

Image retrieval의 경우, 주로 query 한 장에 대해 유사한 영상을 한 장씩 찾아내게 됩니다. 그러나 비디오는 영상처럼 한 장으로 길이가 정해져 있는 것이 아닌 각기 다른 길이를 가지고 있습니다. 그래서 video retrieval task에서 유사한 비디오를 찾을 때 고려해야하는 요소는 아예 중복되는 비디오부터 같은 활동, 사건을 나타내는 비디오까지 다양합니다. 이러한 이유로 본 논문의 저자는 video retrieval에서 고려해야할 요소를 정의하고 FIVR-200K 라는 대용량 데이터 셋을 제안하였습니다.
1. Definition
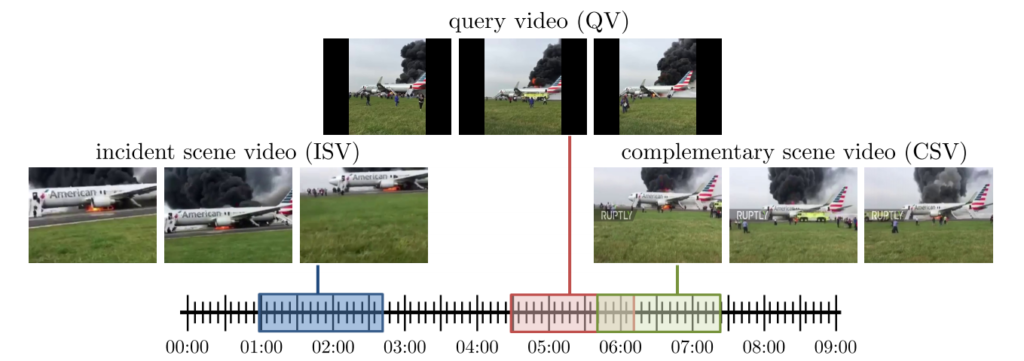
- Duplicate Scene Videos (DSVs)
만약 두 비디오가 있을 때 photometric variation, 길이 혹은 다른 여타 수정의 관점에서 차이가 있다고 하더라도 거의 동일하게 중복되어 있을 때 두 비디오 사이의 관계를 DSVs로 정의하였습니다. 다른 말로 설명하자면 비디오에서 가리키는 장면도 동일해야하고 같은 time segment 안에 있어야하며 view point도 동일 해야합니다. 이는 Table 1에서 정의 되어 있으며 만약 query가 아닌 candidate video에서의 모든 프레임이 Table 1의 식 (1)을 1로 만족한다면 이를 DSVs 중에서도 Near-Duplicate Videos (NDVs) 로 정의했습니다.
- Complementary Scene Videos (CSVs)
두 비디오가 같은 장면을 가리키고 있고 time segment도 겹쳐야하지만 서로 다른 카메라로 찍어 view-point 가 다른 경우는 CSVs 로 정의했습니다. Fig 2에서 보면 서로 같은 장면을 나타내고 있고 비슷한 시간대에 촬영되었으나 서로 다른 view-point를 가지는 것을 확인할 수 있습니다. CSVs 또한 Table 1에서 정의된 수식을 확인할 수 있으며 저자는 두 비디오 사이의 관계가 CSVs 인지 확인하는 것은 어렵기에 소리나 다른 시각적 신호를 참고하기도 한다고 합니다.
- Incident Scene Videos (ISVs)
두 비디오가 같은 장면을 가리키고 있지만 time segment가 겹치지 않는 상황은 ISVs 로 정의되었습니다. 둘은 시간적으로 전혀 겹치지 않지만 어떤 동일한 사건이나 활동을 가리키는 관계에 놓여져 있게 됩니다. 특히, ISVs 는 다른 시간대에 같은 곳을 가리키는 특성으로인해 시각적인 정보로는 알 수 없고 어떤 개인의 다른 지식을 통해야 알 수 있는 경우가 있습니다. 예를 들어, 한 사건 동안 query는 빌딩 밖에서 빌딩을 촬영하고 있고 candidate는 빌딩 내부에서 빌딩을 촬영하고 있는 관계가 ISVs 의 특이한 경우 입니다. ISVs 도 나머지 정의들과 마찬가지로 Table 1에서 수식으로 정의된 것을 확인할 수 있습니다.


2. Dataset
- Video collection

FIVR-200K 데이터 셋은, 비디오들은 수많은 사건이나 활동을 나타내야하며, 데이터셋의 크기는 retrieval task를 위해 충분히 커야 한다는 목표하에 구성되었습니다. 이러한 요건 하에, 데이터 셋이 구성될 때 위키피디아에서 2013년부터 시작된 모든 뉴스를 크롤링해 topic, headline, text, date, hyperlinks로 나눴고 topic을 통해 category를 분류할 수 있게 되었습니다. 총 9,431개의 topic을 얻게 되었고 이를 4,687개의 뉴스로 필터링 하였다고 합니다.(Table 2) 그리고 이러한 category들을 이용해 DSV, CSV, ISV와 같은 영상을 YouTube API로 얻어내고 길이 5분까지로 필터링하여 사건당 48개이하의, 총 225,960 개의 비디오를 얻어내게 되었습니다.

- Query selection
얻어낸 비디오에서 적절한 query를 설정하기 위해 query의 난이도가 높아서 해당되는 category가 아닌 다른 distractor를 가리킬 가능성이 있게 하였으며 NDV 뿐만아니라 CSV 나 ISV 도 포함될 수 있어야 한다는 조건을 설정하였습니다. 이러한 조건을 충족시키기 위해 우선 각 비디오들의 tf-idf 표현 사이에서 cosine similarity를 계산해 visual similarity를 얻어냈습니다. 이를 계산할 땐 NDVR( Near-Duplicate Video Retrieval with Deep Metric Learning ) 에서 제안한 DML network를 사용하였습니다.
그리고 비디오의 제목의 tf-idf 표현 사이에서 cosine similarity를 계산하여 texture similarity를 얻어냈습니다. 이를 위해 NLTK toolkit을 이용해 비디오 제목을 전처리하고 part-of-speech (PoS) tagging을 한 뒤, 동사를 제거하여 NLTK WordNet-based lemmatizer를 통해 제목의 단어 기반 표현을 얻어냈습니다.
이렇게 얻어낸 visual similarity와 texture similarity를 평균내어 전체적인 video similarity를 계산하고 각 비디오간 임의의 threshold로 edge를 구성하여 (본 논문에서는 경험적으로 0.7을 두었다고 합니다.) video graph G를 생성하였습니다. 그리고 graph component를 이용한 후처리 과정을 통해 총 635개의 query 비디오를 얻게 되었으나 annotation 시간이 오래 걸려서 graph component 기준 top 100개만 query set으로 선택하였습니다.
- Annotation process
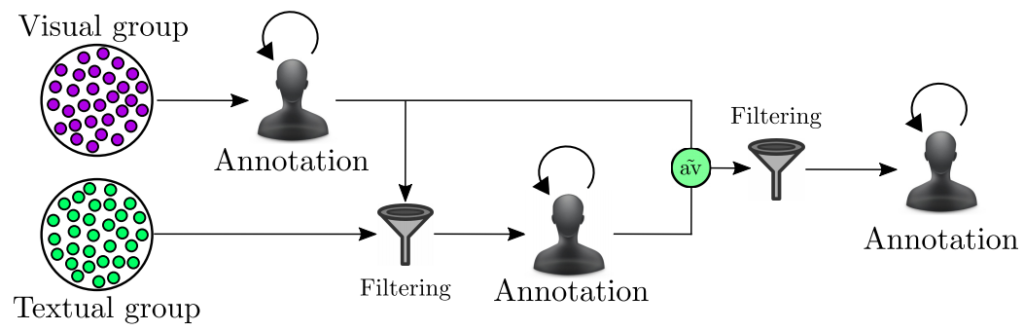
앞서 구한 visual similarity와 textual similarity로 annoation을 하게 됩니다. 우선 visual similarity를 이용하게 되는데 각 query마다 이를 이용해 유사한 비디오를 구별해내게 되고 잘못 구별한 비디오가 100개가 되거나 혹은 유사하다고 구별된 비디오가 1000개가 될때까지 진행됩니다. Textual simliarity도 이와 비슷한 방식을 사용해 걸러진 것들을 annotation 하게 되고 마지막으로 두 정보를 평균내어 필터링 한 후 query 비디오의 일주일 내외로 촬영된 비디오만 다시 필터링하고 annotation 하게 됩니다. 이 과정을 거친 annotation label을 다음과 같습니다.
- Near-Duplicate (ND) : DSV 중 특이한 경우인 NDV를 의미합니다.
- Duplicate Scene (DS) : DSV를 의미합니다.
- Complementary Scene (CS) : CSV를 의미합니다.
- Incident Scene (IS) : ISV를 의미합니다.
- Distractors (DI) : 어떤 경우에도 포함되지 않는 것을 의미합니다.
- Dataset statistics
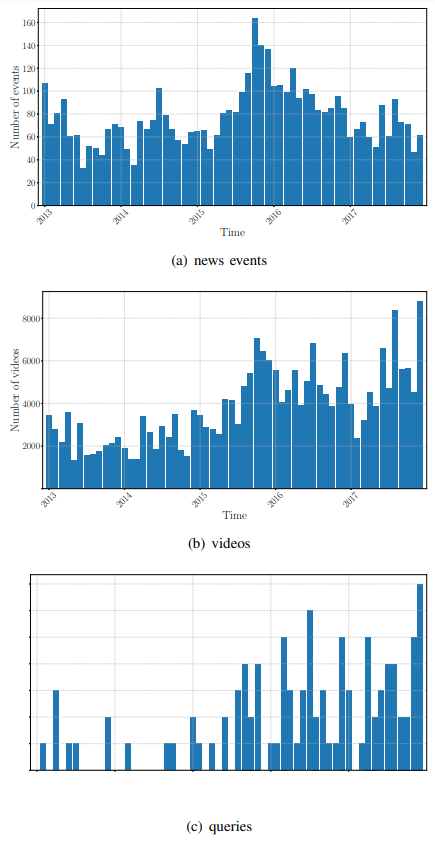
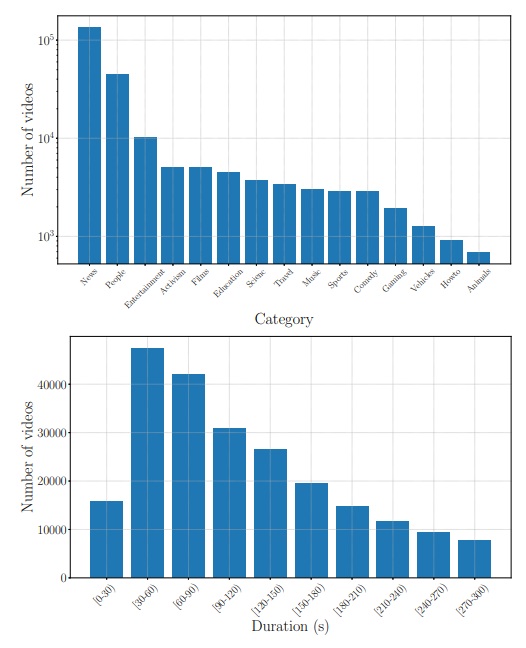
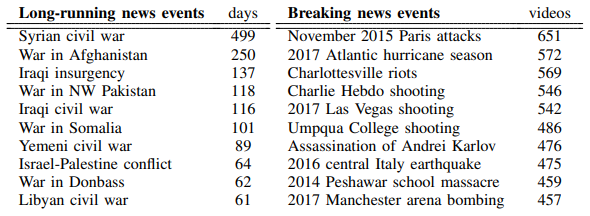
3. Comparative study
- Experimental setup
실험에서 평가를 위해 mAP를 사용하였습니다. 그리고 AP를 다음과 같이 정의내렸습니다.
여기서 n은 query에 유사하다고 뽑힌 비디오의 수(=top-k) 이며, r_{i} 는 유사하게 뽑힌 비디오의 rank 입니다. mAP는 모든 query들의 AP를 평균내어 구했습니다.
- Retrieval tasks
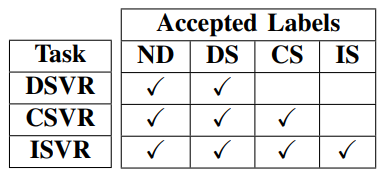
실험을 하기에 앞서 retrieval task를 다음과 같이 세가지로 나눠 정의하였습니다.
- Duplicate Scene Video Retrieval (DSVR) : ND와 DS만 사용한 task 입니다.
- Complementary Scene Video Retrieval (CSVR) : ND, DS, 그리고 CS까지 사용한 task 입니다.
- Incident Scene Video Retrieval (ISVR) : ND, DS, CS, IS 즉, 모든 경우를 사용한 task 입니다.
- Experiments
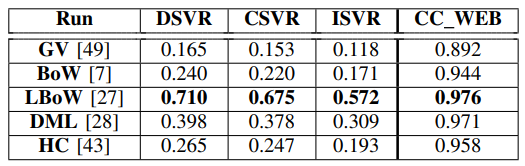
Table 5는 앞서 정한 설정으로 제안된 FIVR-200K 데이터 셋과 별도로 CC_WEB_VIDEO 데이터셋에서 성능을 평가한 결과 입니다. GV는 HSV과 같은 방법론으로 video의 매 프레임마다 히스토그램을 추출해 만든 global descriptor를 의미하고, BoW는 Bag-of-Words, LBow는 CNN feature를 이용한 Bag-of Words 방법론을 의미합니다. DML은 앞서 참조한 NDVR 논문에서 제안한 방법론이며, HC는 Hamming distance를 이용한 Hashing code 방법론 입니다. CC_WEB_VIDEO 데이터 셋과 비교했을 때 낮은 mAP를 보여 좀더 challenging 한 데이터 셋인 것을 확인할 수 있습니다.
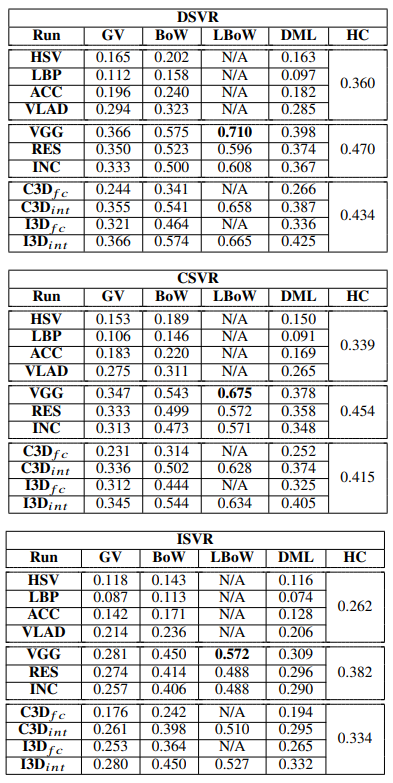
Table 6는 GV, BoW, LBoW, DML, HC를 각각 여러 방법론을 사용했을 때 DSVR, CSVR, ISVR에서의 성능입니다. 상당히 조합 실험을 많이 하였습니다. DSVR에서 CSVR 그리고 ISVR로 갈수록 성능이 점점 낮아지는 것을 확인할 수 있습니다.
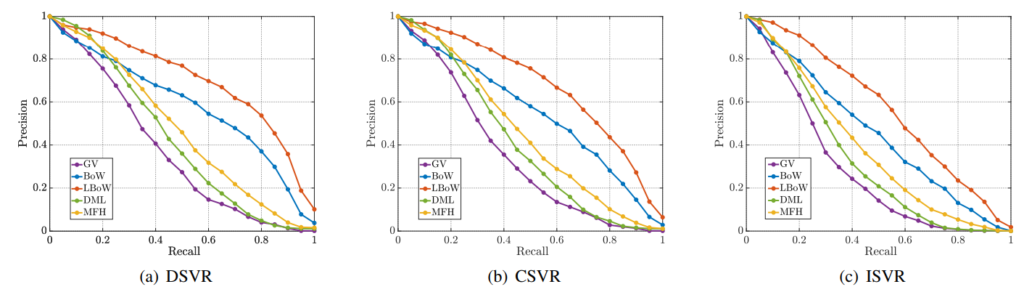
Fig 8은 각 task에서 가장 좋은 성능을 냈던 방법론들의 Precison-Recall 그래프 입니다. 다른 방법론들은 그래프의 모습을 보면 얼추 모든 task에서 유사하게 AP가 떨어지지만 LBoW의 경우에는 하락폭이 큰 것을 확인할 수 있습니다.