이번 KCCV Review에서는 KCCV 라이브세션 마지막 발표였던 Learning Disentangled Representation for Robust Person Re-identification에 대해서 다뤄보겠습니다. KCCV에대한 전체적인 Review를 쓰면, 일기형식으로 될거같아서 특정주제 한개로 국한한 점 이해부탁드립니다.
https://www.youtube.com/watch?v=SdjvMlY9Kv8&feature=youtu.be
본 리뷰에대한 LIVE session은 해당 링크(7:43:40 ~ 끝) 부분을 참고하시면 됩니다.
본격적인 내용을 설명하기에 앞서 , 우리는 disentangled라는 용어에 대해서 알아볼 필요가 있습니다. Disentangled는 최근 CV학회에서 많이 다뤄지는 핫한 주제입니다. 먼저, 해당 단어의 사전적의미는 아래와 같습니다.
1. (혼란스러운 주장·생각 등을) 구분하다
2. (얽매고 있는 것에서) 풀어 주다
그렇다면, CV에서 disentangled는 어떤 의미로 사용될까요? Disentangled란 용어는 주로 feature를 나타내는 descriptor와 같이 사용됩니다. 기존 descriptor들은 feature 전체를 나타내는데 국한됐지만, 최근 CV학회에서는 부분별로 descriptor를 다른방식으로 표현합니다. 즉, descriptor를 바꿈으로써, 물체의 pose, 옷의 색, 성별 등을 바꿀 수 있게 됩니다. 이번에 리뷰하게될 연구에서는 해당 disentangled 개념을 re-identification을 하는데 활용합니다.

해당 리뷰의 내용은 연세대학교 함범섭교수님의 연구이며, KCCV발표에 사용된 PPT 및 논문내용임을 미리 밝힙니다.
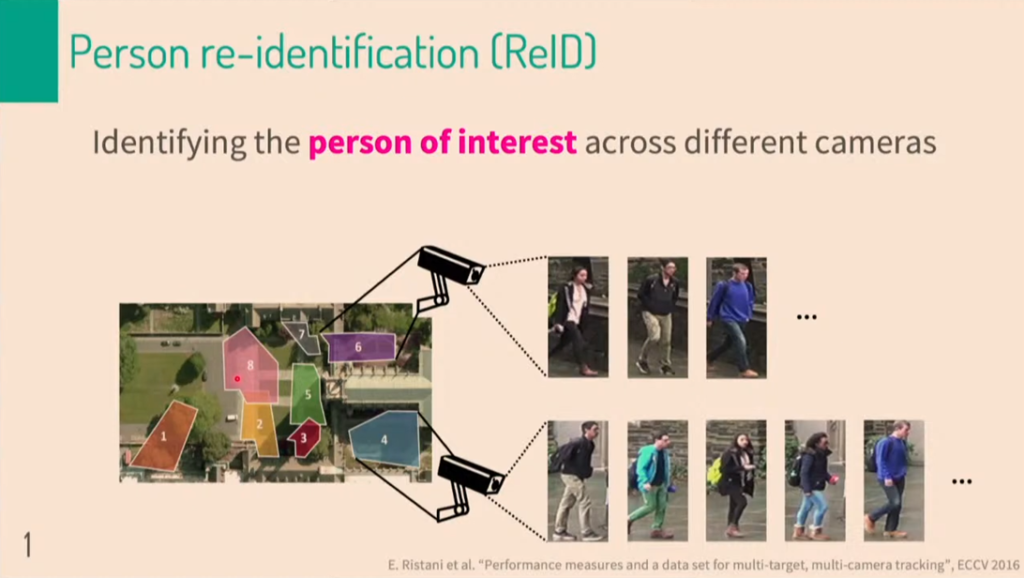
위에서 disentangled란 개념에대해서 간략하게 소개했습니다. 그렇다면, re-identification은 무엇일까요? 아마 re-identification이란 용어가 생소하신분들이 많으실 겁니다. 줄여서 ReID라로도 하는데 이는 image retrieval 이랑 일맥상 통합니다. 위에 보시면, 여러 구역에서 찍은 CCTV data가 있습니다. CCTV data안에는 사람들의 identification이 담긴 이미지정보가 들어가 있습니다. 여기서 생각해봐야할게 7번 CCTV에 찍힌 사람이 4번 CCTV에도 등장 할 수 있습니다. 사람은 동일사람인걸 쉽게 인지하지만, 기계가 인식하기에는 상당히 어려운 일 입니다. 이를 가르켜 re-identification이라고 합니다.
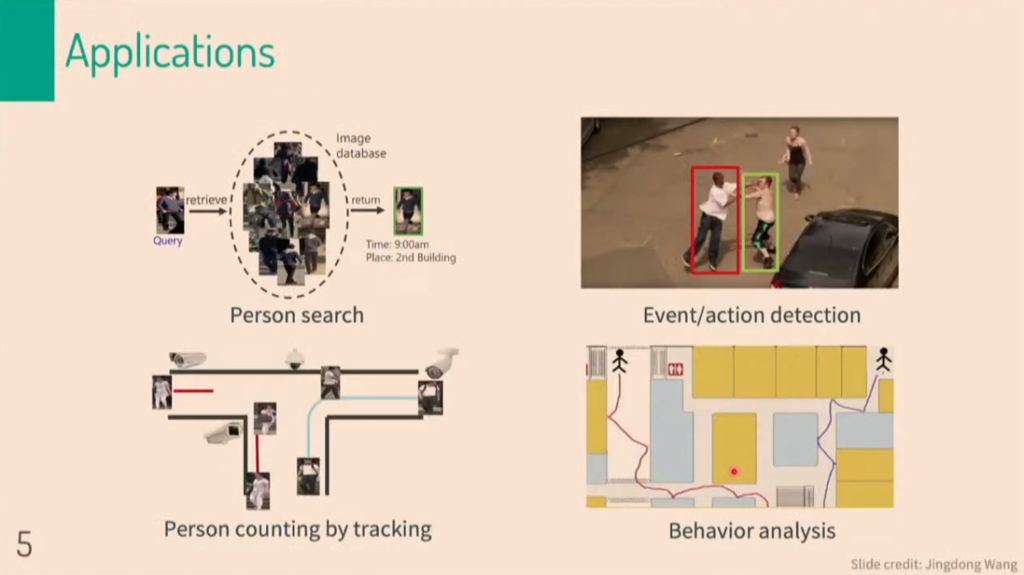
우리는 범죄, 미아, 치매노인 등의 문제를 해결하기위해 CCTV data에서 query data를 찾고자 합니다. 이때, query data는 찾고자하는 사람의 identification이 담긴 image입니다. Image 자체를 사용하기에는 pixel단위로 너무나도 연산량이 많고 비효율적이기때문에 descriptor를 정의해야합니다. 즉, query image에 대한 descriptor를 추출하고, 기존에 CCTV 데이터상에 존재하는 descriptor들과 비교하여 image retrieval을 수행합니다.

그러나, illumination, pose, background가 계속 바뀌기 때문에 기계에게 있어서 re-identification을 하기에는 쉽지않습니다. 해당 방해요소들에 robust하게 re-identification을 수행하기위해 아래 소개하는 방법들을 사용합니다.

Backgound의 변화에 robust하기 위해서 attention이란 개념을 도입합니다. Attention이란, query image와 train image에서 동일한 부분에 좀더 attention을 주는 것을 의미합니다. 즉, 사람 형상에 대해서 attention하고, background를 최대하 제거하겠다는 의미입니다. 이 방법론은 image retrieval을 하는 과정에 자주 등장하는 방법중 하나라고 합니다.
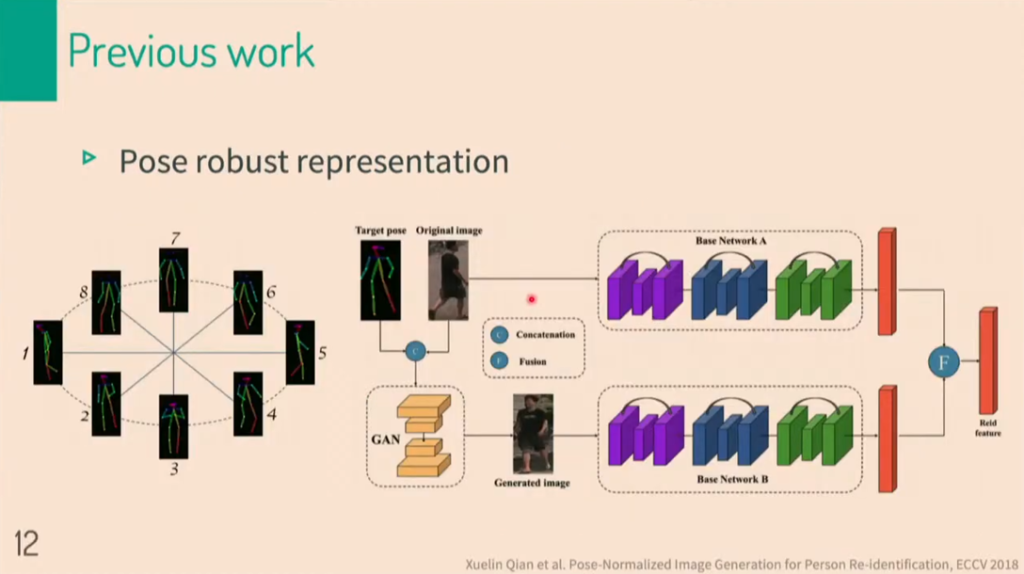
다음으로 pose의 변화에 robust하기 위해서 pose정보를 담고있는 descriptor를 사용합니다. Original image와 pose 정보를 concatenate한 다음, GAN을 태워주면 그림에서와 같이 generated imaged가 만들어집니다. Generated image와 original image의 identification 정보는 같음을 이용하여 training합니다.
해당 연구에서는 image retrieval을 하는 과정에 disentangled representation이라는 개념을 도입합니다. 즉, feature들을 identification과 관련있는 것과 아닌 것으로 나눕니다.
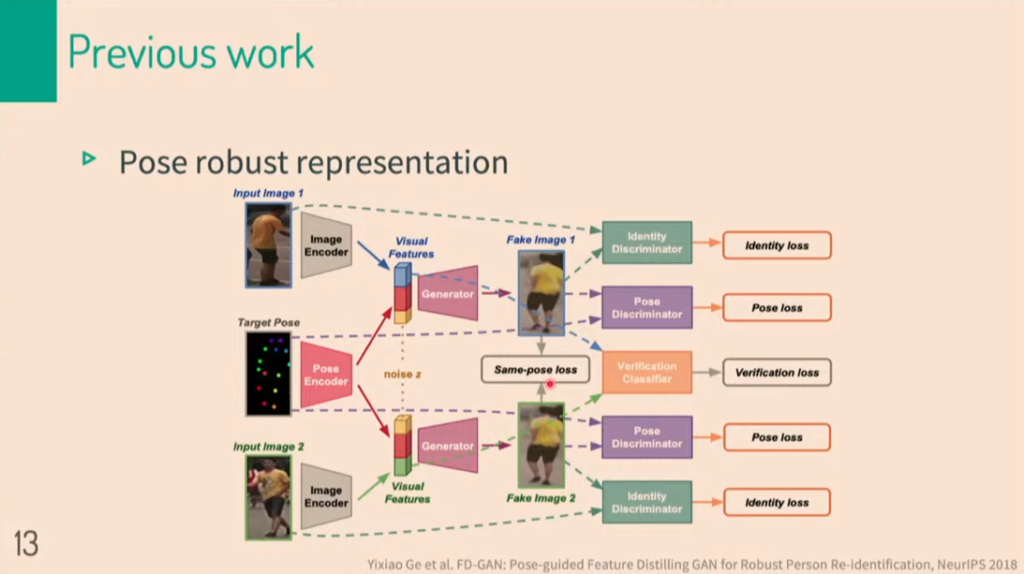
해당 논리대로라면, identification은 같으나 포즈가 다른 2개의 이미지를 concatenate한 후 generator를 통과시키면 같은 형상의 이미지가 형성될 것 입니다.
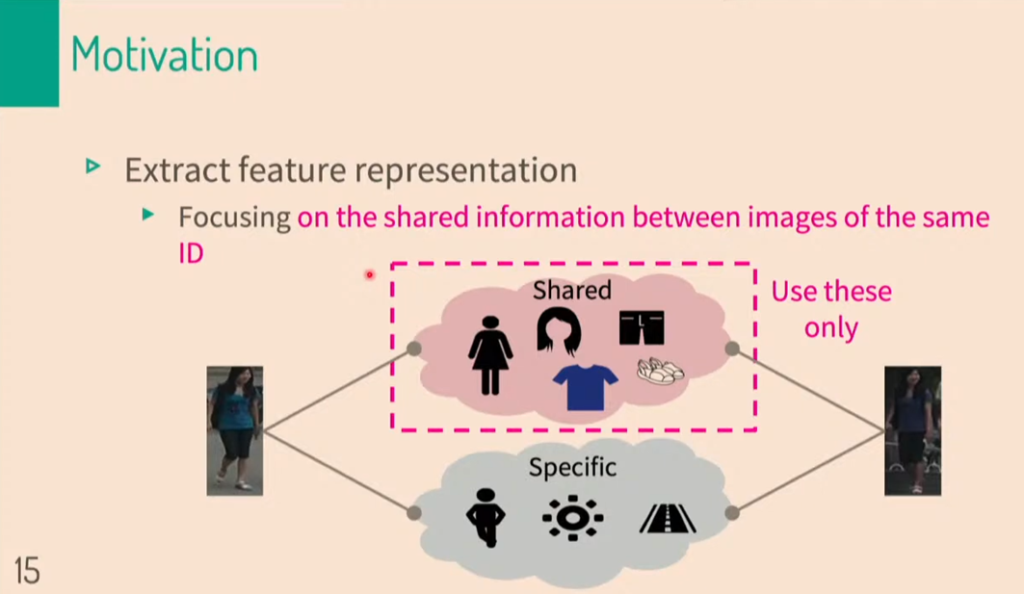
해당 논문에서는 identification을 나타내는 feature들과 identification과 관계없는 feature들을 나누었습니다.
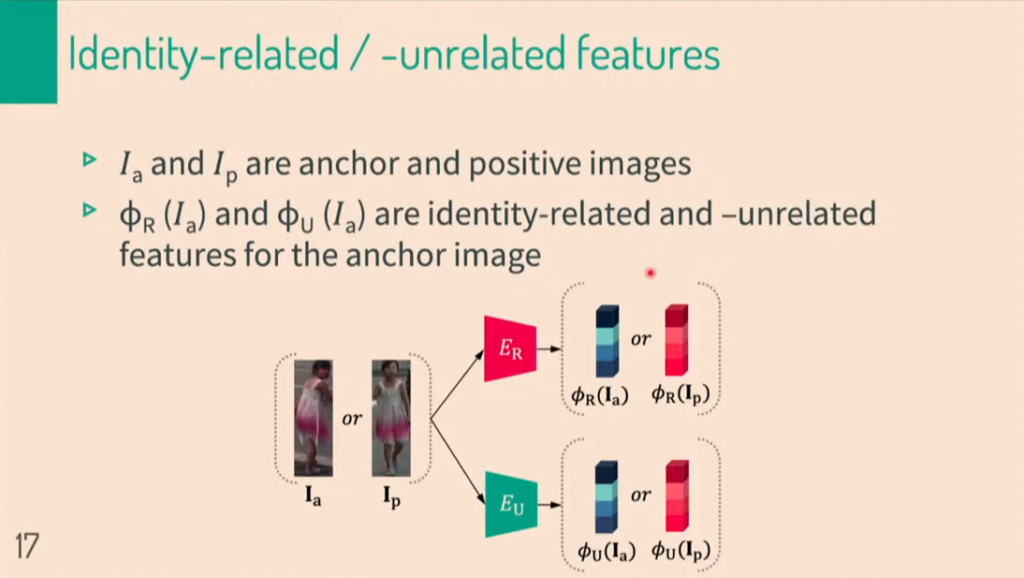
a, p 하첨자는 각각 anchor, positive image를 뜻합니다. E는 encoder를 뜻하며, CNN 네트워크로 이루어져있습니다. R은 related, U는 unrelated를 뜻합니다. 해당 그림을 보시면, anchor image 혹은 positive image가 어떤식으로 나누어지는지 보여주고 있습니다.
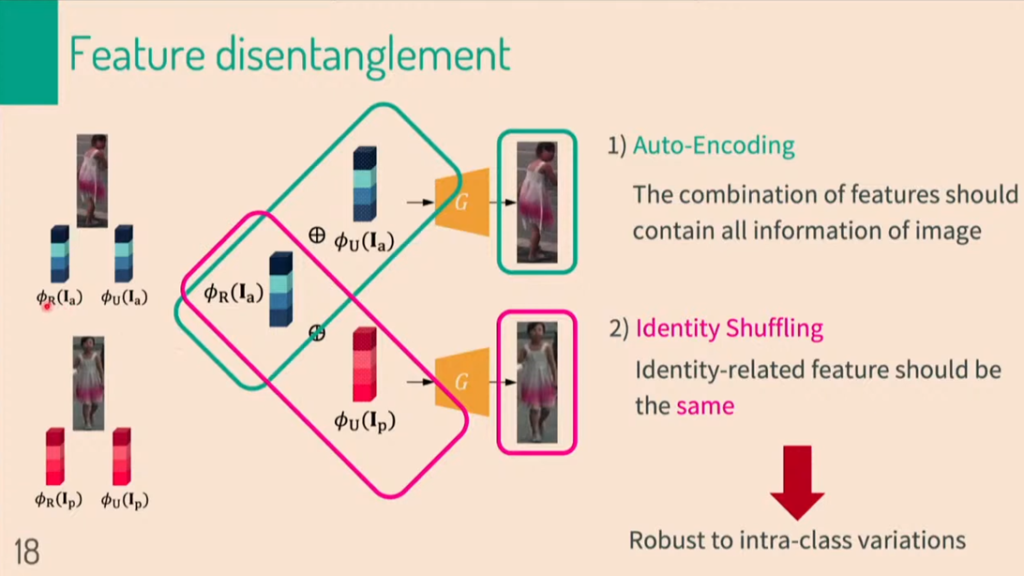
Anchor image와 positive image의 identification이 같으나, unrelated feature가 다르다면, 위의 그림과 같은 상황일 것입니다. generator를 통과하면, 합쳐진 이미지가 생성됩니다.

고려한 것들이 많은 만큼 loss term이 많습니다. 총 6개의 loss를 사용했습니다. 처음부터 6개의 loss를 한번에 학습시키는 것은 상당히 어려운 일 입니다. 따라서 해당 연구에서는 6개의 loss를 1개씩 따로 학습시킨 후 최종적으로 6개를 동시에 학습시켜 미세조정 하였습니다.
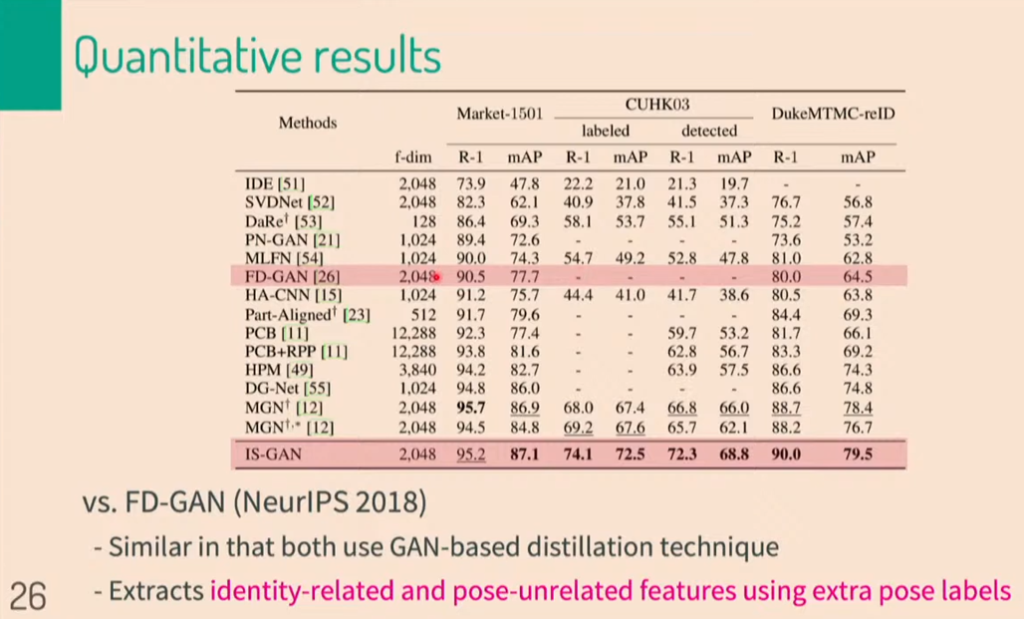
그렇게 해서 얻은 결과물 입니다. 기존 방법론중에서 많이 쓰는 FD-GAN과 같은 dimension의 feature를 사용했음에도 불구하고, 더 좋은 정량적 성과를 냈음을 알 수 있습니다.
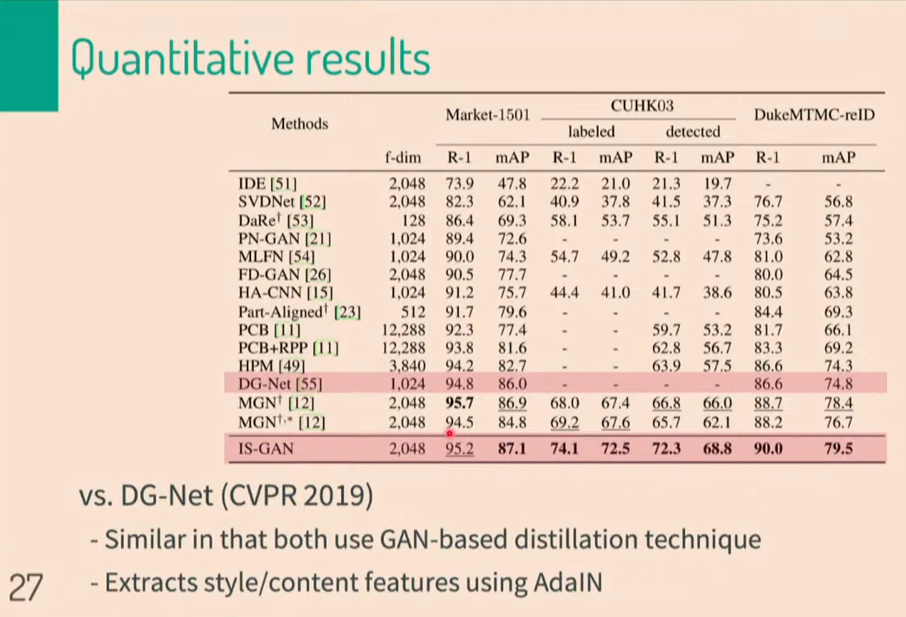
이번에는 DG-Net과 비교 해보겠습니다. 더 높은 차원의 feature를 사용하긴 했지만, 정량적으로 볼때, 더 높은 성능을 달성했습니다. 이로써, sate of the art를 달성 했습니다. 방법론적으로 볼때, DG-Net에서는 style과 content기반의 feature를 사용한 반면에, 해당 연구에서는 related feature와 unrelated feature들을 사용 했습니다.

정성적 평가에서도 좋은 결과를 냈음을 알 수 있습니다.
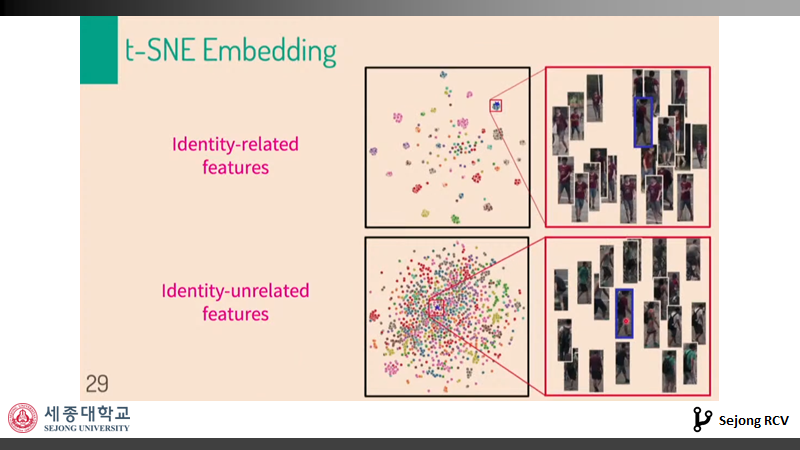
T-SNE 평가에서도 같은 identity를 가지고, pose와 background 정보 등이 다른 identity-related features가 한곳에 몰려있었습니다. 또한, identity-unrelated feature는 같은 pose를 하고 있는 다른 identity의 사람들과 몰려있는 것을 알 수 있었습니다.

그리고 각종 실험에서 각 종류의 feature들을 바꿔가며, identity-related feature와 identity-unrelated feature가 바뀜에 따라서 해당 특징들이 바뀌었습니다. 예를들어, 오른쪽 사진을 보시면 identity-related feature는 고정되어있으므로, identity와 상관없는 scale이 바뀜을 알 수 있습니다.

이와같은 원리는 image를 분할하여 partially 적용을 해봐도 같은 결과를 가지고 옵니다. 이는 disentangled representation이 왜 중요한지를 보여줍니다. disentangled representation을 위한 feature를 자유자재로 다룰 수 있다는 것은 image에 대한 feature를 보다 정밀하게 컨트롤 할 수 있음을 의미합니다. 이로써 , KCCV에서 소개된 disentangled 와 관련된 연구를 살펴보았습니다.
사실 이번주에 loss에 대한 내용을 주말동안 공부 후 좀 더 심도있게 다루고자 했는데, 이사관계로 분량을 소화하기 힘들어서 2주 후로 미루었습니다. 새로운 지식을 습득하는 재미로 저의 리뷰를 기대하셨던 분들에게 죄송합니다. 다음주는 네이버세미나?에 관한 리뷰를 작성하므로 힘들거 같고, 2주 후에 disentangled에 대해 좀더 깊게 다뤄보고, loss항 중 특히 KL divergence loss에 대해 다루어 보겠습니다.
제 리뷰가 도움이 되었으면 좋겠습니다. KCCV 라이브세션과 정규세미나의 제 발표영상을 참고하시면 더 도움이 되실겁니다. 글 읽어주셔서 감사합니다.
좋은 글 감사합니다.
질문 하나만 드리자면, 본 글 내용 중 background의 영향을 제거하기 위하여 attention 기법을 사용한다고 나와있습니다.
query와 train image에서 동일한 부분을 찾아서 attention한다는 컨셉은 이해가 되지만, 어떤 방식으로 구현하는지는 감이 잘 안잡혀서 그러는데, 혹시 어떤 방식으로 작동하는지 설명 해주실 수 있으신가요?
관계 있는 정보와 관계 없는 정보를 나눌 때 어떤 기준으로 나누는 지 알려주실 수 있을까요? 따로 pixel level의 segmentation을 줘서 supervised 하게 알려주는 것일까요?