Du Tran1,2 , Lubomir Bourdev1 , Rob Fergus1 , Lorenzo Torresani2 , Manohar Paluri1 1Facebook AI Research, 2Dartmouth College {dutran,lorenzo}@cs.dartmouth.edu {lubomir,robfergus,mano}@fb.com
Preview
이번에 읽은 논문은 C3D 논문인데 ,실험 원복을 위해 어떻게 실험 세팅을 했는지에대해 집중해서 읽어 보았습니다.
이번 paper의 contribution을 정리하면 다음과 같습니다.
- 3D conv network 가 객체의 Appearance 와 Motion 의 feature를 동시에 효과적으로 학습하는 것을 실험적으로 보임
- 경험적으로(여러 실험을 통해) 3x3x3(depth*kernel*kernel) conv kernel을 모든 layer 적용하는 것이 최고의 구조임을 찾았음
- 제안하는 feature가 아주 간단한 선형 모델을 통해서도 여러 benchmarks에서 높은 성능을 보임(아래 참고)

위 실험들의 데이터 셋은 모두 비디오로 이 분야의 연구의 핵심은 어떻게 하면 spatio-temporal imformation을 잘 보존할까?가 된다.
그래서 아래와 같이 2D conv와의 비교를 통해 3D conv를 쓴 이유를 정당화 하고있는데,2D conv를 사용하게 되면 temporal한 imformation을 잃게 되기 때문에 3D conv를 사용하게 된다고 한다.

여기서 주로 UCF101 데이터 셋을 가지고 실험 및 리포팅을 하는데 그 이유를 large-scale video dataset을 가지고 실험하기에는 시간이 너무 소요되기 때문에 medium-scale을 가지고 최적의 구조를 찾는 실험을 했다고 한다.
Experiment Details
- All video frames are resized into 128 × 171. This is roughly half resolution of the UCF101 frames
- Videos are split into non-overlapped 16-frame clips which are then used as input to the networks
- The input dimensions are 3 × 16 × 128 × 171
- We also use jittering by using random crops with a size of 3 × 16 × 112 × 112 of the input clips during training
- The networks have 5 convolution layers and 5 pooling layers (each convolution layer is immediately followed by a pooling layer), 2 fully-connected layers and a softmax loss layer to predict action labels
- The number of filters for 5 convolution layers from 1 to 5 are 64, 128, 256, 256, 256, respectively
- All of these convolution layers are applied with appropriate padding (both spatial and temporal) and stride 1, thus there is no change in term of size from the input to the output of these convolution layers
- All pooling layers are max pooling with kernel size 2 × 2 × 2 (except for the first layer) with stride 1 which means the size of output signal is reduced by a factor of 8 compared with the input signal
- The first pooling layer has kernel size 1 × 2 × 2 with the intention of not to merge the temporal signal too early and also to satisfy the clip length of 16 frames (e.g. we can temporally pool with factor 2 at most 4 times before completely collapsing the temporal signal)
- The two fully connected layers have 2048 outputs
- We train the networks from scratch using mini-batches of 30 clips, with initial learning rate of 0.003. The learning rate is divided by 10 after every 4 epochs. The training is stopped after 16 epochs.
Experiment
Varying network architectures
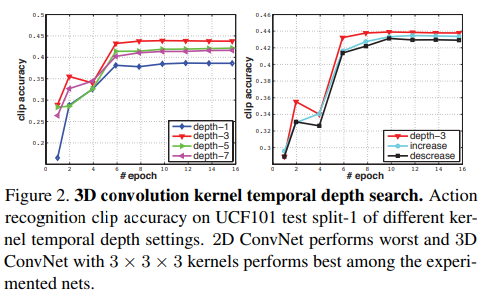
1) homogeneous temporal depth: all convolution layers have the same kernel temporal depth
we experiment with 4 networks having kernel temporal depth of d equal to 1, 3, 5, and 7
2) varying temporal depth: kernel temporal depth is changing across the layers
depth increasing: 3-3-5-5-7 and decreasing: 7- 5-5-3-3 from the first to the fifth convolution layer respectively. We note that all of these networks have the same size of the output signal at the last pooling layer, thus they have the same number of parameters for fully connected layers
논문에 표현된 내용들을 복붙하기 보다는 작은 내용이지만 자신이 이해한 내용을 자신의 언어로 표현해 보는것을 추천합니다.