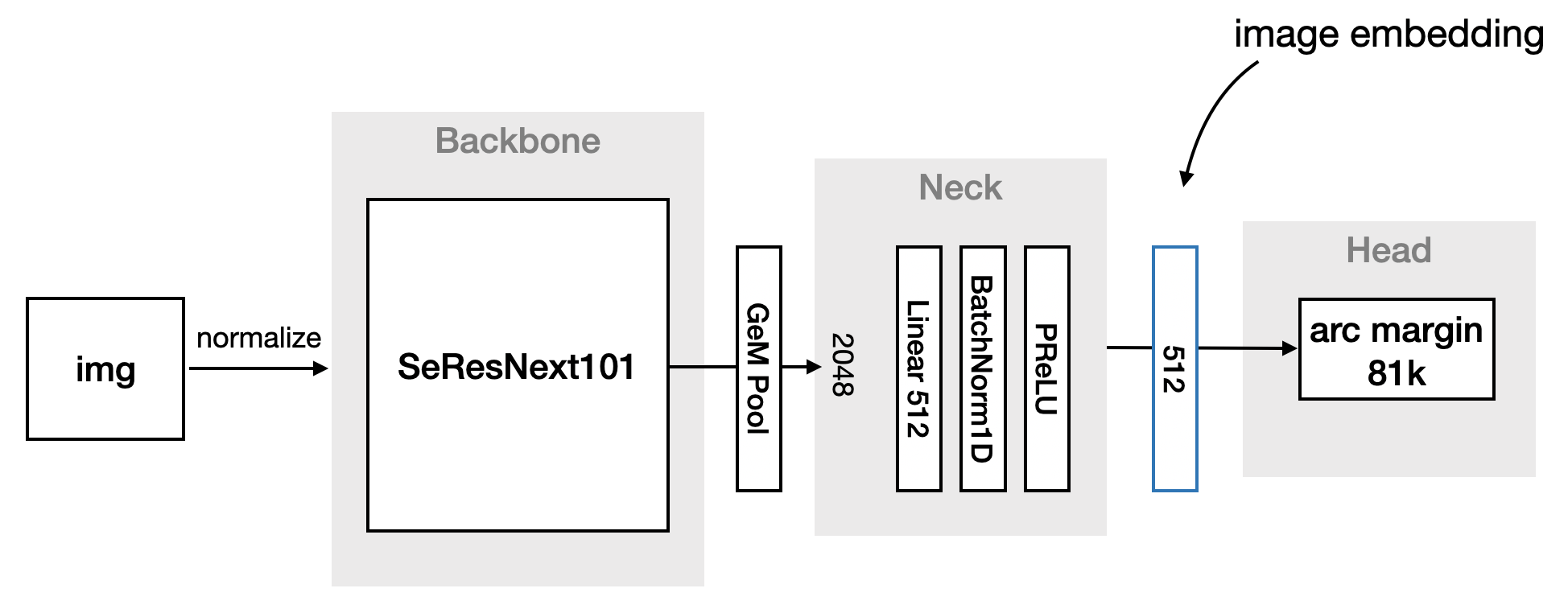
해당 그림이 저희가 구성한 pipeline입니다. 2020년 구글 랜드마크 챌린지의 1등팀의 파이프라인을 똑같이 구성했습니다.
그러나 구글 랜드마크 챌린지와 데이콘 챌린지는 비슷하지만 다른 부분들이 꽤나 존재합니다. 따라서 1등팀의 파이프라인을 따라한다고해도 좋은 결과가 보장되는 것은 아닙니다.
그렇다면, 어떠한 점들이 다를까요? 저희가 분석한 결과를 정리해 보았습니다.
- 데이터 셋의 차이: 2020 구글 랜드마크 챌린지에선 세상에서 가장큰 랜드마크 데이터인 GLDv2를 사용했습니다. GLDv2는 약 500만개의 이미지로 구성되어있으며 자세한 내용은 이전포스팅과 https://github.com/cvdfoundation/google-landmark를 참고하면 됩니다. 이중 clean된 데이터를 제공하여 그 데이터를 이용하여 챌린지를 진행했습니다. 그렇다고 하더라도 노이즈가 많이섞여있다보니 1등팀이 0.6598 의 성능을 내는데 불과했습니다. 즉, 훨씬 더 challenging한 대회였습니다. 이에 비해 데이콘에서 진행하는 대회는 수상권자들은 99.5%~100% 사이에 위치할 것으로 보입니다. 따라서 위에서 언급한 노이즈 데이터를 어떻게 처리하느냐가 관건이 될 것입니다.
“Google Landmarks Dataset v2 – A Large-Scale Benchmark for Instance-Level Recognition and Retrieval”
T. Weyand, A. Araujo, B. Cao, J. Sim
Proc. CVPR’20
- 데이터사용의 자유: 구글랜드마크 챌린지에서는 데이터사용이 자유로웠습니다. 그래서 상위권 랭커들의 방법론을보면 Non-landmark를 필터링 하기 위해 기존 GLDv1과 GLDv2를 동시에 사용하는 것을 볼 수 있었습니다. 그러나 데이콘에서는 외부데이터를 사용불가로 규정하고 있습니다.
- 이미지 사이즈의 차이: 구글 랜드마크 챌린지에서는 이미지의 사이즈가 제각각입니다. 다양한 aspect ratio를 가지고, 다양한 크기를 가집니다. 데이콘 데이터를 본격적으로 분석하기이전 구글랜드마크 챌린지 상위권 입상자들이 발표한 논문을 먼저읽었습니다. 그래서 데이콘도 당연히 이미지 사이즈가 다양할 것이라고 생각했습니다. 그러나 모든 이미지에 대해 max & min 과 average width & height를 구해본 결과 이미지 사이즈는 960×540으로 일정하였습니다. 아마 resize를 해준거 같은데, 이 과정에서 이미지가 일부 뭉개지거나 늘어난 경우도 있었습니다. 또한 회전된 이미지도 있었습니다.

- 클래스내의 이미지 수: 구글랜드마크 챌린지에서는 클래스내의 이미지의 숫자가 제각각 이었습니다. 따라서 3개이하의 class는 버리는 등 데이터 전처리 과정이 필요했습니다. 반면에 데이콘에서는 class마다의 이미지의 개수가 일정합니다.
이런 노이즈들에도 불구하고, 성능이 높게 나오는 이유는 몇몇 노이즈들을 제외하곤 상당히 유사한 형태를 띄고있습니다. 로드뷰에서 약간씩만의 변화를 줘서 수집한 데이터가 많은걸로 추정됩니다.
한 유저가 t-SNE를 이용하여 대회 데이터를 분석한 노트북을 공유했습니다.
https://dacon.io/competitions/official/235585/codeshare/1766?page=1&dtype=recent&ptype=pub
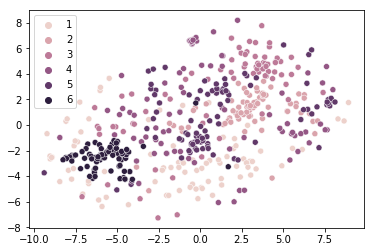
raw data를 KNN을 이용하여 군집화한 결과 입니다. 어느정도는 군집화가 이루어지는 것을 확인할 수 있습니다. validation 결과는 0.7617552954292084정도가 나왔습니다.
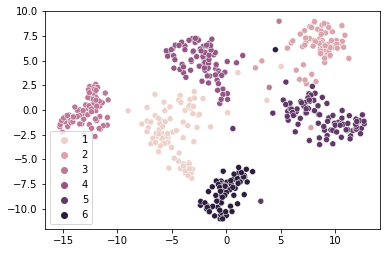
CNN을 타고 나온 global descriptor를 군집화한 모습입니다. 거의 완벽하게 군집이 이루어졌습니다. 이렇듯 각각의 클래스내에는 몇몇의 outlier를 제외하고는 상당히 유사한 이미지를 담고있습니다. 대부분의 class에서는 군집이 잘 이루어지지만, 일부 지역에서는 유사도가 떨어지는 현상이 있습니다. 해당 글을 공유한 사람이 광주광역시를 언급했는데 이는 분석이 필요해 보입니다.
일단 위에서 언급한 파이프라인을 그대로 활용할 생각입니다. 그리고 우승자팀이 했던 것처럼 7개의 backbone을 L2 norm을 적용한 후 concat하여 ensemble 기법을 활용해볼 생각입니다. 이 과정에서 쓰일 backbone들은 실험적으로 찾아나갈 생각입니다. 현재 전체적인 network를 완성하였고, 실험 단계에 있습니다. 이번 주말에 학습시켜둔 모델들을 저장하는 과정에서 overwriting이 발생하여, 코드를 수정하고 다시 처음부터 학습중입니다. 다행히도 GPU를 여러개 동시에 사용할 수 있는 환경이 구성되어 있어서 빠르게 실험을 진행할 수 있을거 같습니다. 10 epoch 까지의 실험을 기준으로 backbone을 선정할 생각입니다.
저는 이번대회를 연습하는 느낌으로 참가했습니다. 그래서 일부로 이런저런 시도를 하고 있습니다. 예를들어 굳이 parser를 안써도 될것을 사용하고, %(변수)로 프린팅 해도 될 것을 format 구문을 사용한다던지… save 파일을 실험조건별로 나누어서 저장한다던지… 등등 굳이 안해도 되지만 하면 편한 사소한 부분들을 채워나가고 있습니다. 또한, class와 def를 import해오고 여러가지 파일로 분할하는 프로젝트를 처음진행해보아 객체지향 프로그램이 왜 편리한지 이해하는데 상당히 큰 도움이 되었습니다. 모르는 부분이 있으면 우회하려 하지 않고, 조금씩 채워 나가는 것이 상당히 중요한 점 임을 깨달았습니다.
향후 목표로는 t-SNE를 학습해보고 일부 outlier가 많은 class를 분석해볼 생각입니다. 일부 실험을 마치고 backbone network를 선정한 후, ensemble기법을 구현해볼 생각입니다. cosine similarity를 이용하여 같은 클라스 내에 유사도가 높은 이미지들 끼리 연결하여 tree를 구성하고, tree와 연결되지 않는 이미지들을 non-landmark로 분류할 계획입니다.(다른 paper를 보고 영감을 얻었는데 데이터셋의 성향이 달라서 실제로 효과가 있을지 모르겠습니다.). 우선 여기까지를 목표로 하고 있습니다.
지금 1등은 어떤 방법론을 쓰고있는지 혹시 짐작이나 알고계신가요?
알고있다면 저희가 1등이겠지요?! ㅎㅎ 짐작하기로는 방법론적인 차이는 크게 없다고 생각합니다. 다만 저희가 사용하는 방법론에서는 local descriptor를 사용하고 있지 않습니다. 일단 global descriptor만을 사용하여 결과를 뽑아낸 후 local descriptor 사용도 검토해볼 생각이긴 합니다. 또한, backbone이나 네트워크도 약간 다를 수 있습니다. 저희팀에선 non-landmark를 구분하는 방법으로 cosine similarity를 사용 하였는데 1등팀은 어떤 방법을 사용하고 있을진 워낙 다양한 방법들이 있어서 정확히 알 수는 없습니다.
ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ
1등을 기원합니다
감사합니다
좋은 성적 거둡시다 화이팅
ㅋㅋㅋ화이팅
제 생각에도 Non-Randmark를 따로 분류하는 것이 해당 챌린지의 돌파구라고 생각합니다.
Knn과 cosine-similarity 그리고 tree를 구성 하여 분류하는 방법을 말씀하셨습니다.
tree를 이용한 방법론이 무엇인지 궁금합니다.
t-SNE 와 KNN은 일단 데이터의 경향성을 보기위해 사용한 방법입니다. cosine similarity 를 이용해서 tree? forest? 를 구성하는 방법은 전에 디스커션 했던 내용을 함축적으로 그렇게 언급했습니다. 같은 class내에 cosine similarity가 일정수준의 threshold(0.5정도)를 넘어가면matching count를 증가시키고 클래스 내에서 matching count가 가장 많은 이미지를 기준점으로 삼습니다. 그 기준점과 matching되는 이미지들을 연결하여 일종의 tree형태를 구성하고 연결된 이미지와도 matching되는 이미지들을 검색하여 2차적으로 한번더 연결을 합니다. 이렇게 구성된 tree와 연결되지 않는 이미지들을 non-landmark 이미지로 정의할 생각이었습니다.