About CDVS
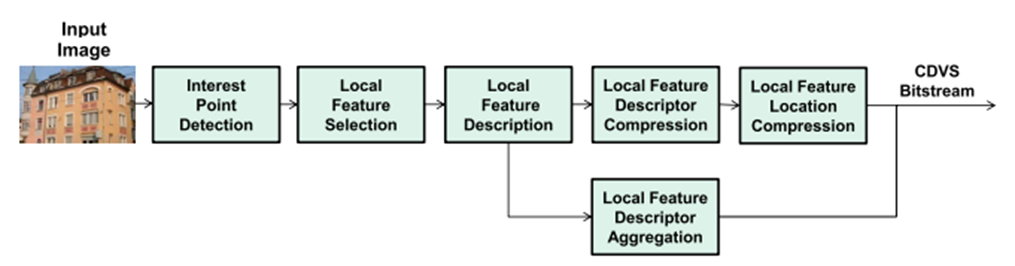

cdvs는 mpeg에서 표준화한 image feature descriptor입니다.
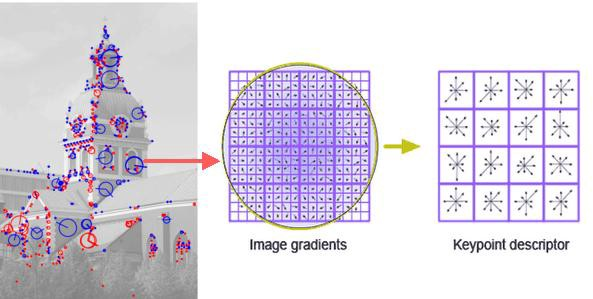
feature extraction에는 sift기술을 적용하여 descriptor를 추출하고 이후 압축기술로 encoding하여 최종 descriptor를 가지고 image retrieval을 진행합니다.
about CDVA
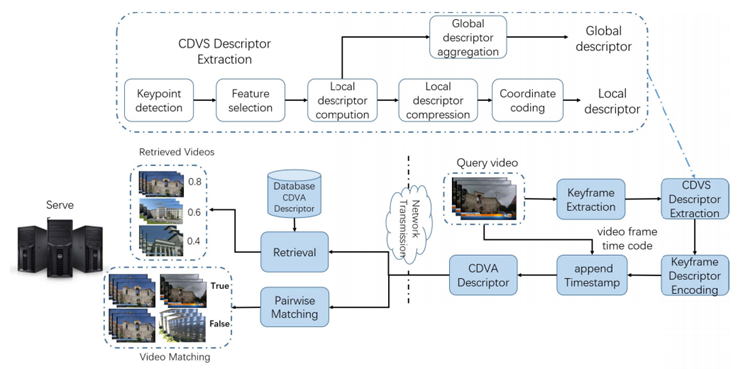
cdva는 mpeg에서 표준화 준비 중인 video feature descriptor입니다.
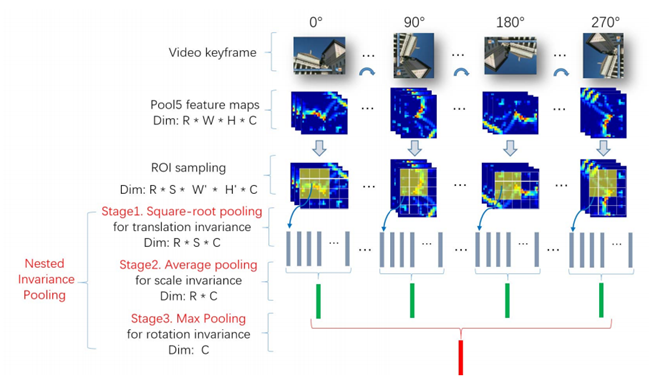
Cdva feature extraction에는 기존의 cdva descriptor와 함께 nip라는 cnn model을 deep feature descriptor로 사용하여 video retrieval을 진행합니다.
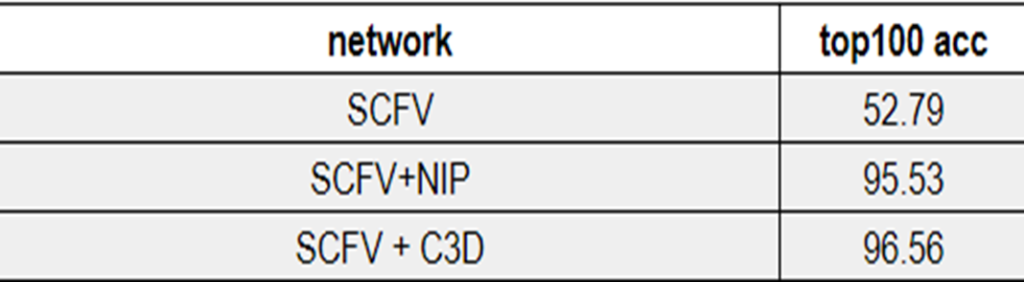
성능은 위와 같습니다.
압축으로 인한 정보량 손실이 있나요? 있다면 어떻게 되나요?