지난 리뷰에서 hand-craft optical flow에 대해 알아보았다면, 이번 리뷰에서는 Deep learning 기반에 optical flow 중 하나인 FlowNet에 대해서 알아보고자 합니다.
해당 논문은 2015년에 CVPR에서 공개된 논문으로 상당히 옛날 논문이긴 하지만 deep learning 기반 optical flow 중에 가장 기본이 되는 논문같아 보여서 가져오게 되었습니다.
Introduction
이전에 optical flow는 모두 optimized based method들이었습니다. 그 이유는 당연히 옛날엔 좋은 GPU도 없었고, deep learning 기반 방법론들이 많이 제안되지 않았기 때문입니다.
또한 학습을 시키기 위해서는 많은 양의 dataset이 필요한데, 아무래도 영상 내 모든 pixel이 어느 방향으로 움직이는지에 대한 GT 값을 사람의 손으로 구하기에는 쉽지 않았기 때문에 다른 task에 비해 데이터 양이 충분하지 못하였습니다.
그러다가 해당 논문이 출간되는 2015년 쯤 부터 CNN을 기반으로 다양한 컴퓨터비전 task들이 좋은 결과를 내고 있었고, 다양한 방법론들이 활발하게 제안되었습니다.
특히 segmentation이나 depth estimation과 같은 영상의 각 픽셀들을 예측하는 task들(per-pixel predict) 역시 활발하게 연구되어 왔었기 때문에, 저자는 각 픽셀별 flow vector를 예측해야만 하는 optical flow 역시 충분히 deep learning 기반으로 풀어볼 수 있겠다고 판단하였습니다.
또한 부족한 dataset은 해당 논문의 저자가 기존 데이터 셋들을 합성하여 해결했다고하는데, 해당 부분은 뒤에서 설명하겠습니다.
FlowNet
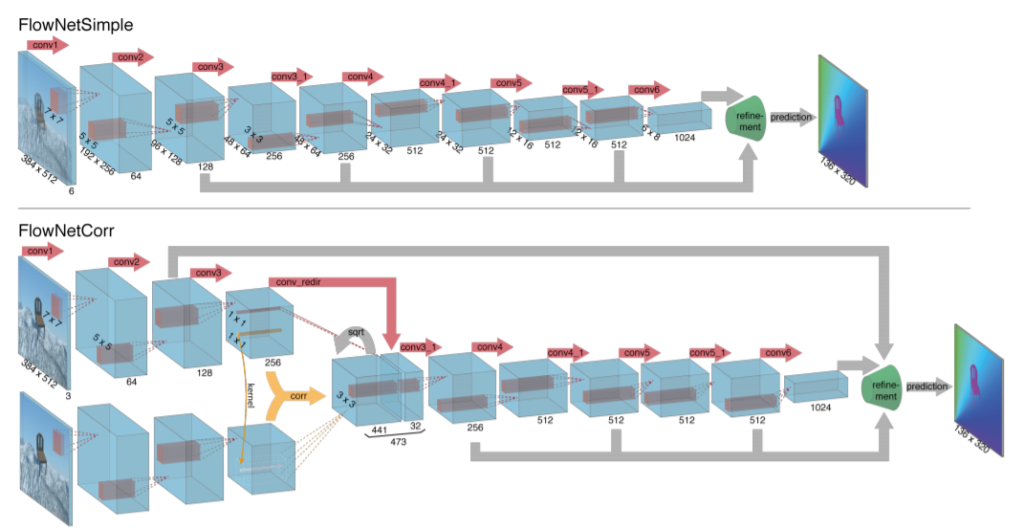
그럼 해당 모델에 구조를 한번 살펴봅시다. 네트워크 구조는 아무래도 옛날 논문이다 보니 상당히 간단합니다. 논문에서는 위에 그림과 같이 크게 2가지 구조를 제안하는데, FlowNetSimple과 FlowNetCorr 입니다.
먼저 FlowNetSimple은 이전 프레임과 다음 프레임에 영상 두 장을 모델에 넣기 전에 먼저 합칩니다. 즉 3채널짜리 영상 두 장을 stack하여 6채널짜리 영상을 입력으로 합니다.
그렇게 하여 단순히 컨볼루션 연산을 쭉쭉 진행하다가 나중에 refinement network를 통과하면 예측된 optical flow vector map이 결과값으로 나옵니다. refinement network는 밑에서 설명드리겠습니다.
FlowNetCorr 역시 매우 간단한데요 Correlation Layer라는 것이 추가된 것입니다. 진행 과정에 대해 간략히 설명하자면 모델에 입력으로 두 영상이 각자 들어가서 Conv3까지 컨볼루션 연산을 한 후, Correlation Layer를 통해 하나의 feature map으로 합쳐지게 됩니다. 그 후에 컨볼루션 연산을 진행 후 역시 refinement network를 통과하게 됩니다.
Correlation Layer
그렇다면 Correlation Layer는 뭘까요? 해당 레이어는 쉽게 말해, 이전 프레임과 다음 프레임 영상 속 pixel들간에 correlation을 계산하고자 만든 Layer 입니다.
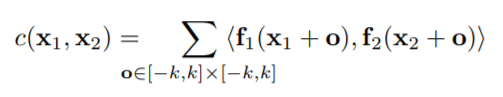
위에 수식은 Correlation Layer에서 수행되는 연산을 표현한 것입니다. Correlation Layer에서는 첫 번째 영상( f_{1} )에서의 픽셀(x_{1})과 두 번째 영상( f_{2} )에서의 픽셀(x_{2})끼리 scalar product를 수행합니다.
이 때 픽셀 하나하나 끼리 연산하는 것이 아닌, patch 개념으로 연산을 하게 되는데, 위에 수식에서 x_{1}과 x_{2}을 중심으로 k × k 크기의 patch들끼리 연산을 진행합니다.
즉 Correlation Layer도 컨볼루션 연산을 수행합니다. 하지만 어떠한 weight를 가지는 필터를 학습하는 것이 아닌, 각 feature map에 k사이즈 patch를 필터로 하여feature1과 feature2끼리 컨볼루션 연산을 하는 것입니다. 그래서 해당 레이어는 학습하는 필터는 존재하지 않습니다.
하지만 Correlation Layer에서는 한가지 문제점이 존재합니다. 바로 위와 같은 방식으로 연산을 하게 되면 두 feature map 크기 만큼( H^{2} \times W^{2} )의 연산을 수행하게 되므로 연산량이 상당히 많아집니다.
그래서 이러한 연산량 문제를 해결하고자 일정한 구역 바깥으로는 넘어가지 못하게끔 Maximum Displacement를 설정하였습니다.
그래서 위에서 설명한 patch연산은 수행하되, Maximum Displacement를 넘어가지 않는 이웃 픽셀까지만을 연산하는 것이지요. 이러한 제약을 통해 최종적인 연산량은 H \times W \times D^{2} 이 됩니다.
그리고 Correlation Layer를 통해 결과값으로 나오는 feature map의 shape 역시 위의 연산량과 동일하게 H \times W \times D^{2} 이 됩니다.
Refinement Network
위에서 네트워크에 대한 설명을 드렸을 때 최종적으로 refinement network를 통과하여 최종적인 output이 나온다고 말씀드렸습니다. 그럼 refinement network에 대해 알아보도록 하죠.
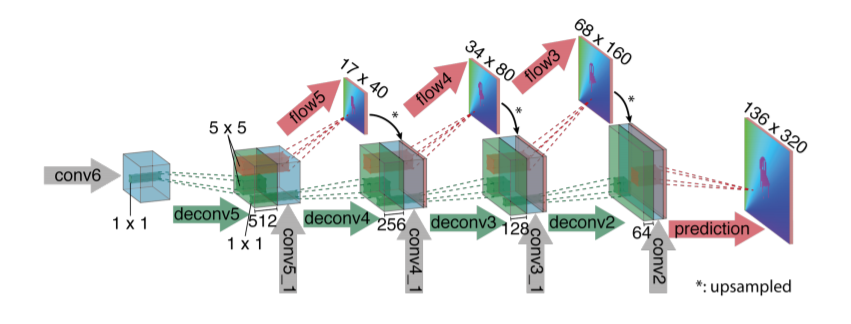
Refinement Network
Refinement Network 역시 상당히 간단합니다. Semantic Segmentation network들과 유사하게, 컨볼루션 연산을 통해 해상도가 작아진 feature map을 원본 resolution만큼 upsampling 하는 것입니다.
그래서 deconvolution 연산을 수행하여 feature map의 해상도를 upsampling하고, upsampling 시에 부족한 정보들은 이전에 conv feats들을 추가해주는 skip connection 기법을 통해 보완해주었습니다.
한번 upsampling 시에 resolution이 2배가 되며 최종적으로 4번의 upsampling 과정을 거친다고 합니다.
또한 refinement network 그림을 보시면 flow5, flow4, flow3 이라는 것이 존재하는데, 해당 부분들은 각 deconvolution을 통해 나온 feature map입니다. 해당 feature map들은 최종적인 flow vector map에 대하여 down smapling한 것으로 볼 수 있습니다.
이 값들을 뽑아낸 후, 원본 GT를 down sampling한 값과 L2 Loss를 계산하게 되는데, 이러한 Loss를 End-Point-Error(EPE) Loss라고 합니다.
Flying Chairs
도입부에서 간략히 언급드렸다시피, Optical Flow를 학습시키기 위한 데이터 셋은 다른 Taks에 사용되는 dataset에 비해 상당히 양이 부족합니다. 각 픽셀별 optical flow vector를 사람이 하나하나 GT로 설정해주기 힘들기 때문이죠.
그래서 저자는 기존에 존재하는 두 개의 데이터 셋(Flickr, 3D chair model)을 혼용하여 사용하였습니다.

위에 그림이 바로 논문에서 제안하는 데이터 셋인 Flying Chairs 입니다. 그냥 말그대로 기존 데이터 셋에서 3d chair 영상을 붙여 넣었습니다.
조금 더 자세히 설명하면 Flickr 데이터 셋 중 city, landscape, mountain 카테고리에서 영상을 가져와 background로 사용하였고, publicly available 3D chair model을 foreground로 사용하였습니다.
물론 단순히 영상을 붙여넣기만 한 것은 아닙니다. 물체의 움직임을 표현하기 위해서, chair한테 random한 affine transformation을 적용하였습니다.
의자에 affine transformation을 적용시키면, 정적인 배경에 대해서 물체가 움직이는 것으로 재해석 할 수 있기 때문입니다.
이러한 affine transformation은 2번째 영상(다음 프레임 영상)에 적용되었으며, 적용되는 모든 파라미터들(number, types, sizes and transformation parameters)는 모두 랜덤하게 샘플링하여 가져옵니다.
최대한 랜덤 분포의 경향성을 Sintel 데이터 셋에 맞추어 사용했다고 합니다. 여기서 Sintel 데이터 셋이란, optical flow의 GT를 제공하는 데이터 셋 입니다.
Results
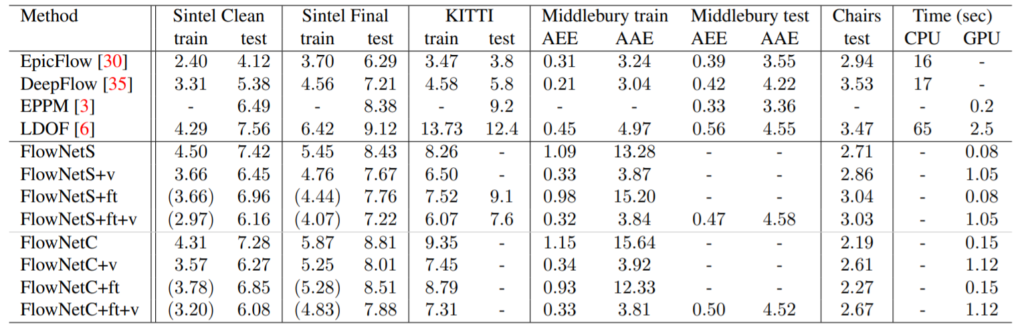
결과는 위와 같습니다. FlowNetS는 Simple 구조를 사용한 것이며, FlowNetC는 Correlation layer 구조를 사용한 것입니다.
ft는 먼저 Flying Chair Dataset으로 학습 시킨 이후에, Sintel 또는 KITTI 데이터 셋으로 finetune을 한 것을 나타낸 것입니다.
v는 Refinement network에서 단순히 bilinear upsampling을 한 것이 아닌, coarse-to-fine method 기법을 사용했다는 것인데, 자세하게는 어떤 방식으로 진행됐는지 설명이 구체적이지 않아서 넘어가도록 하겠습니다.
아무튼 간에 결과를 보시면 해당 표에 나오는 수치들은 endpoint errors 값으로 낮으면 낮을수록 좋은 것입니다.
FlowNet에 경우 기존에 hand-craft 기반 방법론들에 비해 확실히 GPU를 사용하다보니 속도는 많이 빨라졌지만, 성능은 좋지 못하는 것을 볼 수 있습니다.

정성적으로 봤을 때도, 특정 case에서는 FlowNet의 에러율이 더 낮은 것을 확인할 수는 있지만, 대부분에 상황에서는 hand craft 기반인 EpicFlow가 더 좋은 모습을 확인하실 수 있습니다.
이러한 성능의 아쉬운 점이 존재하기에 FlowNet은 2017년에 V2를 들고 나왔습니다. 해당 내용은 추후에 시간이 생기면 해당 리뷰 글에 추가하도록 하겠습니다.