저희 연구실에서 진행하는 연구중 메인 연구라고도 볼 수 있는 Multispectral Pedestrian Detection과 관련된 리뷰입니다. 저희 연구실에서 제안하고 있는 AF와 비슷한(?) 내용의 논문들은 무엇인지 찾아보다가 알게된 논문들에 대해서 간단히 이야기해보고자 합니다.
(2018) Illumination-aware Faster R-CNN for Robust Multispectral Pedestrian Detection
해당 논문은 입력되는 영상의 Illumination을 이용해 RGB와 Thermal의 weight를 생성하는 논문입니다. (AF와 비슷하면서 다르네요)

위의 그림에서 왼쪽의 그림은 RGB도 정상적으로 보이는 사진이므로 RGB이미지에 더 큰 가중치를 줘서 Detection을 수행합니다. 반면 오른쪽은 RGB는 Poor한 Illumination을 가지므로 Thermal에 weight를 줘서 Detection을 수행합니다. 그러면 어떻게 이렇게 상황에 따라서 다른 가중치를 생성할 수 있을까요?
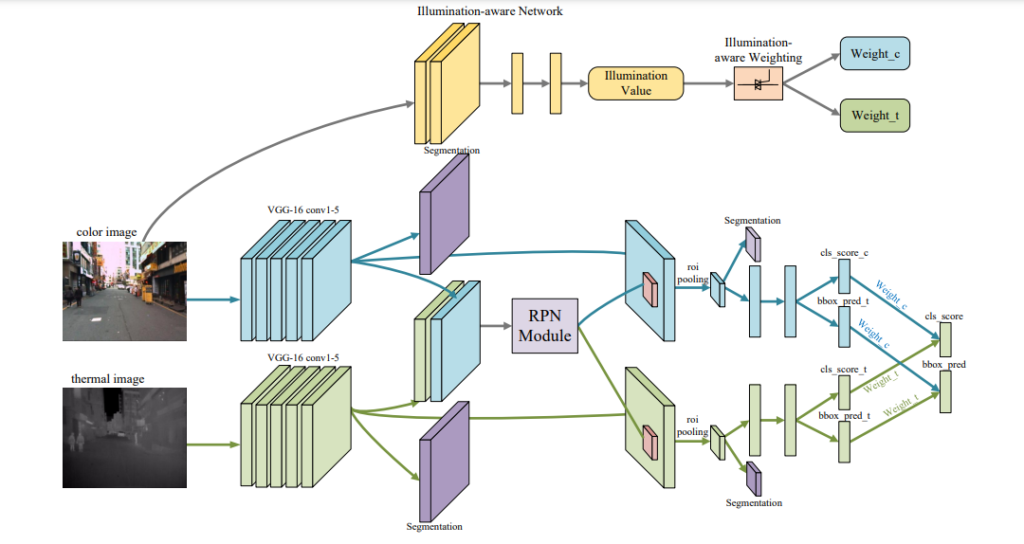
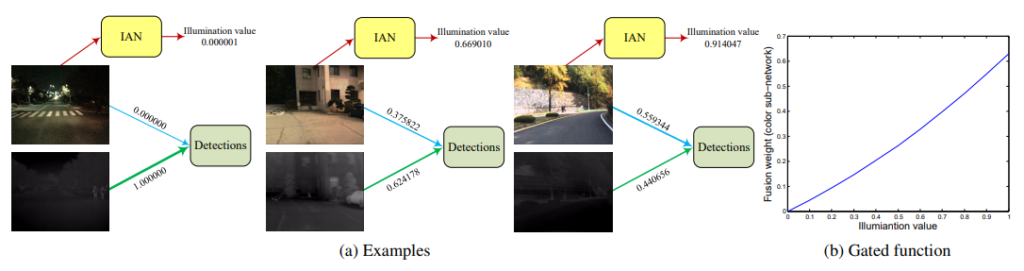
정답은 Illumination aware Network라는 것을 따로 만들어서 해당 네트워크를 통해서 가중치를 만들어 내는 것 입니다. 더 디테일한 내용은 해당 논문을 통해서 확인하실 수 있으며 이번 리뷰에서는 다양한 논문들의 컨셉만 다루겠습니다. 아래 예시 사진을 보시면 좀 더 쉽게 이해하실 수 있습니다.
(2018) Fusion of Multispectral Data Through Illumination-aware Deep Neural Networks for Pedestrian Detection
해당 논문은 위의 설명한 논문보다 약 한달정도 먼저 나온 논문으로 위의 논문과 비슷한 컨셉을 가지고 있습니다.
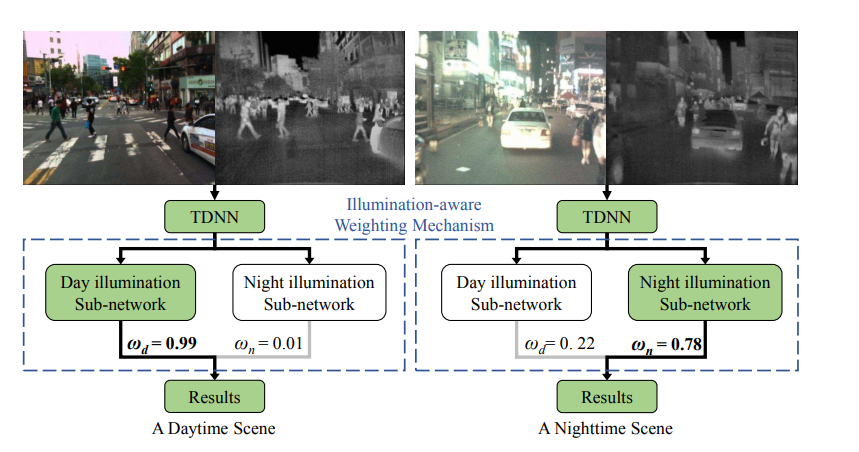
해당 논문에서는 각가 Day, Night 상황에 대한 Illumination을 계산하기 위한 Sub Network를 만들고 이를 통해서 퓨전을 수행하게 됩니다.
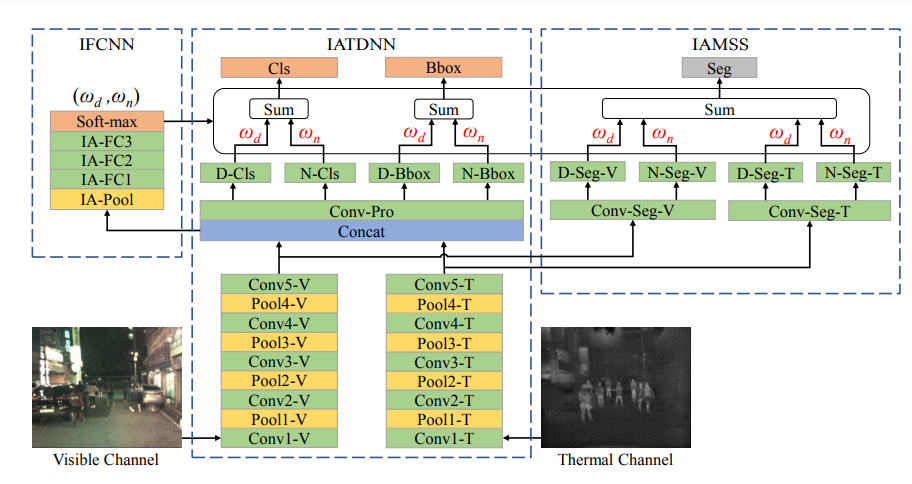
실제 아키텍처를 보면 많이 복잡해 보이지만, 해당 논문에서 제안하는 핵심 컨셉은 위에서 설명한것과 같이 Day,Night에 대해서 각각 SubNetwork를 따로 둔다는 점 입니다. 해당 논문에서는 Detection 뿐만 아니라 Segmentatioin에서도 작동함을 나타내고 있어서 위의 아키텍처를 보시면 IAMSS도 함께 나타내고 있습니다.
(2020) Attention Based Multi-Layer Fusion of Multispectral Images for Pedestrian Detection
앞서 논문들은 Illumination을 통해서 가중치를 계산했다면 해당 논문은 channel-wise attention module (CAM) and a spatial-wise attention module (SAM) 을 통한 퓨전 방법을 제안합니다. 아래 그림은 전체 아키텍처 입니다.
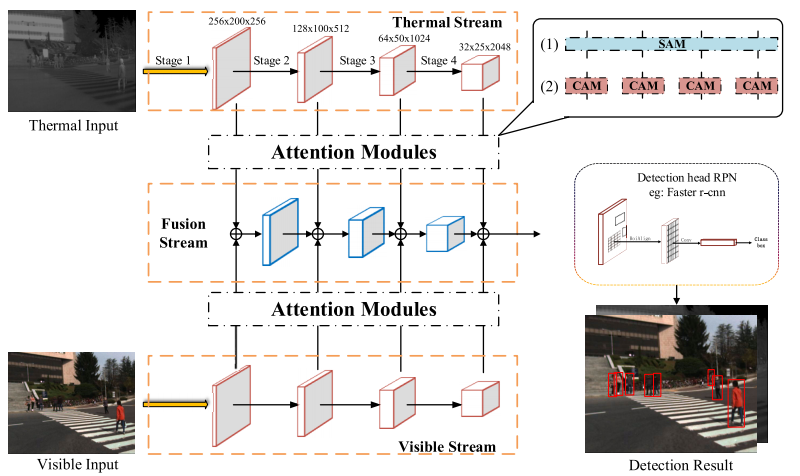
먼저 channel-wise attention module (CAM)는 fusion 이전에 유용하고 유의미한 채널은 보존하고 방해( interfering )가 되는 채널은 제거하는 역할을 수행합니다. 해당 모듈은 ‘Squeeze-and-excitation networks(SE)‘를 수정하여 만든 모듈입니다. 정리하면 피처맵의 압축과 재조정을 과정을 통해서 유의미한 채널들만 남기는 모듈입니다. (자세한 SE Network의 설명은 위의 링크를 클릭하시면 됩니다.)
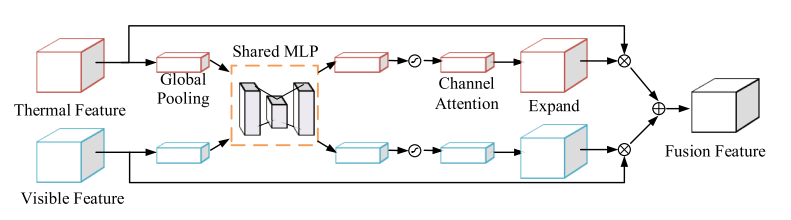
spatial-wise attention module (SAM)는 Salient Object detection(SOD)를 기반으로한 방법론 입니다. SOD란 쉽게 배경과 객체만 분리해서 나타내는 Detection이라고 생각하면 됩니다. CAM이 어떤 채널이 Detection에 유의미한 지 나타냈다면 SAM은 각 피처맵에서 어느 위치가 유의미한지, 그리고 더 많은 정보를 가졌는지를 얻을 수 있습니다.
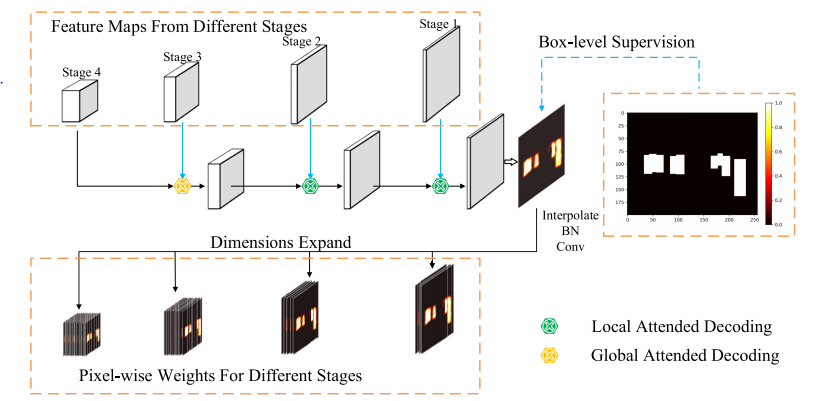
정리하면 다음과 같습니다. 아래와 같이 Detect하는 과정을 기존 방법론과 비교해설명하면 다음과 같습니다.


기존 방법은 위에서부터 보시면 가장 위는 input 이미지, 그 다음은 input 이미지에 따른 spatial attention map 입니다. 그리고 다음은 Input 이미지에 대한 feature map 입니다. 그리고 이를 spatial attention에 따라서 weight feature을 만들고, 이 둘을 sum을 통해 fusion 하게 됩니다.
이와 다르게 해당 논문에서 제안하는 방법론의 메커니즘은 다음과 같습니다.

비교하면 Spatial attention map은 더 확대됐고, 밑에 sum이 아닌 CAM을 통해서 선택적인 feature map들이 합성됨을 볼 수 있습니다.
자 여기까지 Multispectral Pedestrain Detection을 위한 많은 연구들이 이뤄지고 있으며, 각 연구들은 RGB, Thermal 이미지 fusion을 위해서 어떻게 연구를 했는지 알아봤습니다.
Illumination이 무엇인지 잘 이해가 가지않는데,설명 부탁드립니다. 또 데이터셋이 낯익는데, 카이스트 데이터셋 맞나요?
넵 카이스드 벤치마크 데이터셋이며, Illumination 은 밤과 낮에 나타나는 조도차이라고 이해하시면 됩니다.
앞의 두 논문은 이미지 전체에서 Illumination을 계산하여 합하는 것이고 마지막 논문의 경우 CAM이나 SAM을 이용하여 압축한 feature를 합하는 것인가요? CAM도 SAM 처럼 위치정보를 제공할 수 있을 것 같은데 CAM은 위치정보로 이용하지 않는다는 점이 신기하네요..