해당 논문은 모바일이나 비전이 사용되는 임베디드 어플리케이션에서 효율적인 사용이 가능하도록 설계된 딥러닝 모델을 제안합니다.
Intro
기기의 성능 향상과 함께 AlexNet이나 VGG-16 같은 딥러닝 모델이 등장하면서 기계가 사람의 분류 능력을 뛰어넘게 되었습니다. 이는 서버에서 고연산을 처리하여 여러 디바이스에 처리된 정보를 전달하는 클라우드 컴퓨팅에 적용됨으로써 사용자에게 제공되기도 하였습니다.
하지만 클라우드 컴퓨팅은 네트워크 속도에 큰 영향을 받고, 자율주행차와 같이 정보 전달이 지연이 큰 영향을 주는 기기에서 사용하기에는 한계가 존재하였습니다. 이러한 흐름은 네트워크의 지연성의 영향을 받는 클라우드 컴퓨팅에서 사용자 단에서 가까운 거리에 위치한 디바이스에서 연산을 직접 처리하는 엣지 컴퓨팅의 발전으로 이끌었습니다.
그럼으로써 엣지 컴퓨팅(cpu, 저비용의 GPU 등이 적용된 디바이스)에 맞게 적은 연산이 필요한, 즉 적은 계산량으로도 빠른 정보 처리가 가능하고 성능은 유지가 되는 모델의 가치가 커지게 되었습니다.
이러한 흐름에 맞춰 제안된 것이 엣지 컴퓨팅에 맞는, 고성능이 아닌 환경에서의 CNN 모델, MobileNet 입니다.
Method
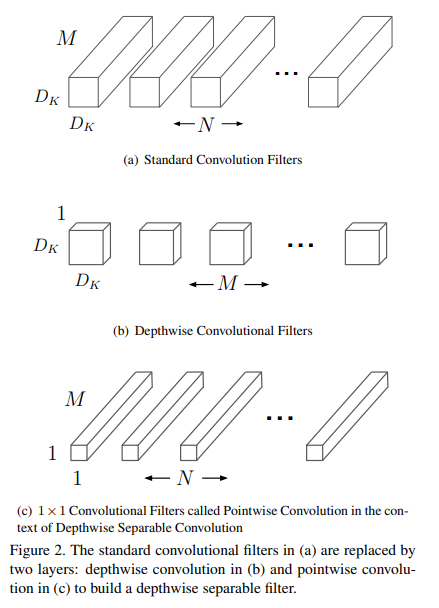
CNN의 파라미터 수를 줄이는 방법은 여러가지가 존재합니다.
– CNN에서 대부분의 파라미터를 가지는 Fully-Connected Layers를 줄이거나,
– Kernel 사이즈를 줄여 3×3 -> 1×1을 통해 연산량을 줄이거나,
– Channel 크기를 줄이거나,
– Knowledge Distillation(크고 무거운 모델의 정보를 작고 가벼운 모델에 전달하여 작고 가벼운 모델이 더 정확한 추론을 하도록 하는 학습 방법)을 사용하거나,
– TensorRT, AMP를 이용하여 모델을 압축하거나,
등의 방법들이 존재합니다.
해당 논문에서는 기존 CNN에서 사용하는 point-wise conv(Fig 2. (a) Standard Convolutional Filters)를 변경하여 channels 나누어( channel=1) 연산(Depth-wise Convolution) 하고 1×1 kernel을을 사용함으로써 계산량을 줄이는 방법(Fig 2. (b), (c) -> Separable Convolutions)을 사용합니다.
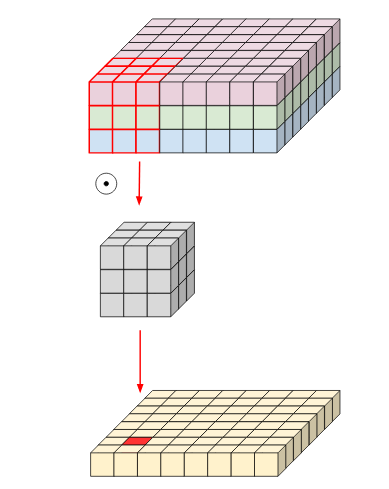

좀 더 이해하기 쉬운 그림은 위와 같습니다.
그림 2와 같이 간단한 방법이 기존의 방법 그림 1에 비해서 얼마나 계산량이 줄어드는지는 아래와 같습니다.
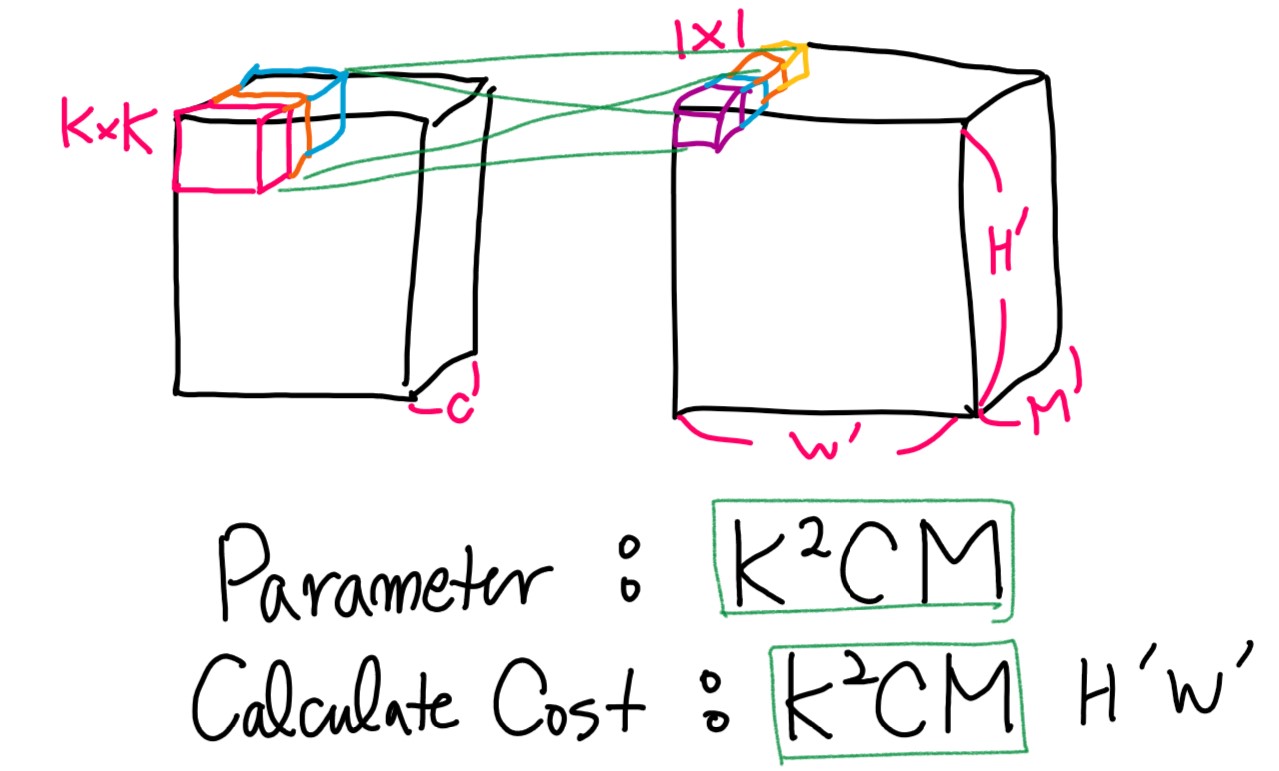
기존의 CNN의 filter는 KxK*C인 tensor(K는 커널 사이즈, C는 channels)를 사용한다고 가정합니다. 필터가 적용된 feature는 W’ x H’ x M을 가진다고 가정하고 식을 계산하도록 하겠습니다. KxK*C 필터가 Conv 연산을 수행한다면 파라미터는 K^2*C*M을 가지게 됩니다. 또한 계산량은 파라미터 갯수 K^2*C*M * ( W’ * H’)을 가지게 됩니다. (그림 3. 참고)
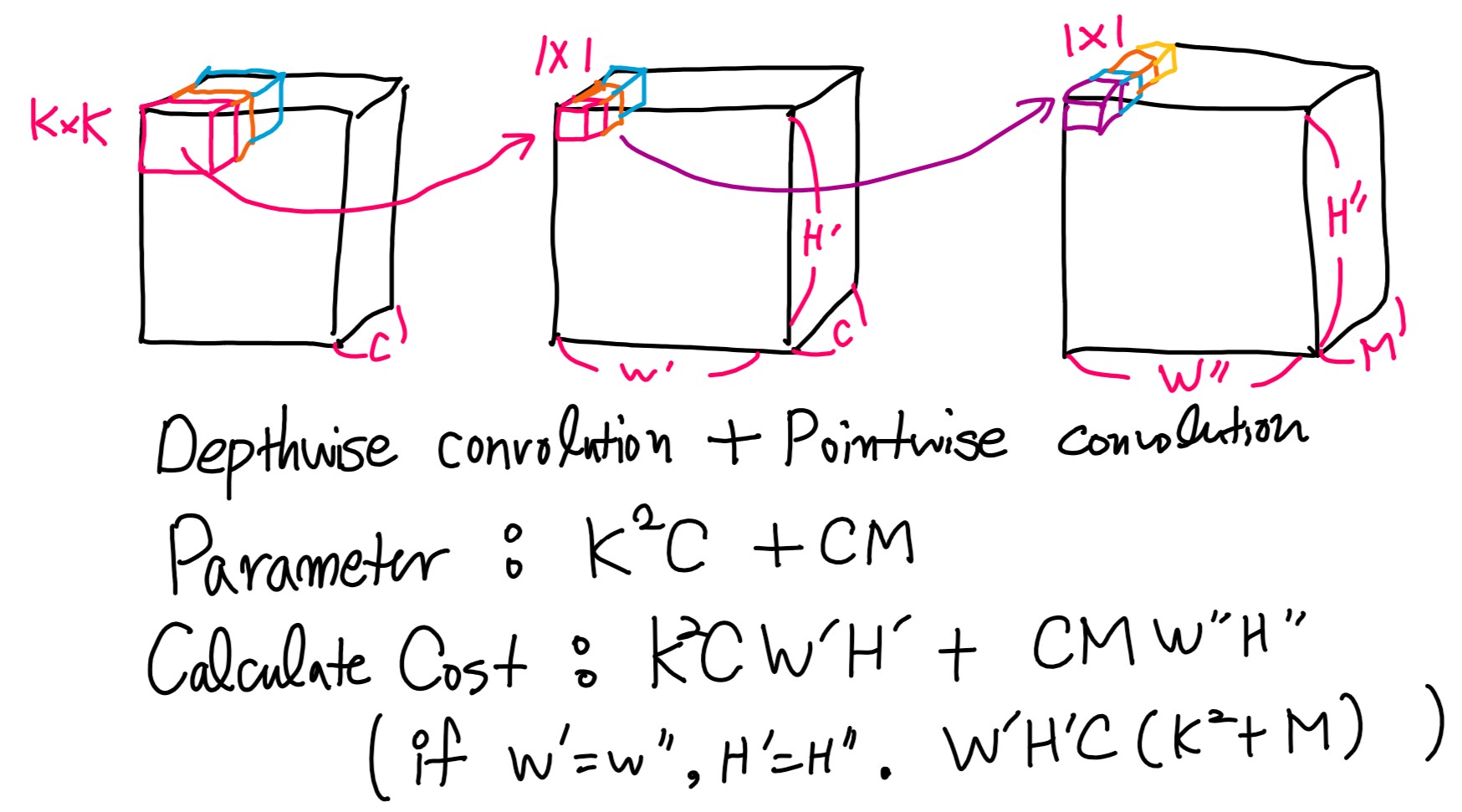
Separable Convolutions는 우선 각 채널은 그대로 두고 연산을 진행하는 Depth-wise convolution을 진행합니다. 기존 연산과 다르게 M=1이기 때문에 파라미터는 K^2C를 가지게 됩니다. 그 다음 1×1 kernel을 이용하여 변경하기 원하는 channel 사이즈인 M으로 Pointwise convolution을 진행합니다. 이에 따른 파라미터 갯수는 C*M를 가지게 됩니다. (그림 4. 참고)

Separable Convolutions의 구체적인 구조는 Fig 3.을 참고하시면 됩니다.
해당 논문에서 사용한 방법은 tensor 연산들을 non-tensor(2d, 1d) 연산으로 변경하되 결론적으로 같은 방식의 conv연산을 수행함으로써 성능은 기존 CNN과 동일하고 더 높은 성능을 보여주었습니다.(Experiments 참고)
또한 대부분의 CNN에서 사용하는 커널 사이즈 K=3을 적용한다면 계산량이 8~9배가 감소함으로써 기존 CNN에 견주는 성능과 8~9배 감소된 계산량으로 엣지 컴퓨팅에 맞는 모델로 선호 받고 있습니다.
Experiments
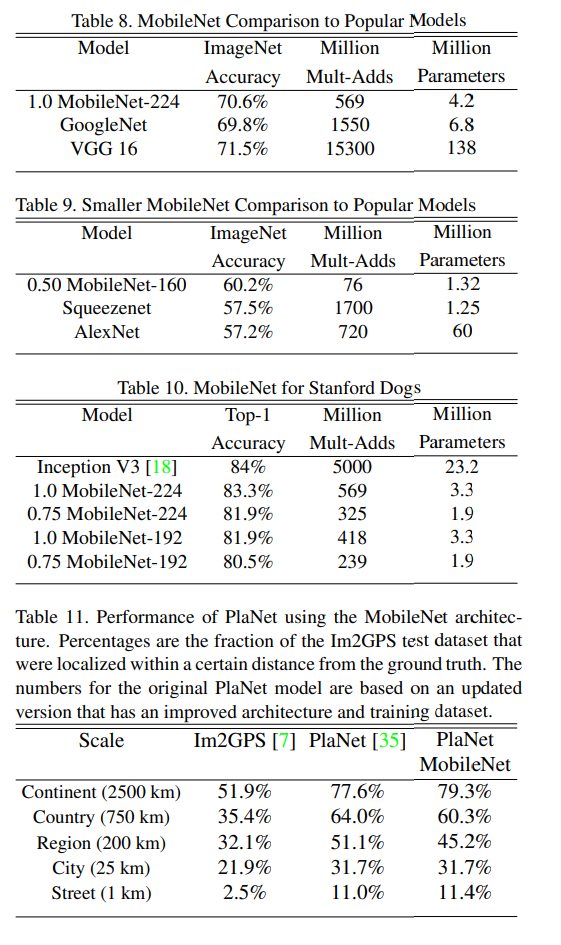
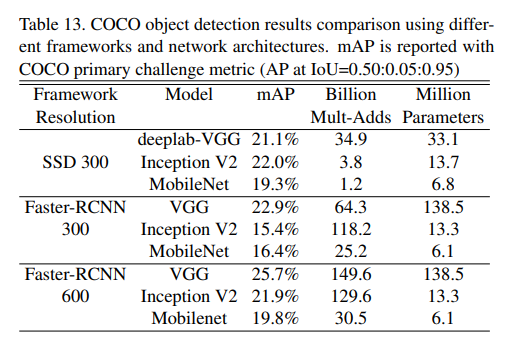
++ 결론적으로 MobileNet은 tensor 연산에 어울리지 않은 cpu 연산에서는 최적인 방법론인 것 같다. 근데 딥러닝 장비로 흔히 사용되는 GPU들은 tensor 형태의 연산에 최적화된 장비인 걸 고려하면 GPU와 CPU에서의 속도 비교가 궁금하다.
안녕하세요.
글을 읽고 제가 잘 이해했는지 궁금하여 질문드립니다.
기존에는 모든 채널을 통째로 들고 커널과 컨볼루션 연산을 하였다면 모바일넷에서는 각 피쳐의 채널을 하나하나 나누어 커널 연산을 진행 후 모두 합친다음 1×1으로 다시 연산하는 것인가요?
그리고 잘 몰라서 그러는데, Depth-wise convolution과 Point-wise convolution이 구체적으로 뭐가 다른건가요?