KCCV 당시 막 Etri 작업에 들어가게 되어 정신이 없어 제대로 다 챙겨보지 못한점이 아쉬움으로 남아 있습니다. 그래서 그 당시 들었던 발표들 외에 현재 녹화되어 있는 자료를 통해 당시 못 들었지만 굉장히 흥미롭게 봤던 주제를 이야기 해보고자 합니다.
박사 콜로키움
- Few Shot learning(김준식 KAIST)
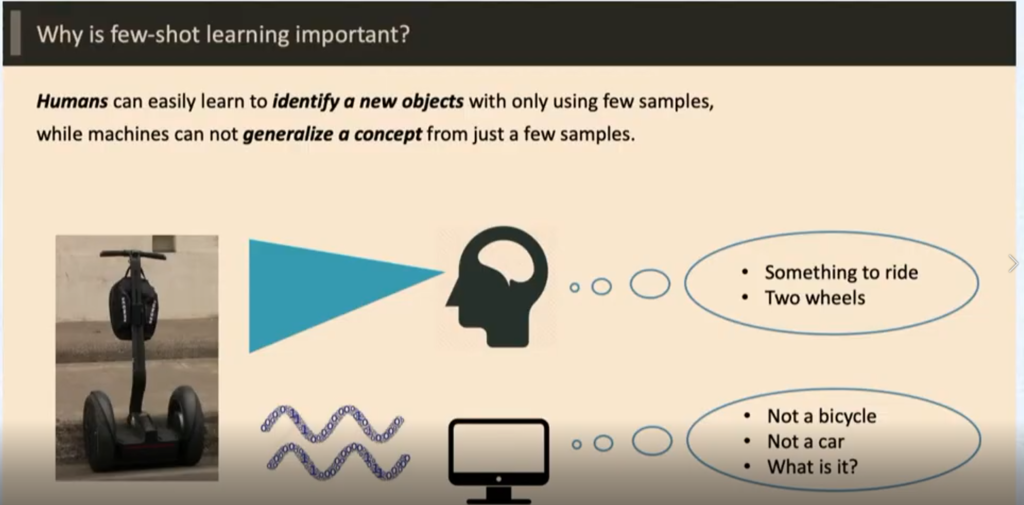
작년 ICCV 에 정말 많이 보며 어떤 것인지 궁금했었던 Few Shot , One Shot 러닝에 대한 정의와 그와 관련된 박사님의 방법론을 설명해준 발표이다.
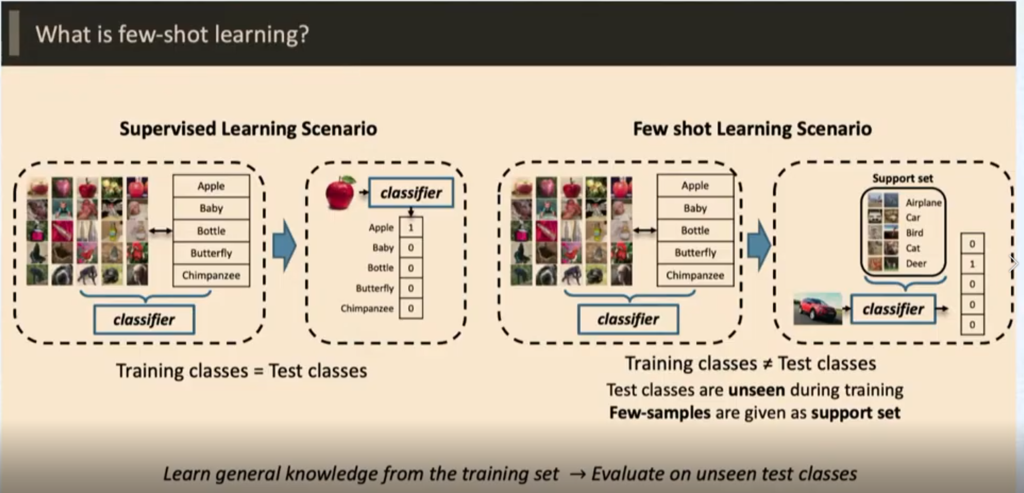
Few Shot learning 이 기존 Supervised learning 이랑 다른 점은, Train과 Test 전부 label이 같냐 안같냐의 차이이다 . 자세히 말하면 , Supervised learning 은 Train에서 학습한 Label을 Test 에서 맞추는 형식 이지만 , Few shot learning은 Train에서 학습 시킨 Label이 Test 에서 없고 Test에 있는 Label은 Train에 없다는 차이가 있다.
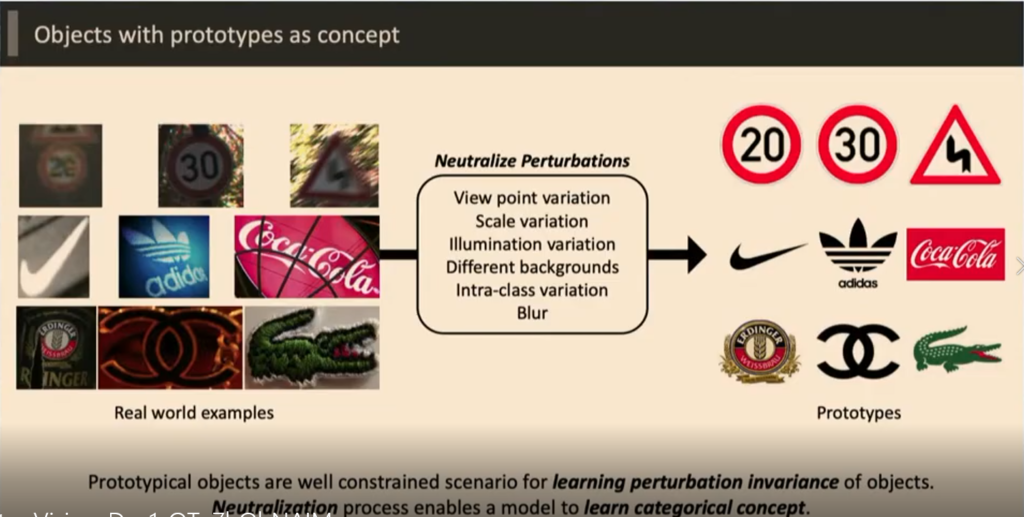
Test 에서는 학습 시키지 않은 영상을 사용하기 때문에 , 영상의 View Point , 빛의 변화나 배경, 생김새의 다양성등이 성능 저하 원인이 된다. 따라서 발표자는 모든 영상을 각각을 대표할 수 있는 영상으로 변환하여 Task를 진행 했다고 한다.
Task를 진행하기 위해서 총 두개의 연구를 진행 했다고 한다.
첫 번째는 Metric learing을 활용한 방식이다
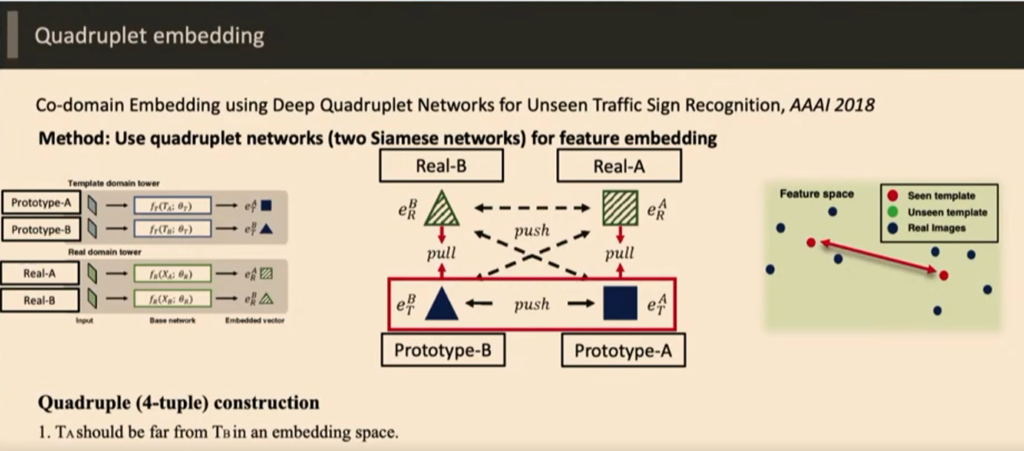
Quardruplet network를 활용해서 실제 영상과 General 영상을 비슷하게 만들도록 하는 Network이다 .
두번째는 Metric learing을 버리고 영상 변환을 통해 중간 feature 를 사용하는 방식이다
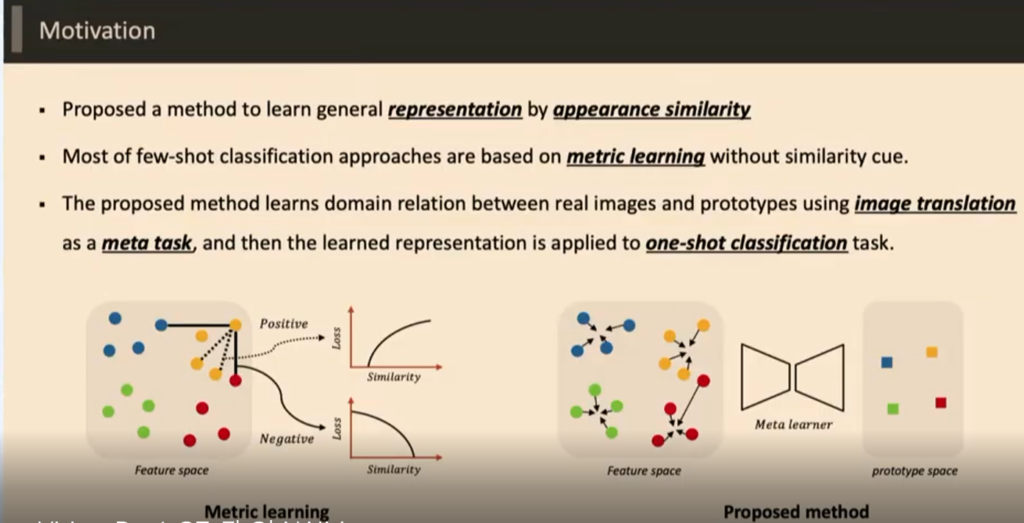
기존 Few shot 러닝은 metric 러닝을 사용하는데 Metric learning 은 정확하게 라벨을 사용하는 것이 아니라 다른 라벨이 Metric place 내에서 혼동이 오는 상황이 생기기 때문에 사용하지 않았다고 한다. 따라서 그러한 어려움을 바꾸기 위해 바꾼 상황은 다음과 같다.
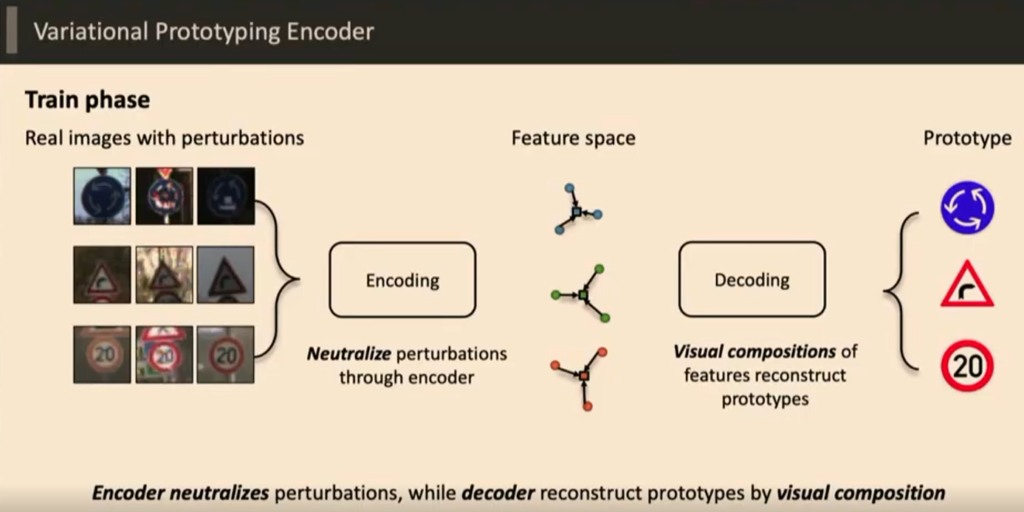
실제 영상을 Encoding 과 Deocoding을 통해 재 생성한고 중간 feature를 가지고 classification과 Retrieval을 진행해 Few shot learning 의 성능을 높혔다고 한다.

성능이 기존 방법론들 대비 많이 높아진 것을 확인 할 수 있다.
후기
이 발표가 흥미로웠던 이유는 먼저 Few shot learning에 대한 기초적인 지식을 배울수 있어서 그랬고, 두번째는영상 변환 중 가운데 feature를 사용하는 방법이 굉장히 다양한 방식에서 사용되고 있다는 것에 새삼 놀라웠다. 영상을 표현하는 Global descriptor가 General 해질 수록 다양한 Task에 적용시킬 수 있을 것 같다는 생각을 하게 되었다.
그림에서도 단순히 encoding과 decoding으로만 나와있어서 이해하는데 어려움이 존재하는데, encoding과정과 decoding과정에 대해 자세한 설명 좀 추가해주실 수 있나요?
좋은 발표가 있었는데 제가 놓친 내용이 있나봅니다.. 본문에 “영상을 각각을 대표할 수 있는 영상으로 변환하여 Task를 진행 했다고 한다.” 라고 한 이후 Quardruplet network 과 중간 feature를 사용하는 방식으로 Task를 해결하였다고 하였는데, 첫번째 방식은 대표 영상으로부터 데이터를 생성하여 사용했다는 뜻인가요..?
N-shot Learning이 아닌 다른 방법에서도 학습시키지 않은 데이터를 test 하여 다양성으로 인한 성능 저하가 있는데 N-shot task에서는 다른 방법론처럼 train의 다양성을 높이는 것이 아닌 (data augmentation) 다양성을 일부로 감소시키는 이유는 적은 데이터로 인한 over fitting을 막기 위함인가요? 어떻게 대표영상을 얻나요?
맞다면 일반화를 연구자의 hand tuning으로 진행하는 것인가요?