9월 28일 듣게된 세미나에 대한 리뷰를 작성합니다. 자리를 마련해 주신 교수님과 연구원님들께 감사드립니다.
세미나의 큰 주제는 앞서 다른 연구원님들의 리뷰에서 확인할 수 있듯이 Metric Learning 이였다.
Metric Learning은 유사도를 측정하는 함수를 학습하는 것을 목적으로 하며 기본적인 concept은 유사한 것은 가깝게 다른것은 멀리 하도록 학습하는 것 이다.
1. Metric Learning의 concept을 가장 잘 나타내는 pairwise 기반의 Loss
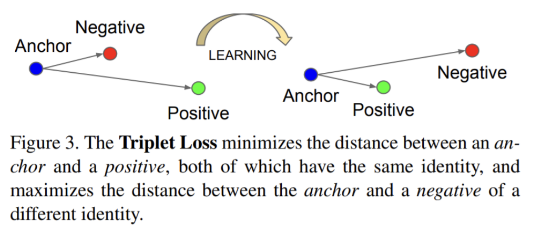
이를 잘 나타내는 matric learning의 loss 중 하나는 Triplet loss로, anchor(고양이라면)를 기준으로 negative(강아지)는 멀게 positive(고양이)는 가깝게 임베딩 할 수 있도록 학습하는 것 입니다. 이렇게 데이터 pair를 가지고 학습하는 기법은 matric learning의 컨셉을 확실히 확인할 수 있지만 pair쌍이 증가할 수록(단순한 anchor-negative-positive 3-pair가 아닌 N-pair(anchor- positive-(N-2) negative )등등 확장될 수 있다) 학습의 복잡도는 증가한다.
2. sampling issue를 해결하기 위한 proxy based loss
proxy based loss 는 pairwise loss의 복잡도가 증가하는 문제를 해결하기 위하여 특정클래스를 대표하는 feature를 얻기 위한 모델을 추가적으로 이용하는 방식이다. 이는 얼굴인식 분야에서 많이 사용되던것이 metric learning 분야로 옮겨온 것이라 한다. pair가 아닌 feature 전체(대표)를 보기때문에 좋지만, 추가적인 모델에서 parameter가 증가하여 class가 너무 매우 많을때에는 부적합하다고 한다.
위 두가지 loss 중 pairwise loss를 잘 학습하기 위한 논문1,2,3을 소개해 주셨다.
먼저 1: Symmetrical Synthesis 방식은 대칭성을 이용하여 hard negative를 생성하여 pairwise loss 학습을 더 잘 할 수 있게 하였고
2: Embedding Expansion 은 내분점을 이용하여 hard negative를 생성하는 방식이라고 한다.
metric learning의 발전 과정 중 pairwise based 분야에서는 hard negative generative 방법이 있다는 것을 알게되었고, 세미나를 듣는 당시 처음 듣는 내용에 집중을 하느랴 추가적인 생각을 못하였는데 다른 연구원들의 리뷰를 보니 기존 선행 연구의 중요성을 많이 언급하였다. 특히 조원 연구원의 글 중 삽질에 관한 느낀점에 매우 공감하였고, 이러한 느낀점을 놓친것이 아쉽다.
두 연구원님께 너무 설명을 잘해주셔서 감사드리고, 교수님께도 다시한번 감사드린다.
Metric Learning과 우리가 기존에 해왔던 classification은 무슨 차이가 있나요?