해당 논문은 최종적으로는 같은 클래스이지만 다른 사례가 담겨진 영상으로부터 같은 부분을 찾을 수 있도록하는 semantic correspondence를 찾는 방법론입니다. semantic correspondence에 대한 예를 들자면 다양한 인종의 얼굴간의 눈, 코, 입처럼 특징을 매칭시키거나 그림 1과 다른 종류의 차종으로 부터 전미등, 바퀴, 백미러처럼 특징적인 부분을 매칭 시키는 것을 의미합니다.


그렇다면 semantic correspondence는 어떤 태스크에서 사용이 가능할까요? 그림 2에서 그 예시들을 찾아 볼 수 있습니다. 영상에 존재하는 물체의 첫번째 영상에만 semantic mask(label) 정보가 주어진 상태이고 다음 영상부터는 semantic label이 주어지지않은 Non-parametric Scene 문제를 풀고자 할 때 예시를 들 수 있습니다. 이는 semantic correspondence를 알면 다음 영상에서 물체의 위치가 어디 있는지 알 수 있으며 해당 정보를 토대로 semantic mask를 전달할 수 있게 됩니다.
특히 colorization인 경우 사람의 입, 눈, 코 등 semantic한 정보를 알아내고 각각의 정보를 correspondence를 잡아 color를 전파하는 용도로 많이 사용됩니다.
또는 Co-sementation처럼 여러영상 혹은 동영상에서 같은 물체 혹은 같은 클래스인 물체를 segmentation을 할때 사용됩니다.

위와 같은 task에서 사용이 가능한 semantic correspondence 문제는 그림 3.과 같이 photometric deformations 과 geometric deformations 관점에서 문제를 정의할 수 있습니다. photometric deformations은 예를 들어 그림 3.과 같이 같은 클래스인 차량이 있지만 사진상 다른 현상으로 보이는 것들(e.g. 후미등, 바퀴)등을 어떻게 찾아 매칭을 시킬 것인가? 에 대한 정의입니다. geometric deformations은 기하학적인 변화인 경우 연속적인 영상뿐만 아니라 다른 뷰에서 찍은 영상에서 조차 semantic correnspondece를 찾아내야 합니다.
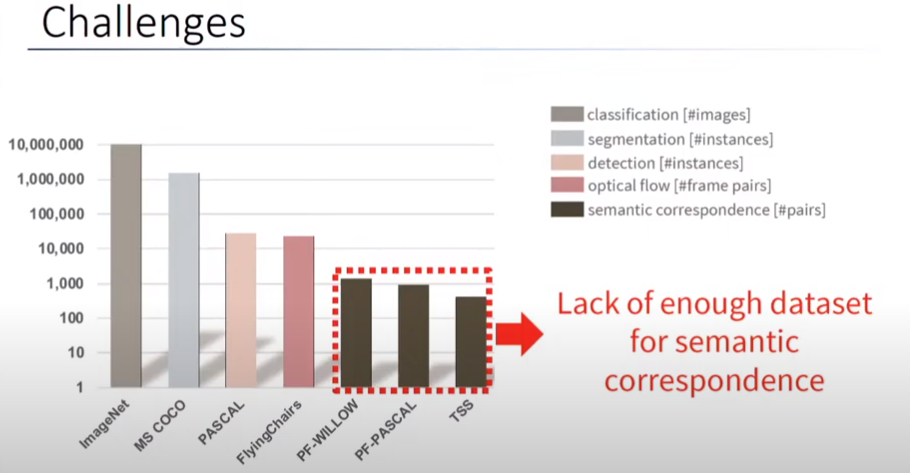
하지만 semantic correspondence 을 풀기에 보다 근본적으로 해결해야 하는 문제가 존재합니다. semantic correspondence는 다른 task에 비해 현존하는 dataset도 매우 부족한 상황입니다. 이는 dataset을 만들기가 매우 까다롭기 때문인데요. 예를 들어 차라는 클래스에 대한 semantic correspondence에 대한 승용차에 대한 dataset을 만들려면 k5, k7, k9, 아반떼 등등 많은 다른 회사, 차종에 대한 mask를 진행하고 각각에 대한 대응점을 정의하여 라벨링을 진행해야하기 때문에 많은 어려움이 존재합니다.
그렇기에 대부분의 semantic correspondence 연구들은 supervision이 아닌 방법으로 진행되어 왔습니다. 이전의 연구에서는 source 영상을 인공적인 변형을 한 target 영상을 학습된 모델에 넣어 source 영상과의 차이가 작아지게 하는 방법을 이용해 학습해왔습니다.

이전의 연구들은 인공적인 변화를 원복하는 방식을 이용하기 때문에 부자연스러운 과정이 있었습니다. 하지만 해당 연구에서는 이러한 문제를 해결하기 위해서 Object ladnmark detection과 Semantic alignment를 joint learning을 합니다. 해당 방법을 간략하게 설명드리자면, source와 target으로부터 랜드마크를 검출하고 semantic alignment에서 얻은 와핑 정보를 토대로 target의 랜드마크를 와핑이 잘되도록 반복한다면 supervision이 필요 없으며 인공적인 변화가 없는 학습이 가능하게 됩니다.
Method
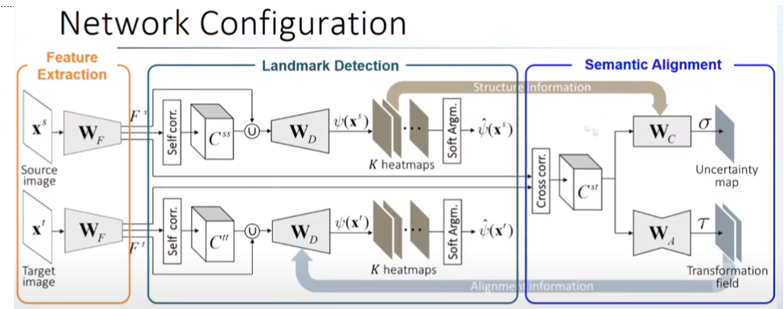
Feature Extraction
구체적인 방법은 모델의 구조(그림 6. )를 보면서 진행하겠습니다. 우선 Feature Extraction으로 부터 feature를 추출합니다. 여기서의 모델은 VGG16(conv4-4) 혹은 ResNet(conv4-23)을 사용합니다.
Landmark detection
그 후 source와 target의 feature map으로 부터 self-similarity(식 1)를 구합니다. 그 다음 디코더를 통해 k 개의 heatmap을 얻습니다. 각각의 k 개의 heatmap은 soft argmax를 통해 k 개의 랜드마크를 추출합니다.
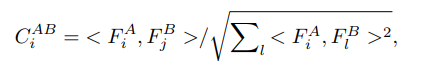
Semantic Alignment
Semantic Alignment 부분에서는 Feature Extraction을 통해 얻은 source와 target의 feature map으로부터 cross correspondences를 구하고 식 1로 부터 volume을 만든 다음 W_A(encoder-decoder)를 통해 Transformation field \tau를 구합니다. 추가로 대응점에 대한 맞는지에 대한 예측 정보가 담긴 W_c(Conv) Uncertainty map \sigma을 구하게 됩니다.
Loss
Loss for semantic alignment networks
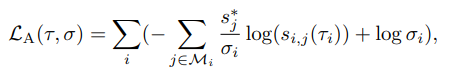
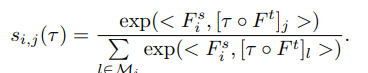
Loss for semantic alignment networks 는 기본적으로 cross-entropy loss를 base loss로 사용하며 source와 transformation filed \tau가 고려된 target 간의 similarity가 고려된 soft-max를 통해 얻어집니다. 하지만 이러한 방법은 위치 정보가 엄격하게 주어져야하기 때문에 Uncertainty map \sigma로의 점수가 너무 높을 시에는 loss를 크게 낮춰 고려하지 않도록 하는 것이 특징입니다.
Loss for landmark detection networks
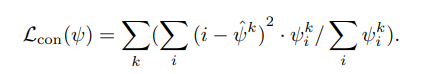
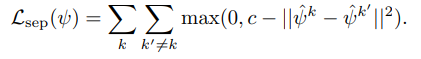
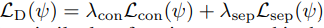
landmark detection networks에 대한 loss는 랜드마크의 정보를 가진 heatmap의 분포를 작게 만들어 모아 가장 특징점을 찾는 식 4와 각 heatmap의 거리를 넓히는 hinge embedding loss (식 5)로 구성이 되어집니다. 최종적으로는 landmark loss(식 6)으로 구성이 되어지며, 랜드마크 방법론에서는 흔하게 사용되는 loss라고 합니다.
Loss for joint training
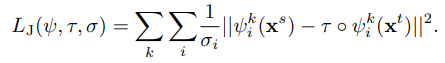
식 7은 랜드마크의 위치에 /tau로 와핑을 시킬 시 같은 위치를 찾도록 고려한 식이며, /sigma는 식 2와 동일하게 Uncertainty 가 너무 높으면 loss 값을 고려하지 않기 위해 사용됩니다. 해당 식을 통해 randmark detection network와 semantic alignment network는 두 결과값이 고려된 loss를 가진 joint learning을 하게 됩니다.
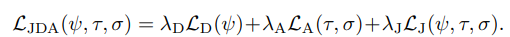
최종적으로 식 8의 loss가 사용되어지며, 효율적인 학습을 진행하기 위해 각각의 네트워크는 독립적인 학습을 진행한 후(각각의 task에서 pre-trained model을 사용), 보다 나은 초기화를 위해 semantic alignment network와 landmark detection network를 교대로 학습을 진행합니다. 사용되는 이미지는 인공적인 변화를 준 영상 쌍을 학습을 진행합니다. 초기화를 진행한 후, JLAD dataset을 통해 각각의 하이퍼 파라미터 \lamda 들은 semantic alignment 에서의 {W_F ,W_A,W_C }는 {λD, λA, λJ } 가 각각 {1,10,10}를 사용했으며, landmark detection 에서의 {WF ,WD}는 {λD, λA, λJ }가 각각 {10,1,100}을 적용된 상태로 end-to-end로 학습을 진행합니다.
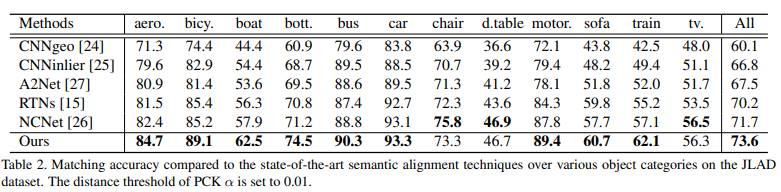
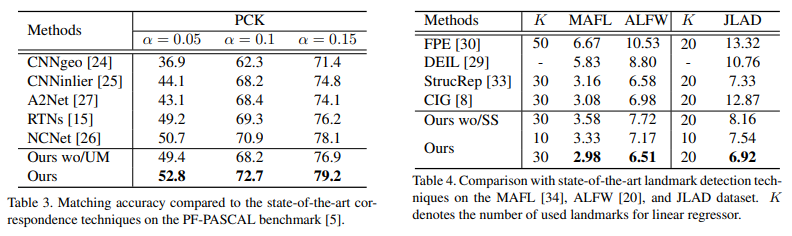
Experimental Results