저자는 연세대학교 조성배 교수님 입니다.
지금껏 많지는 않더라도, 몇 논문을 읽어 보았는데요, 한국인이 쓴 논문은 IPIU와 RCV랩실 연구원님들의 논문을 제외하고는 처음인것 같습니다.
본 논문은 UCI에서 제공하는 HAR 데이터셋을 사용합니다.
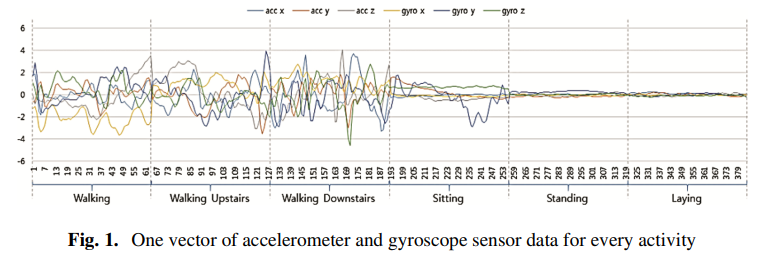
논문이 쓰이기전 SOTA방법론들은 대게 SVM과 같은 ML방식이였는데요, 시퀀셜한 데이터의 특성을 잘 고려해주는 CNN방법을 도입했습니다.
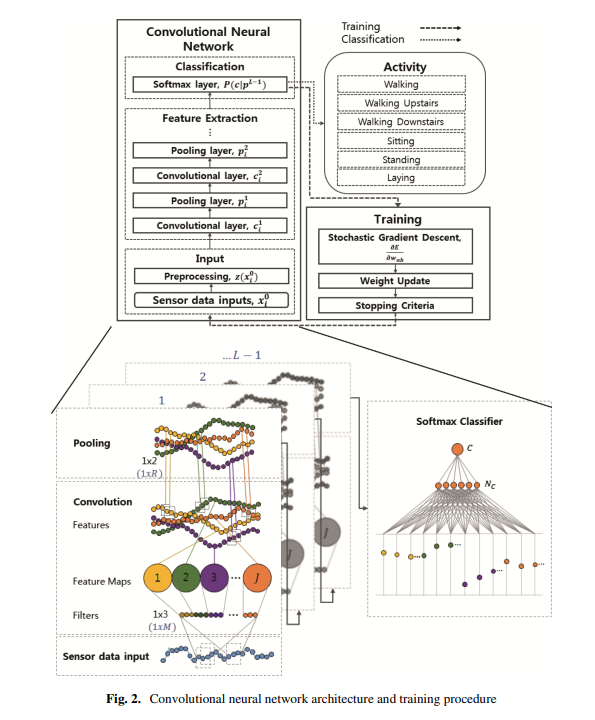
전체적인 모델의 구성입니다.
특별히 새로운 방법론은 제시된것이 없고, 일반적인 convolution layer를 사용합니다.
다만, 지금까지 저는 이미지에 대한 convolution 2d layer 만을 사용해 보았는데요, convolution layer를 통과한 feature map이 2D 이미지 전체의 정보를 내포하며, 좌상단 feature map은 이미지의 좌상단의 정보가 담겨있듯(위치가 깨지지않음)
convolution 1D layer 또한, 시퀀셜한 1D vector의 정보를 아우를 수 있다고 합니다.
Experiments
learning rate = 0.01, momentum = 0.5~0.99 점차 증가
weight decay = 0.00005, maximum epochs = 5000 조기종료
의 조건으로 여러 실험을 진행하였습니다.
Layer의 수를 1~3, Feature map size를 10~200 , filter size를 1×3 ~ 1×15, pooling size를 1×2 ~ 1×15 로 설정하여 다양한 실험을 진행하였습니다.
아래 그래프(fig 4. (b) )를 보면 알 수 있듯, 실험 결과 pooling size는 성능에 큰 영향을 미치치 않았다고 합니다.
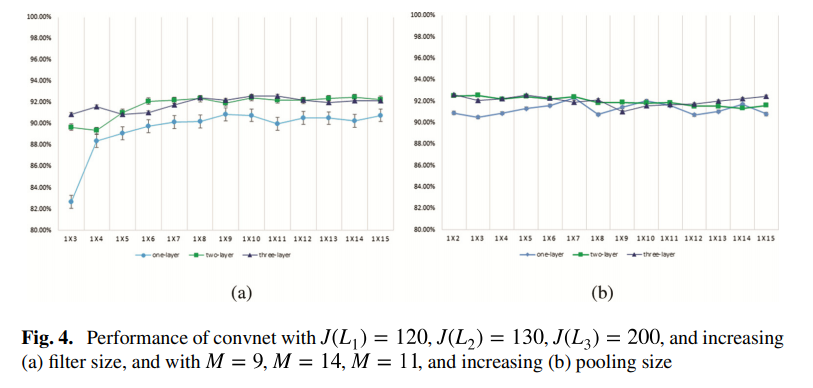
결론은
layer는 3개, filter size는 9, pooling size는 3, feature map 크기는 [96-192-192]-(1000-6),
– 대괄호는 conv 1d layer, 소괄호는 fc layer이다.
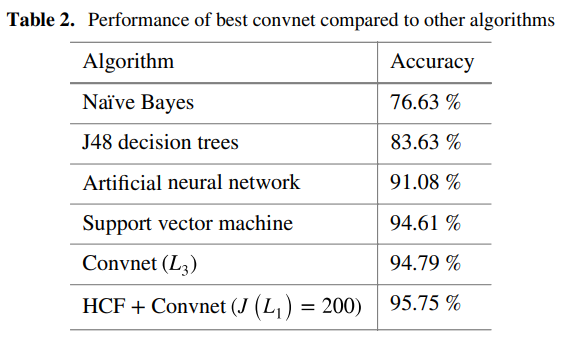
FC layer를 1000 – 6 2개 사용하며 0.8 확률의 dropout을 적용하고, learning late를 0.02로 설정 하였을때, 94.79%로 성능이 가장 높았습니다.
저자가 코드공개를 하지않아 (했는데 내가 못찾았거나) 현재 kaggle notebook을 통해 직접 해당 논문의 코드와 성능을 원복중에 있습니다. 원복을 하는대로 노트북의 링크를 걸겠습니다.
안녕하세요.
한가지 질문을 드리자면 해당 network 구조에 대한 컨셉? 및 내용이 본 리뷰에는 구체적으로 설명 되어있지 않는데, 그 내용에 대한 설명을 간단히 해주실 수 있나요?
논문에도 어떤한 이유로 이러한 network구조를 가졌다 라는 내용은 언급되지 않았습니다.
그저 어떠한 구조의 network를 만들었는지에 대한 내용만 적혀있었는데요, 리뷰에 해당 내용이 적혀있긴하나 직관적인 이해를 돕기위해 직접 network 구조를 그려서 추가하겠습니다.
key contribution이 뭔가요
논문이 쓰이기전 SOTA방법론들은 대게 SVM과 같은 ML방식이였는데요, 시퀀셜한 데이터의 특성을 잘 고려해주는 CNN방법을 도입했다는겁니다.