현재 연구실에서 진행중인 IITP 과제는 스마트폰에서 취득할 수 있는 데이터를 가지고 우울증의 위험도를 예측해 우울증의 위험도가 높은 사람들에게는 치료를 권할 수 있는 앱을 만드는것을 목표로 합니다. 이와 관련된 논문이 있어 리뷰하고자 합니다.
우울증을 어떻게 측정하는데?
가장먼저 우울증을 어떻게 측정하는지 알아야겠죠..? 의학적으로 우울증을 판단하는 방법은 다양하겠지만, 제가 알고있는 방법과 이번 과제에서 타겟으로 하는 방법은 설문조사를 통한 우울증 측정입니다.
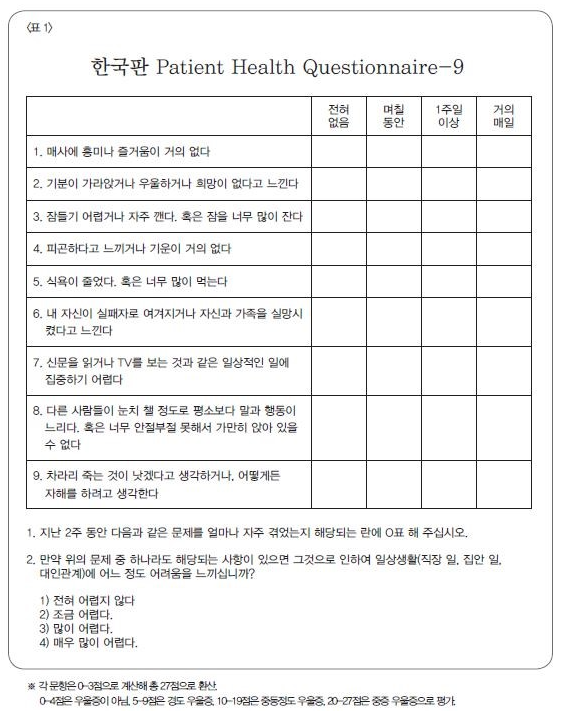
가장 대표적인 설문조사가 위의 그림과 같이 PHQ-9 이라는 조사입니다. PHQ-9으로 측정하고자 하는 것은 총 9가지인데요 다음과 같습니다. 각 체크하고자하는 것과 위의 번호를 매칭시키겠습니다.
- Appetite level => 5
- Interest level => 1
- Energy/fatigue level => 4
- Concentration level => 7
- Psychomotor agitation/retardation =>8
- self-criticism => 6
- Feeling sad/depressed => 2
- Sleep disturbance => 3
- Suicidal ideation => 9
그리고 PHQ-9보다 더욱 종합적인 검사라고 불리는 QIDS도 존재합니다.


QIDS와 PHQ-9를 보시면 공통적으로 묻는 항목들이 눈에 보이실 겁니다. 결국 우울증이 시작되면 설문지에서 묻는 증상들이 나타나기 시작합니다.
본 과제에서는 ‘이러한 증상들을 스마트폰으로 측정할 수 있다면, 미리 측정해서 치료를 권유할 수 있지 않을까?’에서 시작합니다. 그리고 실제로 이를 위한 많은 연구가 진행되고 있으며, 오늘 리뷰할 논문이 제가 생각한 IITP 과제와 가장 연구내용이 일치한다고 생각해 해당 논문을 리뷰하고자 합니다.
그래서 이런 연구들은 어떤게 있는데?
앞서 말한것처럼 스마트폰을 이용해서 우울증 혹은 우울감을 측정하려는 많은 연구들이 있습니다. 이는 현대인들에게 우울증은 흔한 질병이 됐다는것 의미하는것 같아 많이 씁씁하네요..
해당 논문에서 말하는 스마트폰 센서로 우울증을 측정하는 연구의 방향은 크게 2가지 입니다. 스마트폰 센서로 취득할 수 있는 장소, 활동정도, 폰사용기록 등으로 우울감을 측정하는 연구와 특정 지역에 한해서 Wifi가 연결된 정보를 통해서 스마트폰 유저의 행동패턴 및 반경을 분석해 우울증을 측정하는 연구입니다. 여기서 두번째 방법은 취득된 Wifi ID에 매칭되는 장소에 대한 정보가 분명하게 나타나는 곳에서만 정확한 메타데이터를 취득할 수 있고, 대부분의 연구가 학교와 같이 한정된 구역에서 수집된 데이터를 활용하고 있습니다. (예를들면 RCV 와이파이를 잡으면 해당 인원이 RCV 연구실에 있음을 파악할 수 있습니다. 이는 RCV 와이파이가 RCV 연구실에 있다는 사실을 알기 때문에 활용 가능합니다. 이처럼 각 구역마다 혹은 위치마다 명확한 와이파이가 존재하고 이에 대응될때 해당 정보를 활용할 수 있습니다.)
그런데 우울증을 어떻게 예측할건데? 데이터는 어떻게 모으고?
우리가 아는 ML 방법 혹은 딥러닝 방법으로 (물론 Unsupervised 방법도 존재하지만) 우울증을 예측하기 위해서는 label이 필요합니다. 그런데 이러한 라벨은 어떻게 얻을 수 있을까요?? 그래서 기존의 데이터셋들은 학생들에게 앞서 설명들인 PHQ-9, QIDS를 일정 간격으로 설문조사 하는 동시에 휴대폰으로 데이터를 취급합니다. 물론 개인정보이기때문에 피실험자에게 모두 동의를 구하여 데이터 수집이 들어갈 수 있는데, 그렇기 때문에 데이터가 귀하고 한정적입니다.
해당 논문에서도 한 대학교 학생들 약 180명에게 사전 동의를 구한 후 스마트폰 데이터와 우울감 진단 설문조사 데이터를 함께 취득합니다. 설문조사 결과를 라벨로 사용하고 스마트폰 데이터로 학습을 수행하게 됩니다.
해당 논문 뿐만 아니라 실제 스마트폰 데이터를 통해서 우울감을 측정하기위한 많은 연구들이 진행됐고 각자가 데이터셋을 구축하는것이 일반적입니다. 유일하게 공개된 오픈데이터셋이 존재하는데 바로 Student Life 데이터셋 입니다. 이 데이터셋은 위에서 언급한 PHQ-9 설문조사와 스마트폰 데이터를 포함하고 있는 데이터셋이라 실제 이쪽 연구에서도 해당 데이터셋을 많이 활용합니다. Student Life 데이터셋에 대해서는 프로젝트 페이지에 자세히 설명됐으니 궁금하신 분들은 구경하셔도 좋을 것 같습니다.
https://studentlife.cs.dartmouth.edu/dataset.html
예측하기에 앞서 설문조사 결과는 어떻게 다룰건데?
자 다시 본론으로 돌아와서 앞서 설명한 방법으로 데이터셋을 취득했습니다. 이제 우리가 해야할 취득한 데이터를 피처로 만들고 해당 피처를 통해서 우울증 혹은 우울감을 분류해야겠죠?? 제가 설명하고자하는 논문에서는 이런 방법을 어떻게 수행했을까요? 그전에 앞서 설문조사를 분석하는 방법에 대해서 설명하겠습니다.
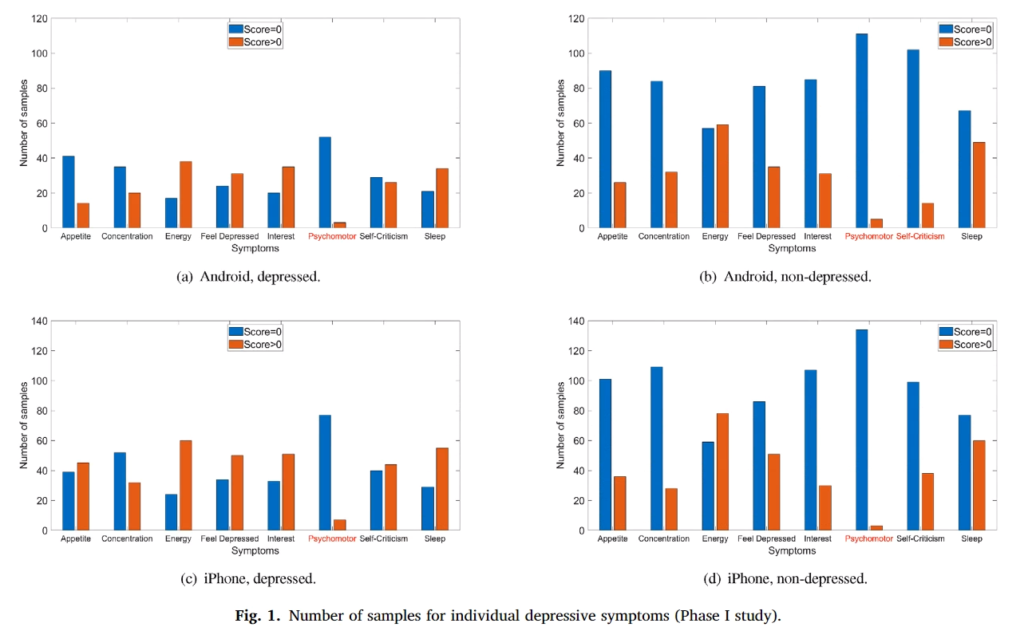
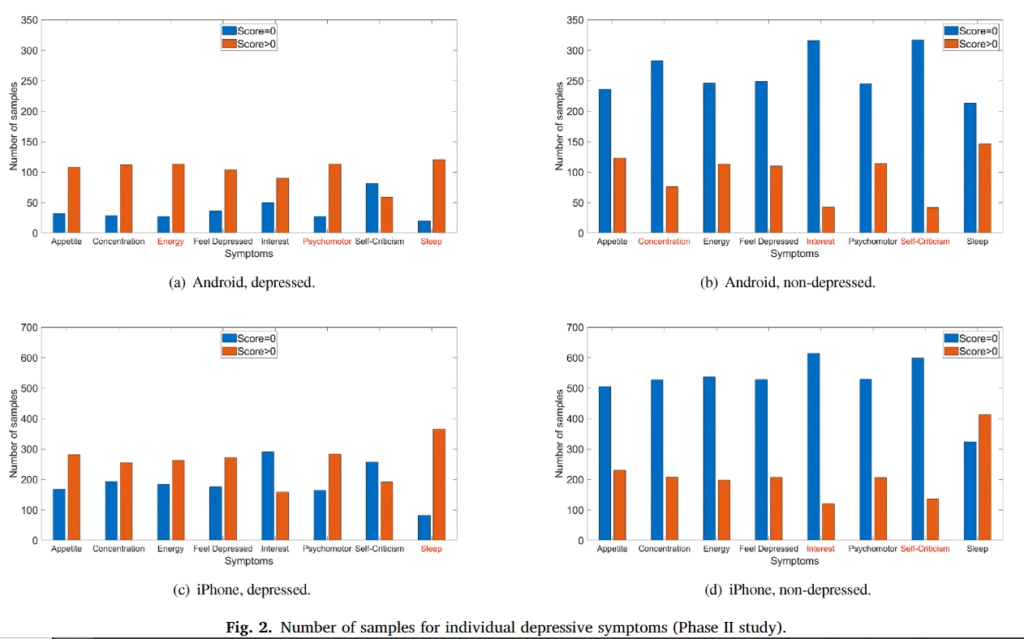
위의 표는 임상결과(실제 정신과 전문의 상담) 우울증이 있는 사람과 우울증이 없는 사람이 PHQ-9에 응답한 결과입니다.(참고로 2군집으로 나눠서 실험을 진행했기 때문에 표가 Phase 1, Phase 2 로 나타내고 있습니다) 앞서 표에서 보시면 0~3점까지 스코어를 매겼는데 해당 논문에서 실제 2~3점을 체크한 사람은 거의 없기 때문에 질문에 대한 대답을 데이터로 만들때 1점 이상이거나, 0점이거나 2가지로 분류했다고 합니다. 근데 실제 데이터를 봐도 임상결과 우울증이 없는 사람들은 대부분이 0점을 표기했기 때문에 이런식의 분류가 가능함을 설명하고 있습니다. 위에서 빨간색은 해당 증상이 있다고 표기한 사람들(1점 이상) 그리고 파란색은 0점입니다. 아 그래고 위에 표를 보시면 X축이 8개인걸 볼텐데 PHQ-9은 9개라서 당황하셨죠?? 빠진 항목은 자살경험이나 자살시도와 관련된 질문인데 이와 관련된 질문은 거의 모든 사람들이 0이라서 제거했다고 합니다. (실제 그럴것이 자살을 매번 시도하는 피실험자의 경우는 실험에 참가해달라고 할게 아니라 당장 병원에서 치료를 받게 해야하겠죠…)
그리고 해당 실험은 스마트폰 센서에서 취득한 데이터로 우울증을 예측할 예정이기 때문에 안드로이드와 아이폰으로 집단을 나누었습니다. 위 히스토그램 표에서 위가 안드로이드, 아래가 아이폰입니다.
자 그럼 Label을 만들었으니 Feature는 어떻게 만들건데?
‘We only focus on location data’
해당 논문에서는 스마트폰에서 얻을 수 있는 데이터를 가지고 우울증 예측을 할때, location data에 집중합니다. 아참 여기서 늘 스마트폰에서 얻은 Location 정보가 유실될 수 있습니다. 그리고 유실된 데이터는 Location 의 정확성을 떨어트립니다. 따라서 해당 논문에서는 유실된 Location 정보들을 분석하고 해당 데이터에 대응하는 label, 즉 설문조사들은 과감히 제거하게 됩니다. 왜냐구요? 노이즈가 될 수 있기 때문입니다!
자 그럼 Location 정보가지고 어떻게 Feature Extraction을 진행하였을까요? 해당 논문에서는 Location 정보을 가지고 다음과 같이 10개의 Feature를 만듭니다.
- Location variance
- Time spent in moving
- Total distance
- Average moving speed
- Number of unique locations
- Entropy
- Normalized entropy
- Time spent at home
- Circadian Movement
- Routine Index
몇개는 감이 오고, 몇개는 모르겠죠? 하나씩 설명드리겠습니다. 일단 해당 논문에서 Location 정보를 가지고 만든 10개의 Feature에서 앞에 4개(Location variance~Average moving speed)는 바로 Location 데이터를 가지고 계산한 반면 나머지 6개(Number of unique location ~ Circadian Movement)는 DBSCAN(이거 기계학습때 배웁니다. 클러스터링 알고리즘이에요) 방법을 통해서 clustering하고 계산합니다.
Location variance : 해당 데이터는 피실험자의 ‘지역 변화정도’ 측정하는 것 입니다. 그냥 위도,경도 가지고 얼마나 돌아댕기는가를 나타낸다고 보시면 됩니다.
Time spent in moving : 해당 데이터는 ‘피실험자가 돌아댕기는데 하루의 몇퍼센트를 사용하는가’ 입니다. 돌아댕김을 측정하기 위해서 moving speed를 사용하고, 1km/h가 넘는 속도로 움직일때 ‘돌아댕김’으로 계산합니다.
Total distance : 해당 데이터는 얼마나 돌아댕겼는가를 나타내는 피처입니다. 이는 GPS 정보로 측정하며 두 샘플간의 거리(km)를 Harversine formula(뭐지..)로 계산했다고 합니다. 그리고 여기서 계산한 거리를 시간으로 정규화해 사용했다고 합니다.
Average moving speed : 돌아댕긴 평균 속도를 의미합니다.
Number of unique locations : 해당 피처는 DBSCAN 알고리즘으로 얻은 unique cluster의 갯수라고 합니다. (아마도 정상적인 패턴을 벗어난 지역을 방문한 횟수가 아닐까요..?)
Entropy : 해당 피처는 다른 Location에서 얼만큼의 시간을 사용했는가를 나타내는 피처입니다. 앞서 DBSCAN으로 구한 클러스터에 얼만큼 머물렀는지를 각각 클러스터마다 계산했다고 합니다.
Normalized entropy : 이는 unique cluster의 갯수를 entropy로 나눈 피처입니다. 이 피처를 통해 entropy가 cluster 갯수에 상관없이 각각의 location cluster 독립적이라고 합니다..(흠…어려워지기 시작하네요)
Time spent at home : 해당 피처는 피실험자가 얼마나 집에 얼마나 머물렀는지 나타냅니다. 이때 ‘Home’이라 함은 DBSCAN으로 구한 cluster에서 가장 빈도수가 높은 6개라고 합니다.
Circadian Movement : 해당 피처는 다른 논문(Saeb et al., 2015) 에서 제안한 피처인데, ‘what extent a participant’s sequence of locations followed a 24-h or circadian rhythm’을 나타낸다고 합니다. circadian rhythm의 뜻을 활동주기(생체리듬)라고 한다면 피실험자의 위치 시퀀스가 24-h 인지 circadian rhythm인지를 나타내는 정도라고 합니다.. (이것도 잘 이해가 안되네요)
Routine Index : 다른 날과 비교해 얼마나 다른 장소들을 방문했는지를 나타내는 피처입니다. 이때 장소는 앞서 말씀드린 DBSCAN을 통해서 어떤 클러스터에서 다른 클러스토 이동할때 장소가 카운팅 됩니다. self-report를 수행하는 간격으로 계산을 수행한다고 합니다. 값은 0~1 사이로 나타내는데 1에 가까울 수록 유사한 즉 해당 기간동안 방문한 장소들이 비슷하다는 것을 의미한다고 합니다. (이것도 어렵군요..)
아무튼! 이러한 10개의 feature를 만들고, 이를 통해서 우울감을 분류했다고 합니다. 위에서 말하는 feature는 Hand craft Feature라고 볼 수 있겠습니다. @jslee(보고있나)
자 그래 그럼이제 feature를 extract했으니 분류를 해보자
해당 논문에서는 이러한 feature들을 가지고 분류를 수행하는데 우리가 모두 너무나도 잘알고 있는 SVM을 사용했습니다. 커널은 RBF 커널을 사용했구요.. C와 감마 값을 튜닝하면서 최적의 값을 찾았다고 합니다.
(더이상의 자세한 설명은 생략하겠습니다)
마지막으로 분류 결과를 확인해보자
앞서 2개의 실험군을 나눠서 진행했다고 설명드렸습니다. 그럼 각 실험군에 대해서 앞서 구한 feature를 SVM으로 분류한 결과를 확인해 봅시다.
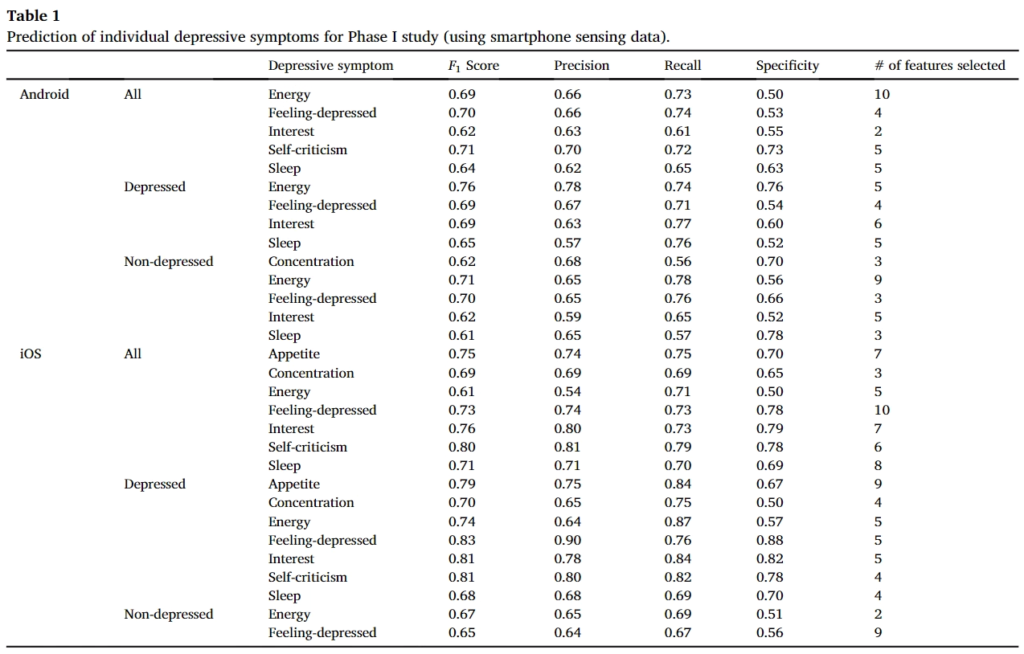
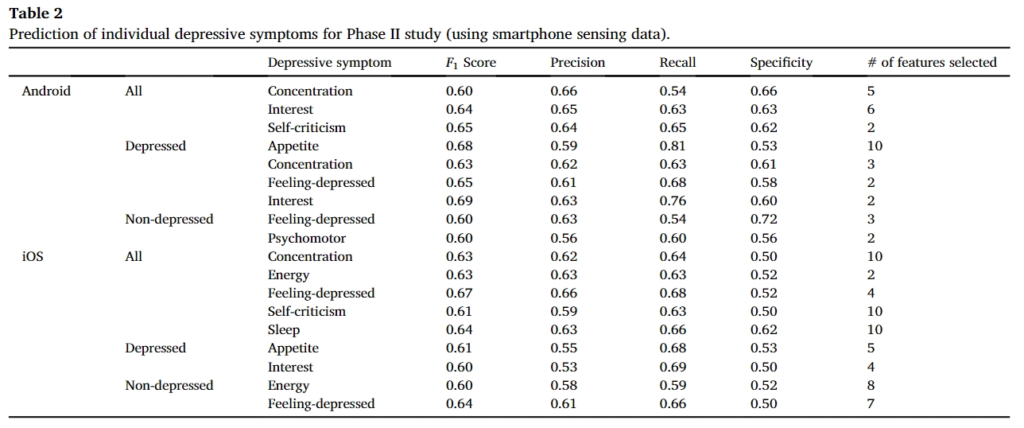
앞서 구한 feature들로 (가장 오른쪽에 매칭되는 feature 넘버가 있습니다) 우울증의 증상들(앞서 PHQ-9, QIDS 에서 측정한 지표들 기억나시죠?)의 평가 결과입니다. 전반적으로 5~60%의 Precision을 나타냈습니다. 여기서 Precision을 나타내는 방법은 앞에서 score가 1이상인것과 0점인것으로 2가지 클래스가 있습니다. 이에대해서 맞췄는가를 나타낸 것으로 기대값은 50%입니다. (찍어맞추면 50%이므로)
자 그러면 Meta data인 Wifi 데이터를 가지고 예측해볼까요?
앞서 설명한 실험은 Smartphone에서 얻을 수 있는 정보들을 가지고 (더 정확히는 GPS Location 이겠죠..?) 분류를 수행했다면 이제는 Wifi를 가지고 실험을 진행합니다. Wifi의 특징은 더 정확한 위치를 알 수 있다는 점 입니다. (GPS는 대양AI센터 라면 Wifi는 RCV 연구실과 같이… 다른 예로는 GPS는 학생회관이라면 Wifi는 학생식당인지 학생회관 헬스장인지와 같은 정보를 알 수 있습니다.)
앞서 휴대폰으로 측정한 데이터는 아이폰과 안드로이드폰으로 나눴다면 이제는 Wifi를 사용하는 정보를 하루종일 얻느냐, day time에만 얻느냐로 나뉩니다. 각 실험군에 대한 데이터셋 분포는 다음과 같으며 내용은 앞서 설명했습니다.
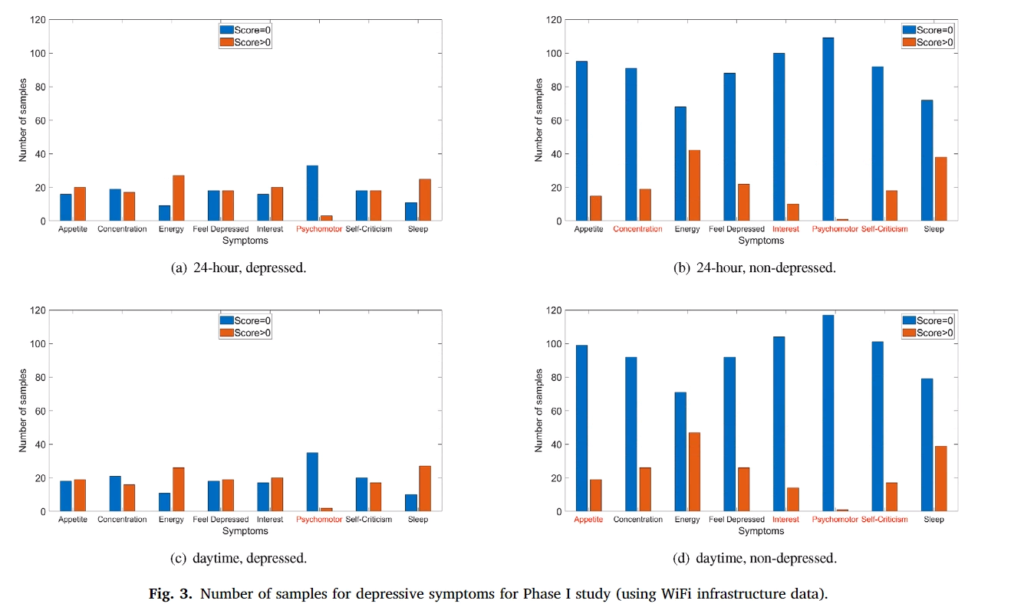
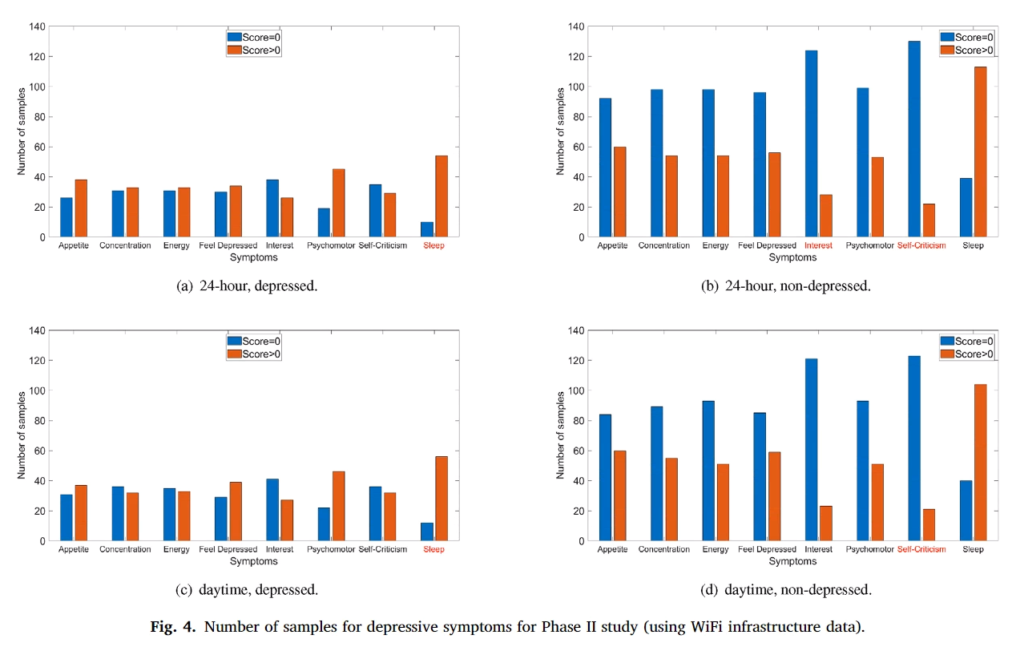
참고로 여기서도 실험군을 2개로 나누어 진행했습니다.
Wifi 데이터를 가지고 해당 논문에서는 18개의 feature를 만들었습니다. 앞서 스마트폰에서 취득하는 데이터를 가지고 만든 feature보다는 8개가 더 많습니다. 그래도 기본적인 feature 6개(including the number of unique locations, entropy,
normalized entropy, time spent at home (only applicable to 24-h monitoring), circadian movement, routine index) 는 공유하고 있습니다. 이때 계산할때 차이점은 앞선 방법은 DBSCAN으로 구한 cluster ID로 feature를 계산했다면 이번 실험은 Wifi 정보로 얻은 건물 ID로 feature를 계산했다고 합니다. 이때 빌딩 ID는 entertainment, sports, class, library 등으로 나타냈다고 합니다. 앞의 방법과 공유하는 feature를 제외하고 Wifi 정보를 사용해 계산한 새로운 feature는 다음과 같습니다.
- Number of significant locations visited-1
- Number of Entertainment, Sports and Class buildings visited-3
- Average duration spent in Entertainment, Sports, Library and Class buildings -4
- Number of days visiting Entertainment, Sports, Library and Class buildings – 4
잠깐, 앞에서 18개의 feature를 사용했다고 말했고, 6개는 공유하면 12개가 더 필요한데 왜 4개만 작성했을까요? 그 이유는 위의 feature에서 ‘-?’로 표기한 숫자가 각 피쳐의 갯수들 입니다. 즉 건물마다 feature가 존재하니 갯수가 여러개인것입니다. 그럼 각 feature에 대해서 논문은 어떻게 설명하고 있을까요?
Number of significant locations visited : 해당 피처는 피실험자에게 실험에 앞서 가장 많이 방문하는 빌딩의 ID를 설문조사에서 받아내고, 실제 해당 빌딩에 얼마나 방문하는지 나타낸 것이라고 합니다.
Number of Entertainment, Sports and Class buildings visited : 해당 피처는 캠퍼스에 있는 Entertainment, Sports, Class 빌딩에 얼마나 방문했는지 나타낸 횟수이다. 이때 간격은 PHQ-9 or QIDS 설문조사 간격을 기준으로 계산한다. 각 빌딩마다 feature 1개씩 총 3개의 feature이다.
Average duration spent in Entertainment, Sports, Library and Class buildings : 해당 피처는 피실험자가 Entertainment, Sports, Library, Class 빌딩에서 어느기간 머물렀는지에 대한 평균치며 이 또한 PHQ-9 or QIDS 설문조사 간격을 기준으로 계산한다. 각 빌딩마다 feature 1개씩 총 4개의 feature이다.
Number of days visiting Entertainment, Sports, Library and Class buildings : 해당 피처는 피실험자가 Entertainment, Sports, Library, Class 빌딩에 얼마나 방문했는지 나타낸다. 이 또한 PHQ-9 or QIDS 설문조사 간격을 기준으로 계산한다. 각 빌딩마다 feature 1개씩 총 4개의 feature이다.
앞선 feature 도 동일하게 SVM으로 분류를 진행했으며 결과는 다음과 같다.
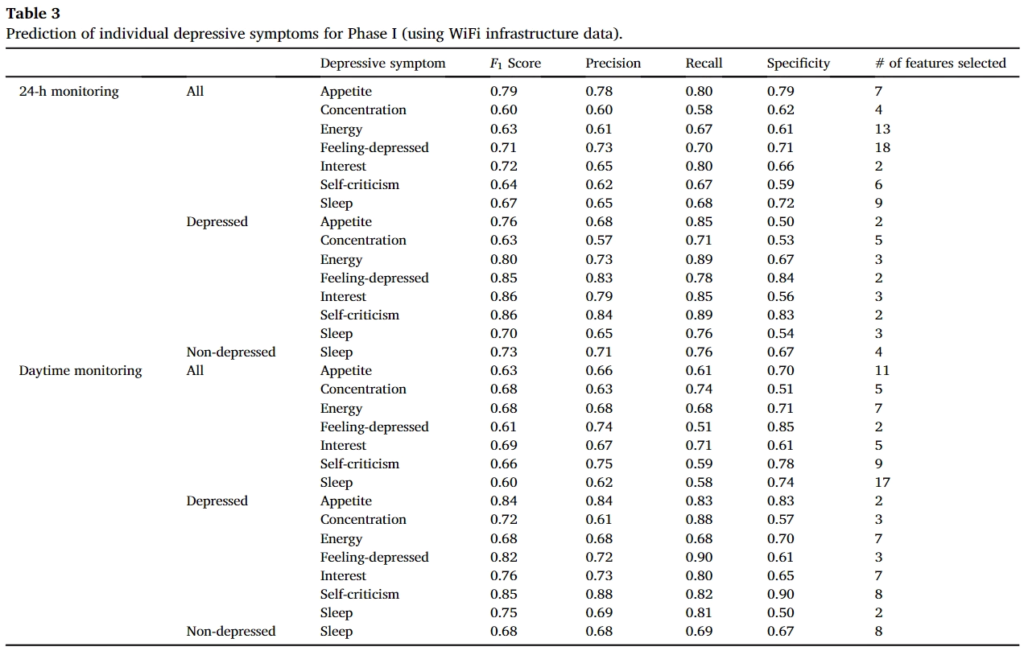
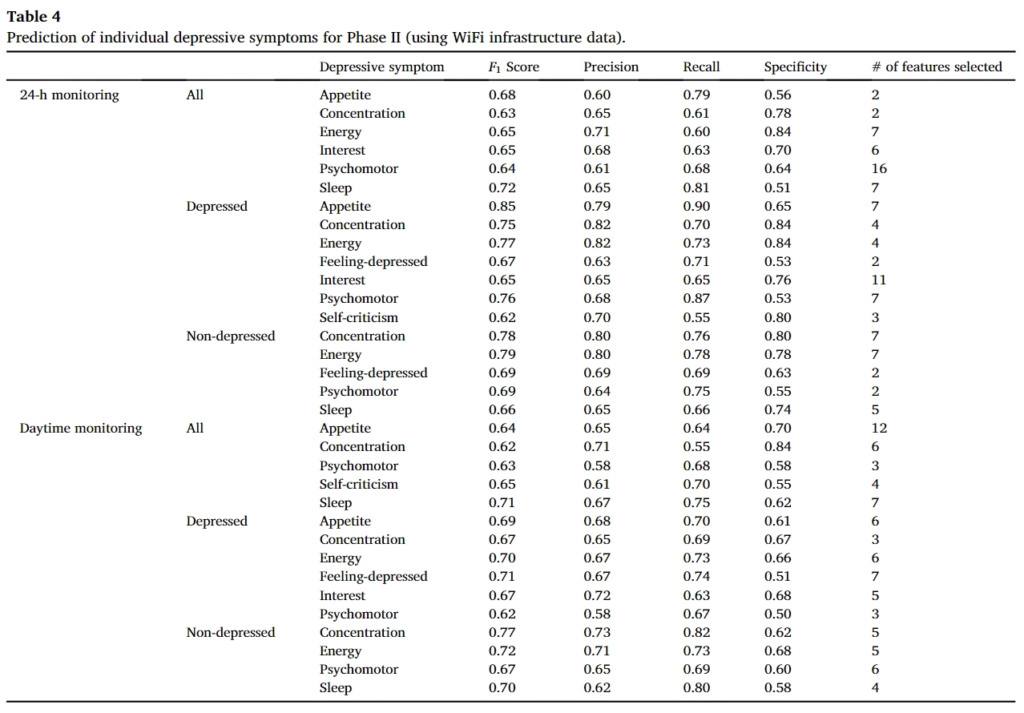
해당 결과에서는 앞서 설명했듯 24시간 모니터링과 day time 모니터링에 대해서 구별해서 성능을 나타냈으며, 앞선 스마트폰 센싱보다는 좀 더 좋은 성능을 나타낸다.
그래서 결론은?
앞서 리포팅한 결과는 Depressive symptoms에 관한 정확도를 나타냈다면, 이제는 finer-level에서 두 결과를 비교하면 다음과 같다. 처음 결과는 스마트폰 센싱 데이터를 사용한 결과이며, 두번째는 WiFi 데이터를 사용한결과이다.
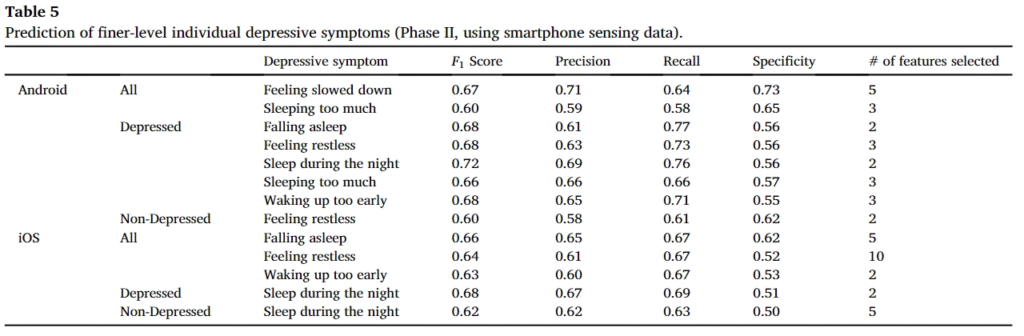
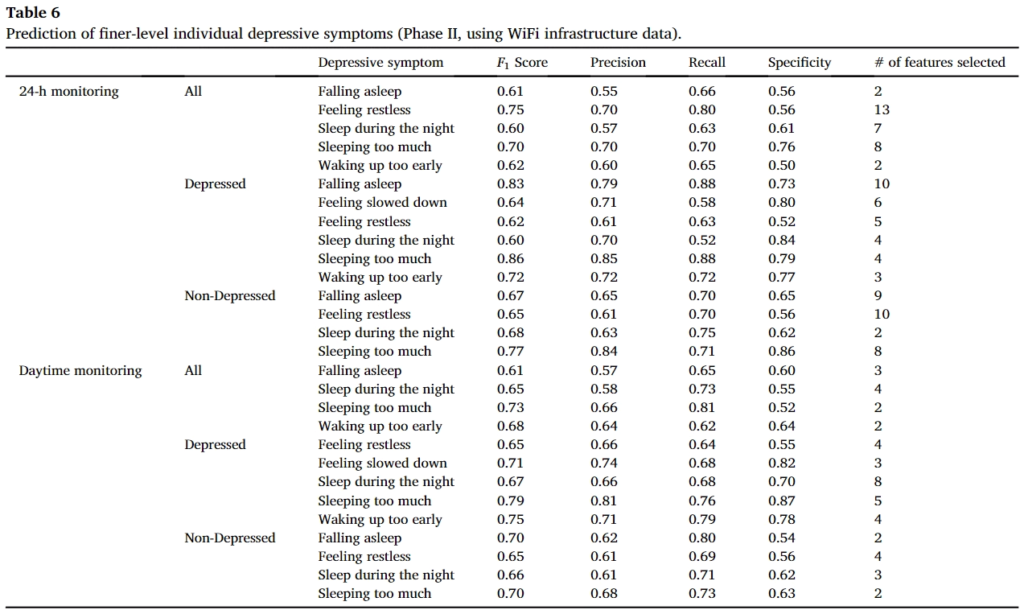
해당 결과에 대해서 논문의 저자는 다음과 같이 말한다.
Comparing the results in Tables 5 and 6, we see that the prediction results when using WiFi infrastructure data are better than those using the smartphone sensing data. The latter can be improved by further refining feature extraction and data collection, which is left as future work.
또 결론에서는 다음과 같이 이야기한다.
We primarily used location data in this paper. The participants of the study were college students. Future directions include (1) using other types of sensing data (e.g., activity, SMS and email logs, web browsing records), and (2) exploring in other demographic groups.
우리는 IITP 에서 이 사람들의 다음 연구를 수행할 예정이다.
(참고로 해당 논문은 2020년 3월에 퍼블리쉬된 논문입니다)
해당 논문 리뷰는 연구실 인원들을 위해서 의식의 흐름으로 글을 작성하였으며, IITP 공식 Github에는 좀 더 오피셜하게 작성해보겠습니다.
안드로이드와 아이폰으로 집단을 나눠 데이터 분석을 한 이유는 차후 어떤 알고리즘으로 판별을 할 때 스마트폰 기기에 대한 정보도 들어간다고 이해를 하면 될까요?
아니요 스마트폰 센서로 데이터를 얻는데 안드로이드폰과 아이폰의 특성이 다르기 때문에(도메인이 다르기 때문에) 분리했다고 보면 됩니다. 네이버랩스 인도어셋에서도 카메라마다 분리해서 생각한것과 비슷합니다.
@Jwon, 네 안다고 가정합니다.