이번 리뷰에서는 어떠한 방법론에 대한 논문 리뷰보다는 기존 작업을 리마인드하고자 Localization Survey를 읽고 글을 정리하게 되었습니다.
해당 Survey는 실내 환경에서 이미지 기반으로의 localization 방법론들에 대한 개념 및 방법론들을 가볍게 설명하는 글입니다.
Introduction
일단 Image based localization은 학습 데이터로 학습한 공간 내에서, 촬영된 영상을 기반으로 하여 카메라의 pose(방향과 위치)를 추정하는 과정을 말합니다.
이러한 localization에 사용되는 카메라로는 일반적인 RGB 카메라만이 사용될 수도 있고, 또는 RGB-Depth Camera 조합으로도 사용된다고 합니다.
해당 survey에서 설명할 학습 기반 pipeline은 아래와 같이 세가지로 나눌 수 있따고 합니다.
- Learned Features and Matching(LFM)
- Learned Relative Pose estimation(LRP)
- Learned Absolute Pose estimation(LAP)
Techniques Overview
Image-based localization은 위에서도 설명했듯이 카메라의 pose 계산을 해야한다고 했습니다. 전통적인 방법으로는 Structure from Motion(SFM)이 존재합니다.
SFM이란 연속적인 2D 영상으로 부터 얻을 수 있는 이미지 모션 정보를 토대로 3D structure를 추정하는 컴퓨터비전 테크닉 입니다. 이러한 SFM의 전체적인 파이프라인은 아래 그림과 같습니다.
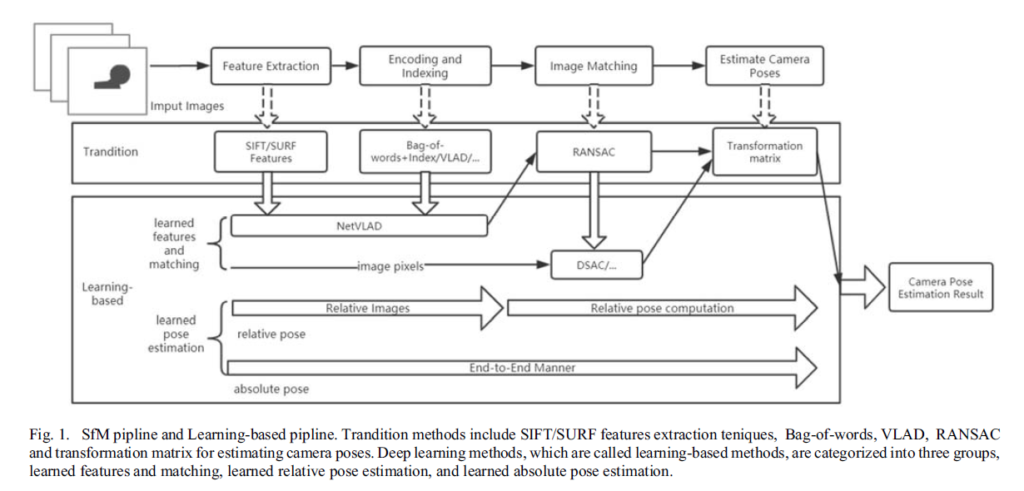
위에 그림을 보시면 확인하실 수 있듯이, SFM의 가장 큰 흐름도는 크게 아래와 같이 구성되어 있습니다.
- Feature Extraction
- Encoding and Indexing
- Image Matching
- Estimate Camera Pose
Feature Extraction은 우리가 흔히 아는 SIFT나 SURF와 같이 신뢰성 있는 매칭 descriptor를 사용했었으며, 이렇게 구한 feature를 이용하여 K-means와 벡터 양자화를 하는 BOVW, 또는 VLAD vector로 변환 시키는 VLAD 등 Feature의 Encoding 과정을 진행하게 됩니다.
그 후에는 Camera pose를 구하기 위해 가장 나이브한 방법으로는 RANSAC을 이용한 PNP 알고리즘을 통하여 매칭된 영상들간에 Translation matrix를 계산하게 되는데, 이러한 이유로 Image Matching과 Estimate Camera pose는 함께 진행된다고 해당 글에서는 표현합니다.(RANSAC + PNP를 한번에 묶어서 Estimate Camera pose 섹션에 넣어야한다고 생각하는데 따로따로 구분 짓는게 이해는 잘 가지가 않네요.)
아무튼 간에 위에가 전통적인 SFM 방식이었으며, deep learning 기법들을 추가한 파이프라인이 위에 introduction에서 언급한 LFM, LRP, LAP가 있습니다.
LFM은 feature extraction, encoding & indexing, 그리고 matching 단에서 deep learning 기반 방법론들을 사용한 것을 의미합니다.
가장 대표적인 LFM은 NetVLAD와 DSAC이 존재합니다. NetVLAD는 CNN 구조에 학습 가능한 VLAD layer를 새롭게 추가한 모델을 제안한 방법론이며, DSAC은 SFM에서 RANSAC을 CNN 방식으로 변경한 방법론을 말합니다..해당 방법론에 대해서는 뒤에서 조금 더 다뤄보겠습니다.
LRP는 하나 혹은 그 이상의 학습 영상과 관련된 테스트 영상으로부터 카메라의 pose를 추정하는 전체적인 과정을 다중 뉴럴 네트워크를 이용하는 것을 의미합니다.
LRP에 대표적인 방법론으로는 PairwiseNet과 RelocNet이 존재합니다. PairwiseNet의 경우 주어진 쿼리 영상과 유사한 데이터베이스 내 영상을 CNN을 통하여 retrieval 한 후, 쿼리와 결과 영상간에 Relative Pose까지 다 CNN으로 진행하는 방법론입니다.
RelocNet은 Siamese architecture를 통해 카메라의 상대적인 포즈를 추정합니다. 또한 카메라 포즈의 변화를 카메라 포즈 descriptor의 차이를 이용하여 표현하는 방법론입니다. 이 역시 뒤에서 알아보시죠.
LAP는 입력 영상으로부터 카메라의 absolute scene coordinates를 regression하는 문제로 학습된 CNN들을 사용한다고 합니다.
Learned features and maching
위에서 잠시 언급했듯이 전통적인 방식의 Feature Extraction(SIFT나 SURF)와BOVW, VLAD 또는 Fisher vector 등과 같은 전통적인 Encoding and Indexing 기법들의 결합보다 딥러닝 기반의 feature extraction & encoding and indexing이 훨씬 좋은 성능을 보이고 있습니다.
먼저 NetVLAD에 경우 feature extraction과 encoding을 모두 진행하는 방법론으로, 단순히 CNN 구조에 VLAD layer를 추가함으로써, end-to-end 형식을 지니고 있습니다.
InLoc이라는 방법론은, CNN descriptor를 이용한 dense matching을 사용하여 실내 장면의 카메라 위치를 추정합니다. 이러한 InLoc은 NetVLAD를 통해 feature extraction 및 encoding을 진행한 후 기존 전통적인 방식인 P3P-RANSAC을 이용하여 카메라의 포즈를 추정합니다.
NetVLAD와 같이 feature extraction의 성능을 높이려는 방법론이 있었다면, RANSAC의 성능을 올리기 위해 RANSAC에다가 CNN을 적용하는 방법론도 있습니다. 바로 DSAC입니다.
DSAC은 differentiable counterpart of RANSAC의 약자로, 카메라 localization을 목표로 합니다. DSAC의 파이프라인은 확률적 sampling을 통한 기존 RANSAC의 가설 모델 선택 방식을 대체할 두개의 학습 가능한 CNN으로 이루어져있습니다.
이러한 DSAC을 기반으로하여 DSAC++이라는 방법론이 또 제한되었는데, 이 방법론은 fully convolutional network(FCN)을 이용하였다고 합니다.
또한 ‘Scene Coordinate Regression with Angle-Based Reprojection Loss for Camera Relocalization’이라는 논문에서는 RGB 카메라의 relocalization을 위하여 DSAC와 DSAC++의 two stage 파이프라인에다가 새로운 angle-based reprojection loss를 추가하였다고 합니다.
Learned Pose Estimation
학습기반 pose estimation은 위에서 언급했듯이 relative pose estimation과 absolute pose estimation으로 나뉘어집니다.
Relative Pose Estimation은 place recognition과는 조금 다른 task라고 합니다. Place recognition의 경우 대략적인 positioning result를 제공하며 흔히 실외환경에서 많이 사용됩니다.
반면 Relative pose estimation은 정확한 카메라의 위치를 제공합니다. 학습 영상과 관련된 영상들은 명시적으로 image retrieval 과정을 사용하여 찾게됩니다.
‘Camera Relocalization by Computing Pairwise Relatie Poses Using CNN’이라는 논문에서는 주어진 쿼리 영상과 유사한 데이터베이스 내의 영상을 CNN을 통하여 relative pose를 추정하게 됩니다.
“Perspective-n-learned-point…”논문은 NetVLAD통해 쿼리영상과 가장 유사한 영상을 결정하여 초기 6DOF location을 retrieval한 후, 쿼리의 pose를 PnP알고리즘을 통하여 재정의하는 방법론입니다.
BenchMark
7Scenes Dataset을 통해 다양한 방법론들의 6D localization Error값을 비교한 테이블을 마지막으로 글을 마무리짓도록 하겠습니다.
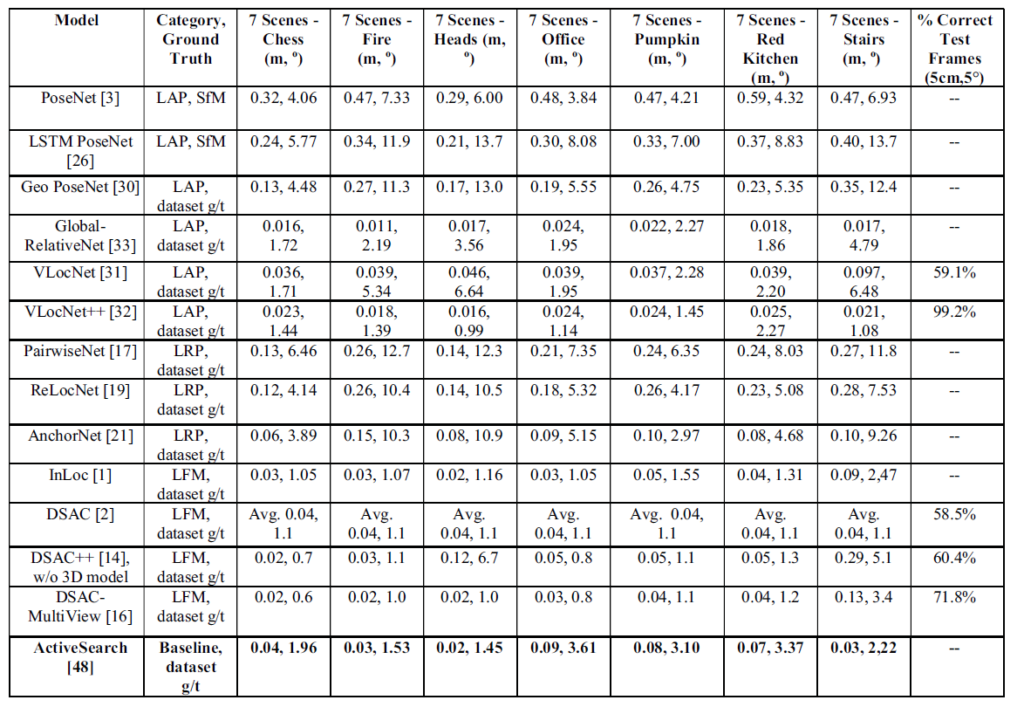
위에 표에서 baseline으로 ActiveSearch라는 방법론을 채택하였는데, 이 ActiveSearch란 deep learning 기법들을 사용하지 않은 SFM 방법론들을 Combine한 것이라고 합니다.
모든걸 cnn으로 처리하는 pairwise net은 상대적으로 성능이 가장 낮네요(error이니, 0에 가까울수록 좋은것 맞죠?). deep layer가 만능이 아님을 보여주는 예 같습니다.
regression으로 위치를 추정하는 LAP이라는 방법론에 대해 처음 알게되어 궁금해졌는데요. LAP에 대해 추가적인 설명 부탁 드려도 될까요?
해당 survey에서 LAP에 대해 간략하게 설명하기도 하고 저도 처음 접하는 개념이다 보니 이해하는데 어려움이 있었습니다.
나중에 따로 관련 논문을 읽고 리뷰형식으로 작성해보겠습니다.