

기존 Video 에서 action recognition 연구를 할 때 주로 2~5초 가량의 clip을 추출하여 예측했었습니다. 그러나 현재의 어떤 행동을 판단하기 위해서는 과거와 미래라는 맥락 또한 중요시 여길 수 있습니다. 저자는 이러한 생각을 기반으로 비디오 전체의 정보를 통해 video model 에게 추가적인 정보를 주는 LFB(Long-term Feature Bank)를 제안하게 됩니다.
1. Long-Term Feature Bank Models
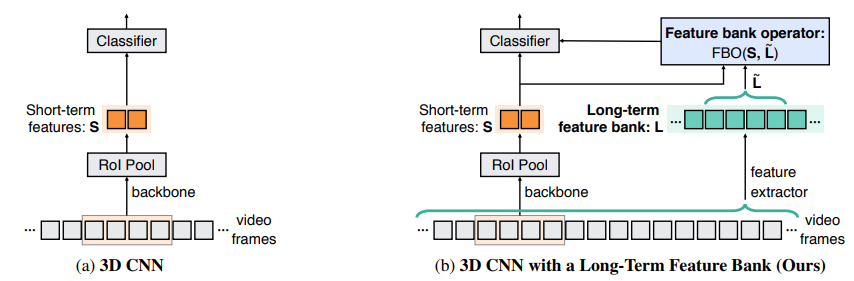
주로 spatio-temporal action localization 문제를 풀 때, 이전 SOTA 방식들은 Fig 2.(a)와 같이 2~5초의 clip을 입력으로 3D CNN 기반 backbone network에서 feature를 뽑고 region-based person detector (Faster RCNN에서처럼) 로 RoI feature를 얻어내 사용하였습니다. 그러나 이는 short-term의 정보만 사용한 방식이었기에 저자는 Fig 2.(b) 와 같이 Long-term feature bank와 Feature bank operator로 구성된 구조를 제안했습니다.
1.1 Long-Term Feature Bank
Long-term feature bank 의 주 목적은 비디오에서 현재 인식하려는 프레임에 문맥적인 정보를 주는 것입니다. 이를 위해 비디오 전체 프레임에 person detection을 하여 long-term feature L 들을 얻어냅니다. 그리고 병렬적으로 비디오 전체 프레임에 1초 간격의 clip을 3D CNN에 넣고 RoI pooling 하여 short-term feature S 들도 계산합니다. 여기서 L은 전체 비디오에서 비디오 내의 모든 person들이 언제 무엇을 하는지에 대해 정보를 줄 수 있고 또한 S와 L을 얻어낼 때 사용한 구조는 같은 구조이며 파라미터를 공유하지 않습니다.
1.2 Feature Bank Operator
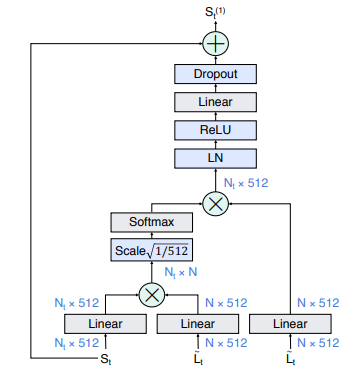
제안된 모델은 feature bank operator (FBO) 를 통해 앞서 다뤘던 long-term feature L로부터 정보를 얻게 됩니다. FBO 에는 현재 시간이 t라면 입력으로 short-term RoI pooled feature S_{t} 와 현재 clip 중심 좌우 w만큼의 long-term feature 를 모은 \tilde{L}_{t} 를 사용하게 됩니다. 여기서 w는 실험을 통해 얻은 하이퍼 파라미터 입니다. 이와 같은 입력을 넣은 FBO 모듈에서의 출력값에 다시 S_{t} 를 channel-wise 하게 더해 linear classification에 사용하게 됩니다.
FBO의 내부는 modified non-local block (NL) 이라고 불리우는 Fig 3 이 반복되어 구성됩니다. S_{t} 는 \tilde{L}_{t} 에 곱해진 후 attention을 위해 사용되고 여기서 나온 값은 다시 S_{t} 에 더해져 attention을 주게 됩니다. 이와 같은 연산이 진행되기에 FBO는 사실상 attention module의 역할을 합니다.
1.3 Batch vs Casual
본 논문에서는 다음과 같이 두가지 상황으로 두어 실험하였습니다. 앞서 말한 clip 중심 좌우 w만큼 보는 것을 casual setting으로 두었고 비디오 전체를 사용하는 것을 batch setting으로 두었습니다.
2. Experiment
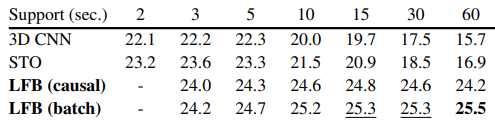
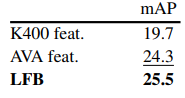

위 실험들은 AVA dataset으로 진행한 ablation 실험과 결과 입니다. STO는 다른 논문에서 제안한 3D CNN 기반 non-local short-term operator 를 의미하며 LFB는 default로 두 개의 NL block이 연결된 LFB operator를 의미합니다.
Table 1에서는 입력으로 긴 비디오를 넣을 때 다른 모델은 성능이 떨어지는 반면 LFB는 증가하는 것을 확인할 수 있습니다.
Table 2에서는 short-term과 long-term feature를 같이 사용하는 제안된 decoupling 방식과 Kinetics dataset으로 pretrained 된 3D CNN (K400 feat), AVA dataset으로 pretrained 된 3D CNN (AVA feat)를 비교한 결과 제안된 방식이 더 좋은 성능을 보인 것을 확인할 수 있습니다.
Table 3에서는 제안된 FBO 내부의 NL block과 Avg/Max pooling의 성능차이를 확인할 수 있습니다.
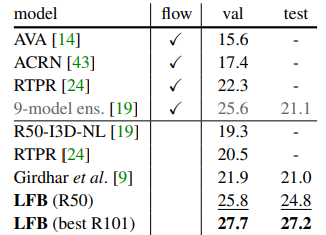
Table 4에서는 이제까지 제안된 다른 방식들에 비해 좋은 성능으로 SOTA를 달성한 것을 확인할 수 있습니다.
3. Reference
[1] https://arxiv.org/pdf/1812.05038.pdf