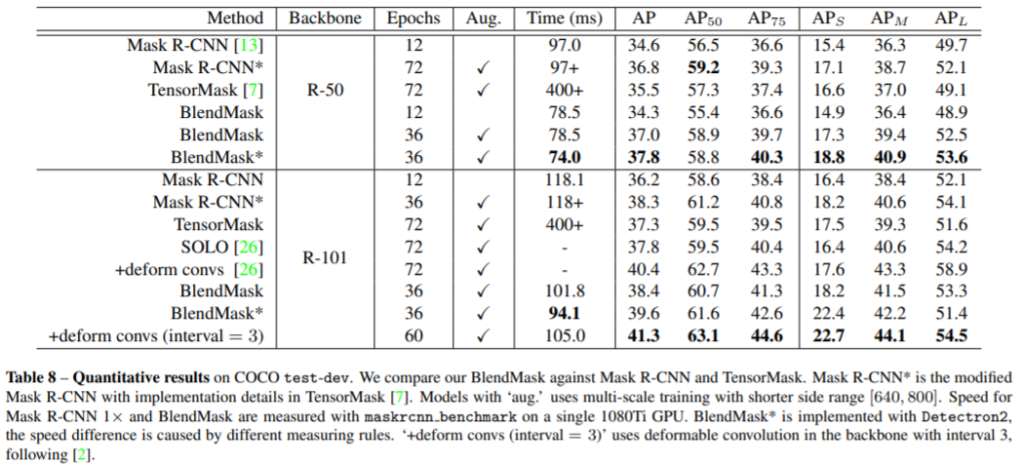
BlendMask는 빠른 segmentation을 가능하게 한 [ICCV2019]YOLACT 을 안다면 빠르게 이해할 수 있을 것이다. YOLACT 은 Real-time Instance Segmentation 즉, instance segmentation 문제를 real-time으로 해결하기 위한 논문이다. [설명 링크]를 참조할 수 있다. Abstract에서 BlendMask는 제안하는 방법론이 Mask R-CNN보다 outperforms을 보이며, 효율적이라 설명한다.
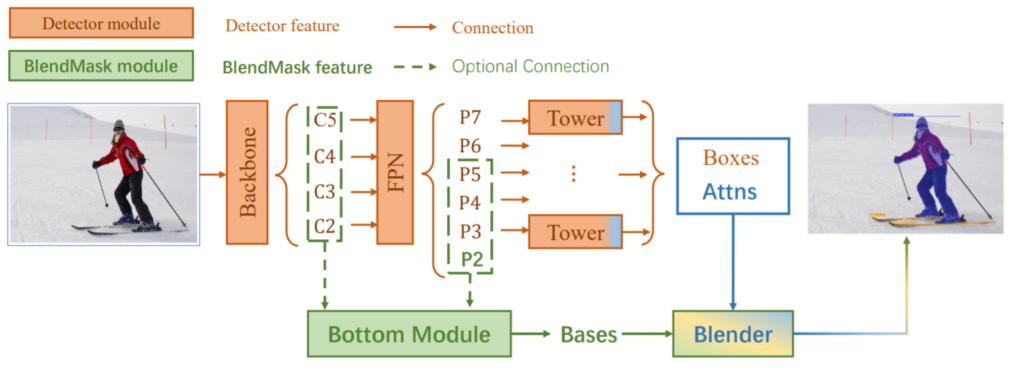
제안하는 BlendMask의 파이프라인은 detector network와 mask branch로 이루어 진다. 일반적인 two-stage 방법론들은 detector module과 segmentation 모델을 직렬적으로 사용하여 이미지 시프트와 같은 변동에도 일관성을 갖어야하는 classification 문제와 그와같은 변동을 잘 반영해야하는 location문제를 나누어 해결한다. 그러나 one-stage (YOLACT을 포함한) 방법들은 두 문제를 위의 pipline과 같이 병렬적으로 해결하기 위해 위와같이 두 파이프라인을 이용한다. 여기서 detector network로는 SOTA인 one-stage object detector인 FCOS와 유사하다고 하며, sota인 one-stage detector모델과의 통합능력 또한 장점으로 소개하였다.
BlendMask의 main이라 생각하는 mask branch는 또 다시 Bottom module, Top layer, Blender module 3개의 기능으로 나눌 수 있다. (그 중에서도 Blender module이 메인이라 한다.)

– Bottom module은 그림1에 나와있듯이 Bases를 생성하는데 이는 말 그대로 backbone model에서 추출한 feature와 같은 base의 역활을 한다.
– Top layer는 Detector module의 tower 뒷부분의 푸른 부분으로 attentions을 생성한다 (즉, Tower의 output은 Detector module에서 추출한 bounding box와 attentions(A)!)
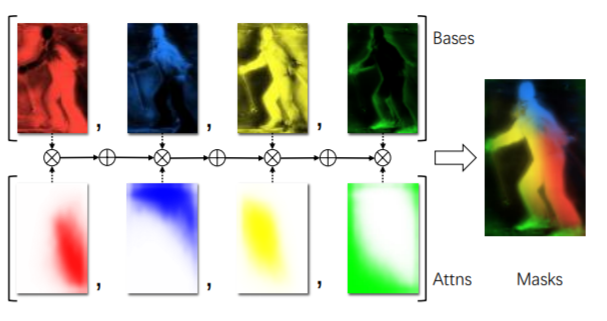
그림 2에서 확인 할 수 있듯이 base는 서로 다른 edge를 active(활성화라는 표현이 옳은지는 모르겠습니다만) 한 backbone feature와 같은 역활이고, attentions는 detector에서 추출한 box의 attention을 나타낸다. (그림의 컬러는 weight를 나타낸다고 한다.)
마지막으로 blender module은, attentions (A로 표기)와 bases(B로 표기), detector module의 box proposals (P로 표기)를 입력으로 하여 마스크를 생성한다. 마스크를 생성하는 방식은 다음과 같다.
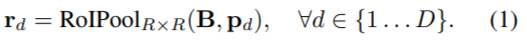
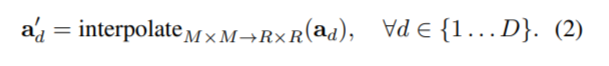
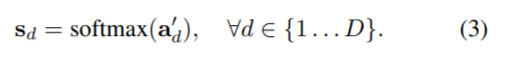
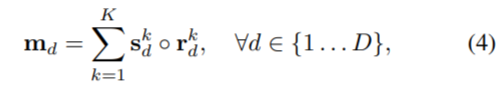
안녕하세요 글을 읽다 문득 예전부터 궁금했던 점이 있어 댓글 남깁니다.
본문 내용 중 “OLACT 은 Real-time Instance Segmentation 즉, instance segmentation 문제를 real-time으로 해결하기 위한 논문이다.”라는 내용이 있는데 여기서 Instance라는 단어에 대해 설명해주실 수 있나요?
여러 논문들 보면 가끔 한번씩 나오는 단어인데 우리가 흔히 알고있는 인스턴트 푸드처럼 그냥 쉽게 꺼내다가 쓰기 쉬운? 모델을 말하는건지… 컴퓨터비전 쪽에서 해당 단어를 어떻게 해석하고 받아들어야할지 헷갈리더군요.
혹시 제안된 mask branch는 따로 학습하지 않는 것으로 보이는데 맞게 이해한 것일까요? 만약 학습을 한다면 전체 network의 loss function을 설명해주실 수 있을까요?