안녕하세요, 이번 x-review에서는 Dacon 랜드마크 챌린지와 비슷한 Google Landmark Challenge에서 1st place를 차지한 팀의 논문을 리뷰하겠습니다.
우선 1등팀은 2020년 Google Landmark Challenge를 통해 자신들의 Pipeline을 발전시키고, 콜라보를 위한 다양한 툴들을 사용하는 연습을 하는 과정으로 생각했습니다.
- Github: Versioning and code sharing
- Neptune: logging and visualisation
- Kaggle API: dataset upload/ download
- GCP: data storage
즉, 연습을 위해 Google storage에서 preprocessed된 data를 다운로드하고, Neptune으로 로그인한 Pytorch lightning으로 모델을 학습시키고, Git repo에 최신버전을 업데이트시켰습니다. 또한 inference kernel을 사용하기위한 weights를 Kaggle dataset에 업데이트 했습니다. 이러한 방법을 이용하여 콜라보환경에서 다양한 실험을 빠르게 할 수 있었습니다.
이런 내용들을 보면 수상자가 senior engineer이다 보니 확실히 최신 툴들에 좀 약한 모습을 보입니다. 그러나, Kaggle grandmaster인걸 보면 확실한 실력자임에는 의심의 여지가 없습니다.
그렇다면, 과연 수상자는 어떠한 방법론들을 사용했는지, 어떠한 실험들을 해보았는지 알아보는 시간을 가져보겠습니다.
본격적인 내용을 다루기 앞서, 이 글의 참고문헌을 밝힙니다.
https://www.kaggle.com/c/landmark-recognition-2020/discussion/187821
논문
https://arxiv.org/abs/2010.01650
데이터셋 설명 github
https://github.com/cvdfoundation/google-landmark
데이터셋 논문 (CVPR20)
https://arxiv.org/abs/2004.01804
"Google Landmarks Dataset v2 - A Large-Scale Benchmark for Instance-Level Recognition and Retrieval"
T. Weyand*, A. Araujo*, B. Cao, J. Sim
Proc. CVPR'20데이터셋
먼저, 데이터셋에 대한 소개입니다. 먼저 Google Landmark Dataset(GLD)는 버전이 v1과 v2로 나뉩니다. 오리지널 v2 데이터셋은 500만개의 image와 20만개가 넘는 class label로 구성되어 있습니다. 이 데이터셋은 현존하는 landmark dataset중에서 가장 큰 규모입니다. 해당 데이터셋은 Google Landmark Recognition과 Google Landmark Retrieval에 사용되었습니다. 이번 Google Landmark recognition challenge 2020에서는 v2중에서도 약 150만개의 clean된 data를 따로 제공하였습니다. 그 외의 350만개의 데이터와 v1데이터를 사용하는것은 자유입니다.
대회 규칙 및 스코어링 방식
Scoring방식은 GAP를 사용하며 이는 Dacon 랜드마크 챌린지에서와 같습니다. 2018~2019년 까지 진행된 챌린지에서는 그냥 submission을 업로드하면 채점되는 방식이였지만 2020년에는 좀 더 다른 방식을 채용했습니다. 그것은 바로 private leaderboard와 public leaderboard를 따로 나눈점입니다. 모든 참여자는 제출할 때, Kaggle notebook을 제출해야합니다. Kaggle 노트북을 직접 실행하고 12시간이내에 제출이 완료되야 점수를 인정받을 수 있습니다. 이 때, 서버 세션 만료시간이 9시간인 점을 고려하면 9시간 이내 제출이 완료되야합니다.
이렇게 채점된 score는 private한 score와 public score로 나뉘게 됩니다. public score는 대회가 종료되고 공개되며, test set을 약 34 :66 비율 정도로 나누어서 34프로에 대한 결과는 public score로 채점이되고 leaderboard 상에 참가자들 모두에게 공개됩니다. 그리고 나머지 66프로에 대해서는 대회 종료후 공개됩니다. 이 때문에, public leaderboard상에서 1등을 했던 참가자가 private 상에서는 2등으로 밀려나며 우승자가 바뀌게 되었습니다. 제가 이번에 하는 리뷰는 private score기준 1등 참가자의 후기 및 논문이고, 리뷰를 하는 과정에서 2등 참가자의 방법론 및 후기도 많이 참고하였습니다.
여기까지 데이터셋과 대회 규칙에 대한 설명을 마치었습니다. 그럼 이제 방법론적인 내용으로 넘어 가봅시다.
우승팀의 방법론
우승팀이 사용한 방법에 대해 우선 간단하게 알아보겠습니다. 해당팀은 arclossface loss를 기반으로 학습한 CNN모델을 이용하여 high dimensional feature space에 embedding했습니다. 이 후, visual similarity를 이용하여 이미지를 분류하였습니다. 그 다음, prediction을 re-rank 하고 noise를 cosine similarity를 기준으로 filter함으로써 성능을 향상 하였습니다. 또한, 이러한 과정에서 앙상블기법을 이용하여 7개의 모델에서 추출한 7개의 global descriptors를 사용하였고 local descriptor는 사용하지않았습니다.
해당팀은 이 밖에도 많은 시도를 해봤습니다. 그러나 좋은 결과를 가져오지 못했던 시도들은 아래와 같습니다.
What did not work
- Training together with gldv1
- Training together with gldv2 full
- Using index dataset 2019
- Using test set from 2019 stage1
- Hyperbolic image embeddings
- Superglue
- Deformable Grid
- 1000 other things
2등팀의 솔루션이 Google Landmark Retrieval 2020의 솔루션을 많이 참고하고, 4개의 backbone network와 superglue를 사용한 반면 우승팀의 솔루션은 superglue를 사용하지 않았고, 7개의 모델을 앙상블 했습니다. 그 밖에도 방법론적인면에서 많은 차이가 있었습니다.
Loss는 모두 같은 arcface loss를 사용하고 있었습니다. 최근 논문과 competiton을 서베이하며, Image recognition 문제를 해결할 때 1st~3nd place를 차지한 사람들의 대부분 Arcface loss를 사용했단걸 느꼈습니다. Arcface loss 를 학습하려 했었는데 기존에 사용하던 loss들에 대한 이해도 필요한거 같아서, 일단 다음으로 학습을 미루었습니다. 이번주에서는 전체적인 흐름에 좀 더 치중했습니다. 따라서 조만간 x-review에서 arcface loss를 포함한 loss들에 대해서 리뷰를 할 예정입니다.
이야기가 좀 다른 방향으로 갔는데 다시 본론으로 돌아와서 방법론적인 얘기를 더 자세히 해보겠습니다.
1. Validation strategy
우선 우승팀은 2019년 챌린지의 test set을 validation set으로 사용하였습니다. 해당 test set은 챌린지 이후 GT와 함께 공개되었습니다. 해당 데이터를 validation으로 선정한 이유는 non-landmark image를 많이 가지고 있기 때문입니다. 이후 실제로 평가를 받는 방식인 GAP metric을 실제처럼 post processing 과정에 구현하였습니다. train set은 test set에 있는 classes만을 포함하도록 필터링 하였습니다. GAP score는 softmax와 cosine similarity를 이용한 KNN을 이용하였습니다.
2. Modeling
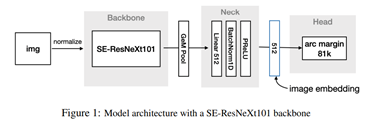
Implanced classes를 잘 구분하기 위해 우선 512차원의 feature space에 image들을 embedding 했습니다. 해당 과정에서는 CNN 백본 모델에 pooling layer를 이용하여 진행했습니다. 그 다음 이미지들간의 cosine similarity를 비교하여 matching을 진행했습니다. scale과 translation에 강인성을 부여하기 위해 다양한 scale과 aspect ratio, random crop을 적용하여 학습을 진행했습니다. Pre-trained 된 model에 image를 feed하기전에 normalize를 해주었습니다. 위의 해당 그림은 ResNext101를 이용하여 구현한 모델의 모습입니다.
3. Ensemble of Seven Models
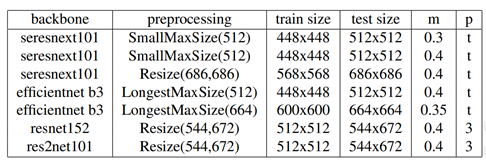
해당 7개의 backbone networks를 사용하였습니다. Preprocessing과정에서는 aspect ratio를 유지한채로 resize도 하고, fixe된 크기로 resize도 하는 등, diversity를 주었습니다. 여기서 m은 arc margin , p는 GeM 에서의 t(trainable) 혹은 fixed된 상수이며 hyperparameter입니다.
모든 모델을 동일한 방식으로 학습하였고, 그 방법은 다음과 같습니다. GLDv2 clean data 만으로 학습을 진행하였으며, 각각의 모델은 10 epochs만 학습을 진행하였습니다. 이때, 첫 번째 epoch를 warm-up epoch로, cosine annealing scheduler를 사용하였습니다. Optimizer는 SGD를 사용하였고, maximum learning rate=0.5, weight decay =0.0001 을 사용하였습니다. 또한, arcface loss를 loss term으로 사용하였습니다.
4. Ranking and re-ranking out-of-domain images
이전 랜드마크 챌린지들에서 ranking과 re-ranking 과정들이 높은 성능향상을 가지고 온걸 참고하여 해당 팀에서도 해당 과정을 중요하게 생각했습니다. 해당 과정을 설명하기 위해 논문에 실린 그림을 인용했습니다. 그리고 그림을 참고하며 설명을 이어나가보겠습니다.
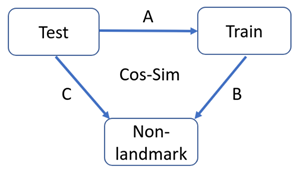
먼저 논문에 실린내용대로 notation을 정하겠습니다. Test set은 public 과 private submission 모두를 포함한 것을 test로 정하였으며, X라고 칭하겠습니다. Train은 clean data로 Y라고 하고, Non landmark images는 Z라고 부릅시다. 이때, Z는 2019년 챌린지에서 Non-landmark로 분류되었던 모든 데이터 입니다. 이때, 각 데이터들 사이의 cosine similarity를 구하는 과정을 각각 A, B, C라고 표기했습니다. 이제 notation을 명확히 하였으니, ranking 하는 과정에 대해서 알아봅시다. 해당 과정은 notation을 정확히 숙지하지 않으면 매우 헷갈릴 수 있습니다.
- X의 i번째 이미지와 Y 간의 A를 모두 계산합니다.
- Y와 Z간의 B를 모두 계산합니다. 이 때, Y에서의 각 이미지 중 Z와의 B결과 값 중 top 5 의 평균값을 구합니다. (이 과정을 통해 Y내에 Non landmark score를 정합니다.)
- A를 통해 구한 score에 B를 빼서 패널티를 줍니다.
- 3번에서 나온 값중 top3를 뽑은 다음 만약 label값이 같으면 더해줍니다. 이렇게 구한 score중 가장 높은 score를 prediction값으로 사용하고, 그 때의 score를 confidence로 계산합니다.
- 비슷하게 X와 Z사이 C연산을 통해 top 10의 평균 스코어를 구합니다. (이 과정을 통해 X내에 Non landmark score를 정합니다.)
- 3번 과정과 마찬가지로 5의 과정을 패널티로 사용합니다.
이 때 , 6번과정으로 구한 값을 패널티로 부여하는 방법은 computation time이 너무 증가하고, 3번 과정만 하는 것과 차이가 없어서 6번과정은 생략되었습니다.
이 후, X, Y, Z 간의 분산이 약간씩 다른점을 고려하여 quantile transformer를 적용했습니다. 이를 통해 다양한 scale의 input image에 좀 더 안정적인 결과를 내놓을 것으로 생각됩니다.
5. Ensembling
이제 학습된 모델들을 섞기 위해 l2 norm을 각각 적용하고, concatenate 했습니다. Test, Train, Non-landmark는 분산을 맞추기위해 quantile transform을 하고, 위에서 언급한 ranking기법을 사용하였습니다. 이 후 ensembing을 하였는데 그 기법은 보통 2가지가 있습니다.
- 간단히 concatenated embedding space를 사용하고, 처음부터 끝까지 larger embedding vetors에서 모든 과정을 시행
- 좀 더 robust한 방법으로는 A를 계산하고 각각의 모델로부터 top3를 구한다. 모든 모델로부터 구한 top3 score를 각각 더한다. 이 중에서 가장 높은 score를 pick한다.
우승팀의경우 2번의 경우 computation time이 너무 길어져서 1번을 사용하였습니다. 1번만으로도 충분히 정확한 ranking 을 형성한다고 판단하였기 때문입니다.
이 팀은 SOTA로 알려진 DELG, SuperPoint 등 local descriptor 모델을 사용하지 않았습니다. computation time을 증가시킬 뿐만 아니라, 성능향상 효과또한 미미했기 때문입니다. 또한, global descriptor를 이용해서 non-landmark를 filter하는 방식을 사용했기 때문에 local descriptor를 추출해야할 필요성이 떨어진다고 판단했습니다. 그래서 global descriptor를 좀 더 발전시키는 방법으로 전략을 바꾸었습니다. 또한, 2019년 데이터셋인 GLD v1을 이용하여 2개의 backbone network를 pre-train 시켰습니다. 그러나 이 과정이 성능을 끌어올리는데는 영향을 미치지 않았습니다.
이상으로 리뷰 마치겠습니다.
지금 겪고있는 가장큰 어려움은 무엇인가요?
어려움이라기보단 이론적인 내용을 보다보니 코딩실습이 너무 부족한게 아닌가 하는 생각이 듭니다. 코드를 팀원한테 받아서 조금씩 수정해서 사용하고있는데 이번주차는 이론을 적용해보는 시도를 할 생각입니다.
좋은 글 감사합니다.
글을 읽다 보니 궁금한 점이 생겼는데, 글의 초반부 score 방식 부분에서, private과 public score를 따로 나누어 스코어링하는 이유에 대해서 혹시 아시는 것 있으신가요?
저가 1등팀으로 있었다가 2등팀으로 밀려났다면 화가 많이 났을 것 같네요ㅋㅋ…
해당부분에 대해서 설명이 나와있는 곳만 끌어왔습니다. 캐글 Overview tab에 해당 항목이 아래와같이 나와있고,
In the previous editions of this challenge (2018 and 2019), submissions were handled by uploading prediction files to the system. This year’s competition is structured in a synchronous rerun format, where participants need to submit their Kaggle notebooks for scoring.
Data tab에
Submissions are given 12 hours to run, as compared to the site-wide session limit of 9 hours. While your commit must still finish in the 9 hour limit in order to be eligible to submit, the rerun may take the full 12 hours.
와 같이 나와있습니다. 그러나, scoring방식을 나눈 이유에 대해서는 따로 안적혀있는거 같습니다. 추측하자면, 눈치싸움을 방지하기 위함이 아닐까요?
좋은글 감사합니다.
네