이번 네이버 세미나에서 다룬 주제는 metric learning 이었습니다. Metric learning이란 주제가 다소 익숙하지 않아 세미나 당시에는 이해하는데 어려움이 있었습니다. 예를 들어, ”이 용어가 뭐였지?“라고 생각하고 있으면 다음 주제로 넘어가서 속도를 따라가지 못했습니다. 그래서 용어 위주로 다시 정리해보고, 세미나 녹화영상과 논문을 참고하여 공부한 후 작성하였습니다. 틀린 내용이나 궁금하신 점은 댓글에 남겨주시면 감사하겠습니다. 해당 리뷰에서는 ‘Symmetrical Synthesis for Deep Metric Learning’ 논문을 다루겠습니다. 그럼 네이버 초청 세미나 리뷰 시작하겠습니다.
<What is metric learning?>
Metric learning이란, 유사한 샘플을 더 가깝게, 유사하지 않은 샘플을 더 멀게 학습시키는 방법론을 말합니다. Loss를 설계하는 방식에는 크게 pair기반과 proxy 기반이 있습니다. 2019 년도까지는 주로 pair기반의 loss들이 제안되었습니다. 그 이유는 굉장히 직관적으로 해석이 가능하기 때문입니다. 그러나 단점으로 pair기반의 학습을 하다보니 training complexity가 높습니다. 이는 곧 학습 training data수가 많고, pair이다보니 더 늘어나게 됩니다. 따라서 sampling strategy에 관한 연구가 많이 있었습니다.
proxy 기반 loss는 어떤 클래스를 대표하는 학습 가능한 feature들을 제안을 해주는 것입니다. 한 번의 미니배치 안에서의 관계만 보던 pair base 보다 모든 클래스를 동시에 볼 수 있게 되는 큰 장점이 있습니다.
<What are the pair-based losses?>
세미나에서 언급한 Pair기반의 loss에는 5가지가 있습니다.
1. Contrastive Loss: 가장 naive한 metric learning의 기본개념에 충실한 loss
2. Triplet Loss: positive와 negative 이미지 동시 비교
3. N-pair Loss: positive 한 개보고 모든 negative에 대해 비교
4. Lifted Structured Loss: negative class를 2장 이상 비교
5. Multi-Similarity Loss: negative 뿐만이 아니라 positive 까지 2장이상 비교
해당 논문에서 이러한 pair 기반의 loss에 symmetical synthesis를 왜 적용했고, 어떻게 적용하는지 아래에서 자세하게 설명하겠습니다.

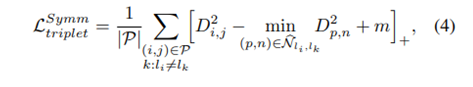
논문에서는 hard sample을 generation하는 novel한 방법을 제안하고 있습니다. 그 방법론은 바로 symmetrical synthesis를 통한 loss의 설계입니다. 위의 식을 보시면 기존 triplet loss term (3)이 (4)식과 같이 바뀐 것을 알 수 있습니다. 이때, similarity를 Euclidean distance로 나타내었기 때문에 min pooling을 해준 것을 보실 수 있습니다. 반면에, cosine similarity 기반의 similarity 탐색에서는 max pooling을 해주게 됩니다. (cosine similarity는 클수록 가까운 것이기 때문)
해당 내용을 좀 더 말로 풀어서 설명하자면 아래와 같은 단계를 거치게 됩니다.
- class로부터 얻은 2개의 이미지로부터 NN을 통과시켜서 feature들을 얻음
- 와 가상공간 상의 가상의 origin을 잡음
- feature를 합성. (feature의 개수는 2배가됨)
4. 페어연산을 하고, 코스트가 높으면 미니멈연산을 해줌(속도up)
5. Hard sample mining을 통해 가장 가까운 것을 뽑아줌. (유클리디안에서는 min pooling, cosine similarity에서는 max pooling이 사용됨)
5번 과정을 통해 얻은 feature는 합성으로 생긴 feature가 될 수도 있고, original feature가 될 수도 있습니다. 이를 사용하면 성능이 향상됩니다.
비슷한 원리로 N-pair, angular, lifted-struct loss에도 symmetrical synthesis를 적용할 수 있습니다. 이와 같은 방식은 network를 설계할 필요없이, 단순 선형대수적인 연산만으로 hard sample을 generation 할 수 있기 때문에 computing speed가 매우 빠릅니다. 또한, 별도의 term 추가없이 기존의 pair기반의 loss에 해당 방식을 접목시킬 수 있어서 활용성이 높습니다. 이렇게 parameter 튜닝없이 선형연산을 통해 간편하게 적용하고 성능향상을 불러올 수 있는게 해당 논문의 contribution입니다.
해당 논문의 내용을 검증하기 위해서 한 실험들입니다. 우선, 왜 하필 많은 방법들 중에서 대칭을 사용했느냐에 대한 실험은 다음 그래프가 잘 보여줍니다.
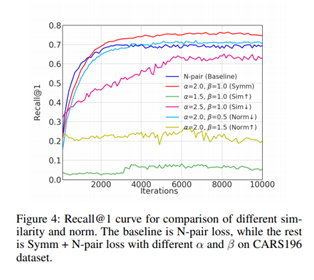
대칭성을 이용하여 학습을 한경우에는 가장 좋은 성능을 보였으나, 그렇지 않았을 때 오히려 성능이 떨어지는 것을 실험적으로 확인했습니다.
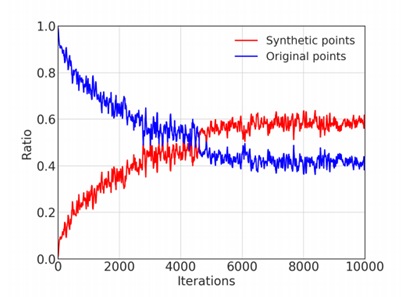
해당 그래프는 hard sample을 어디에서 뽑아오는지 보여줍니다. 학습 초기에는 original feature의 비율이 높은 반면에, 특정 지점을 넘어서부터는 합성 feature의 비율이 높아집니다. 그 이유는 학습초기에는 각각 클래스들의 클러스터링이 능력이 많이 떨어지기 때문에 original feature 자체도 큰 의미를 가지지 않습니다. 따라서 hard sampling mining을 했을 때 합성 feature가 선택될 가능성이 많이 줄어들게 됩니다. 그러나 학습이 진행됨에따라, boundary 쪽에서 주로 hard sample mining이 일어나게되고, 합성 feature가 선택될 가능성이 높아집니다. 이는 곧, hard sample에 대해 더 좋은 성능을 보입니다.

해당 내용을 t-SNE 툴을 default 값으로 이용해서 visualize 한 모습입니다. 빨간점은 대칭을 통해 합성된 feature이고, 파란색은 original feature입니다. Iteration이 작은 학습 초기에는 거의 연관성이 없어 보이는 것을 알 수 있습니다. 그러나 학습이 진행됨에따라 합성된 feature이 original feature과 연관성을 가짐을 알 수 있습니다.
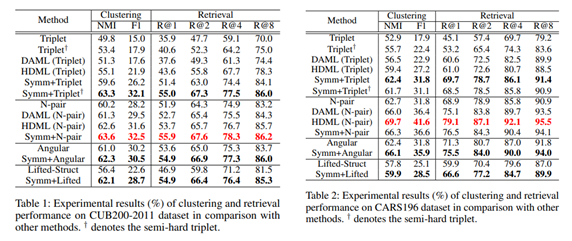
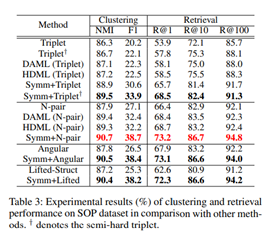
유일하게 CARS196에서의 N-pair에서만 성능이 감소하고 전체적으로 성능이 향상되었음을 알 수 있습니다. 아마도 CARS196에서의 N-pair에서 성능이 감소하게 된 원인은 튜닝의 문제인 것으로 추정됩니다.
‘아는 만큼 보인다‘라는 말이 정말로 맞는거 같습니다. 세미나를 들을 당시에 이해하지 못했던 내용을 학습 후 녹화본으로 다시 보니 이해가 가는 것들이 꽤 있었습니다. 수준높은 세미나를 열어주신 교수님과 네이버소속 두 연구원 분들에게 감사드립니다. 질 좋은 내용을 배울 수 있는 기회였습니다.