이번주에 읽은 우울감(증) 과 관련된 2개의 논문입니다.
Depression Screening from Text message Reply Latency
2020년 나온 해당 논문은 문자메세지의 응답시간으로 만든 피처로 실제 우울감(증)을 예측할 수 있는지 연구한 논문입니다. 결론만 순전히 문자 메세지의 응답 시간만 사용했다고 볼 수 없어 조금 아쉬운 논문입니다.
지난번 리뷰에서와 마찬가지로 먼저 우울감(증)을 측정하기 위해서 해당 논문에서도 PHQ-9을 지표로 사용합니다. 일반적으로 PHQ-9의 설문조사 점수가 5점을 넘으면 약간의 우울감이 있다고 표기하는데, 해당 논문에서는 점수의 커트라인을 10점으로 우울한 사람과 그렇지 않은 사람으로 나누어 평가를 수행합니다.
해당 논문에서는 앞서 말한 기준으로 총 37명의 우울감이 있는 사람과 31명의 우울감이 없는 사람의 휴대폰 문자메세지 응답시간 정보를 통해서 우울감을 예측하는 모델을 설계합니다.
여기서 ‘문자메세지 응답시간’ 이란 단순히 어떤 메세지를 받는 시간부터 그 메세지에 대해서 실험자가 답장을 보내는 시간의 차이를 이야기하며, 초단위로 계산하여 2주간 수집된 해당 정보를 통해 피처를 생산하게 됩니다.
이렇게 수집된 문자메세지 응답시간 정보를 가지고 총 9개의 피처를 생산하는데, ‘최소/최대 응답시간(2)’, ‘10%, 25%, 50%, 75%, 90%(5)에 해당하는 응답시간(5)’ 이렇게 7개의 피처와 추가적으로 얼마나 많은 사람들과 문자메세지를 나눴는지(1), 얼마나 많은 응답을 남겼는지(1) 를 포함해 총 9개의 피처를 가지고 우울감을 예측합니다. 이때 수집된 데이터는 앞서 언급했지만 총 2주간의 데이터 입니다.
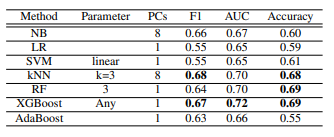
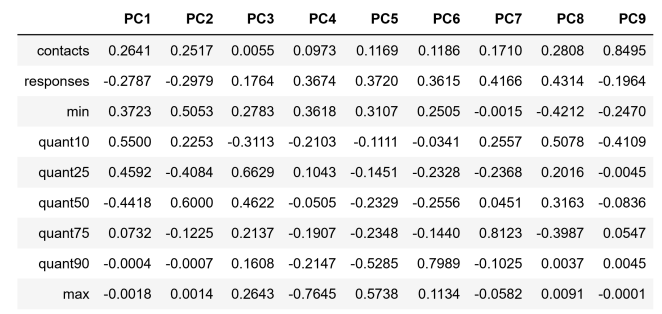
앞서 만든 피처를 가지고 다양한 분류 모델(SVM, kNN, AdaBoost 등등)을 사용하였으며, 결론적으로는 ‘XGBoost’가 가장 좋은 결과를 얻었다고 이야기 합니다. 그 이유로는 피처간의 갭이 크기 때문인데 아래 표를 보시면 max 값과 contacts의 값의 차이가 큰것을 확인할 수 있습니다.
XGBoost를 통해서 나타낸 결론은 다음과 같습니다.
결론적으로는 해당 논문에서는 10을 기준으로 높고, 낮음 즉 binary 문제로 우울감을 예측하였고, 앞서 설계한 피처들에 XGBoost를 사용하여 F1 score 0.67, AUC 0.72, Accuracy 0.69를 나타냈고 합니다.
Mobile Phone Sensor Correlates of Depressive Symptom Severity in Daily-Life Behavior: An Exploratory Study
해당 논문은 2015년 나와서 400회 이상 인용될 정도로 해당 분야에서는 상당히 많이 인용되는 논문입니다.
해당 논문에서는 ‘Purple Robot mobile App’ 을 통해서 사람들의 모바일 센서 정보를 취득합니다. 해당 논문에서는 크게 Location과 Usage 데이터를 통해서 사람들의 우울감을 예측하였습니다. Location에 주로 사용되는 GPS 정보는 5분 간격으로 취득하였고, Usage 정보는 스마트폰의 On/Off를 감지해서 데이터를 취득했다고 합니다.
Location
Location정보 활용을 위해서 GPS를 사용하였는데, 1km/h 변화량을 기준으로 사용자가 stationary state인지 transition state인지 판단하였다고 합니다. 또한 K-means Cluster를 통해서 실제 위치정보의 군집들을 만들어 장소를 구분하였는데, 이때 Cluster의 범위는 500M로 설정했다고 합니다.
Phone Usage
Phone Usage정보 활용을 위해서는 피 실험자의 스마트폰에서 Screen 사용 시간을 취득했는데, 단순한 확인(문자메세지나 간단한 앱알람 확인)을 위해서 사용되는 30초 이하의 시간들은 제거했다고 합니다.
Feature Extract
실제 앞에서 취득한 정보를 통해서 피처를 추출하는 부분입니다. 해당 부분은 예전에 리뷰를 진행한 2020년도 논문인 ‘Predicting depressive symptoms using smartphone data‘ 와 유사한 부분이 많습니다. 지금 리뷰중인 논문은 2015년도 논문이니까 다시 말하면 2020년에 작성된 논문에서 해당 논문의 상당부분을 인용했다고 볼 수 있습니다. 따라서 각 피처에 대한 설명은 따로 작성하지 않고 피처의 이름만 작성하겠습니다.
Location Feature
Location Variance, Number of Clusters, Entropy, Normalized Entropy, Home Stay, Circadian Movement, Transition Time, Total Distance
Phone Usage
Phone Usage Frequency – 하루동안 피실험자가 스마트폰을 얼마나 사용하는지(횟수)
Phone Usage Duration – 하루동안 피실험자가 스마트폰을 사용한 시간(초)
해당 피처들을 통해서 우울감을 예측하는 모델 설계를 수행합니다. 이때 모델은 직접 스코어를 예측하는 Score Estimation Model과 PHQ-9 점수 5점을 기준으로 우울감이 있는 사람과 없는 사람 이진 분류를 수행하는 Classification Model 두가지 방법으로 설계를 진행합니다.
Result
해당 실험에서는 약 2주간 40명의 피실험자를 대상으로 위에서 언급한 데이터를 수집하였고, 이때 50%이상 데이터가 손실된 경우 해당 피실험자의 데이터는 제거하였다고 합니다. 그래서 실제 40명 중 28명의 데이터만 사용할 수 있었고, 이때 14명은 우울감이 있는 피실험자, 나머지 14명은 우울감이 없는 피실험자 였다고 합니다.
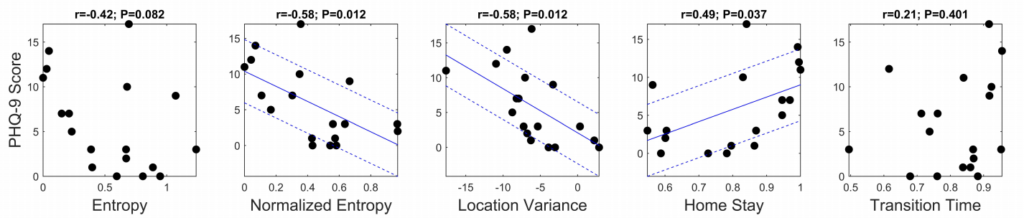
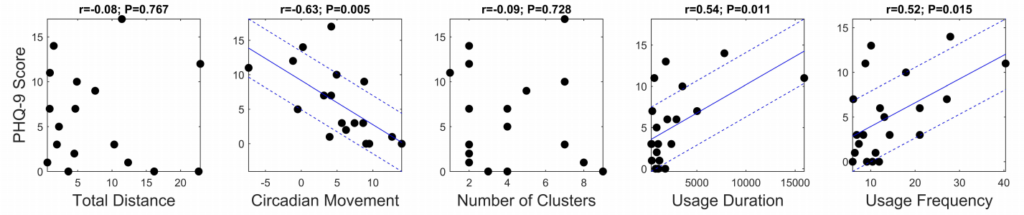
각 피처들과 PHQ-9 Score의 상관관계를 분석하면, Circadian movement, Normalized entropy, location variance에서 우울감과 강한 상관관계를 나타냈고, Phone Usage 피처 2개 모두에서도 의미있는 상관관계를 나타냈다고 합니다.
또 해당 피처들로 단순히 이진분류를 진행한 결과는 다음과 같다고 합니다.
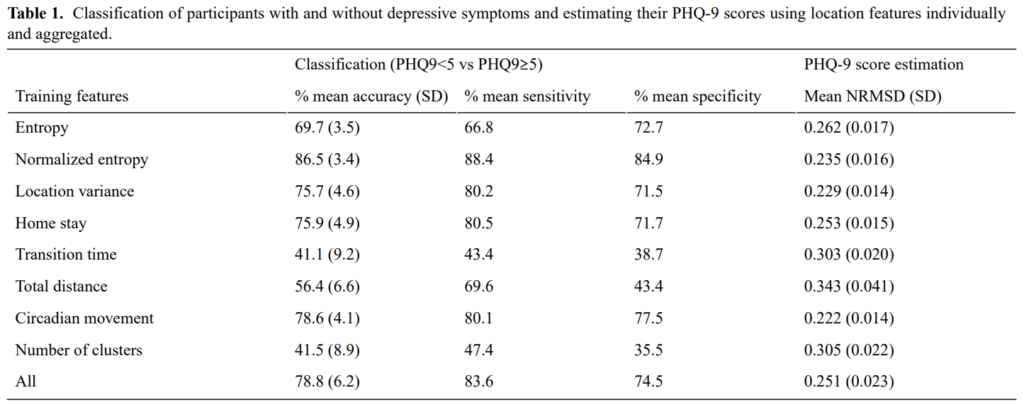

생각만큼 높은 정확도는 아니지만 그래도 각 피처들을 설계하고 각각에 대해서 유의미한 결과를 나타냈다는 점에서 IITP 과제를 진행하면서 참고할 논문인것 같다는 생각을 했습니다.
끝으로 해당 논문의 저자의 이력을 살펴보면 해당 과제를 수행하면서 해당 저자의 논문들을 한번 전체적으로 살펴볼 필요성이 있을것 같다고 생각했습니다.
두번째 언급한 논문과 관련해 작성된 한글의 기사(?) 도 함께 공유합니다.
데이터의 모집단이 너무 작다는 느낌은 들었지만 흥미로운 결과네요. 특히 기사내용중에서 기계가 사람 목소리에 실린 감정을 이해한다 라는 부분이 기억에 남습니다.
제 리뷰가 아닌 기사에 감명을 받으셨군요…