본 논문은 CAMs을 이용한 Segmentation 문제 풀이에 관한 논문입니다. 혹시 이해가 부족한 부분을 지적해주시면 내용 추가하도록 하겠습니다!
논문 링크 [링크]
Introduction
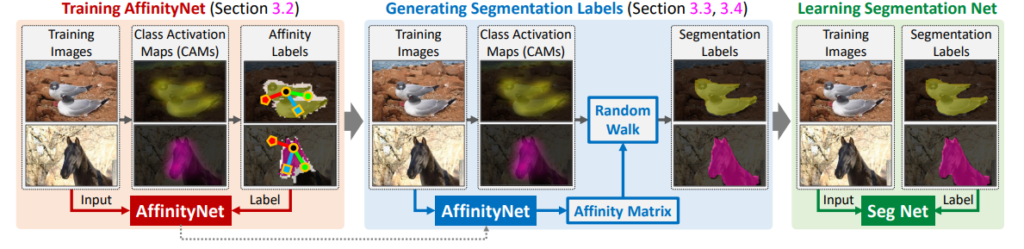
Weakly Supervised Semantic Segmantation을 위한 annotation으로는 bounding box나 scriblize annotations, image-level class label등이 있다. 그 중에서도 논문은 image-level class labels을 이용한 segmentation 문제 해결을 다룬다. image-level class labels 은 물체의 위치를 반영하지 못한다.(ill-posed problem) 이러한 문제에 대응하기 위한 방법중 하나가 CAM이다 CAM을 통하여 활성화된 영역이 seed로 작용하여 Segmentation을 진행한다. 그러나 이 Seed에서부터 정확한 물체의 형태를 얻기 위해서는 추가적인 데이터 (image segmentation이나 video 등)가 필요하다. 본 논문은 이러한 추가적 데이터 구성을 최소화하기 위하여 AffinityNet을 제안한다. AffinityNet 은 input 이미지에서 인접한 이미지의 coordinates를 예측하는 네트워크로, 이를 통해 Segmentation label을 직접 생성하고, 이를 train 데이터로 하여 Segmentation 모델을 학습시키는 방식이다. 논문에서 발췌한 [그림1]을 통해 위 내용을 쉽게 이해할 수 있을것이다.
Contribution
논문이 말하는 contribution 내용은 원문 그대로 옮겨오겠다.
- We propose a novel DNN named AffinityNet that predicts high-level semantic affinities in a pixel-level but is trained with image-level class labels only.
- Unlike most previous weakly supervised methods, our approach does not rely heavily on off-the-shelf techniques(image segmentation를 뜻함), and takes advantage of representation learning through end-to-end training of AffinityNet.
- On the PASCAL VOC 2012, ours achieves state-of-the-art performance among models trained under the same level of supervision and is competitive with those relying on stronger supervision or external data. Surprisingly, it even outperforms FCN, the well-known fully supervised model in the early days.
Framework
논문의 구조는 Introduction과 같이 (1) image-level-label에서 pixel-level의 라벨을 합성하는 파트(CAMs 생성 및 AffinityNet을 통한 seed map의 refine) (2) 합성된 label 을 통해 semantic segmentation DNN을 학습시키는 파트(segmentation model)로 구성되어있다. (이러한 방식을 이용하면 2020논문 SEAM의 Supervisoin Gap을 줄이는 다른 접근이 될 수도 있을 것 같아 신기했다..)
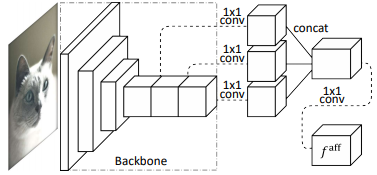
논문의 가장 중요한 파트중 하나라고 생각하는 AffinityNet의 구조는 [그림 3] 과 같다.
당시 다른 네트워크의 결과와 비교한 정량, 정성적 결과


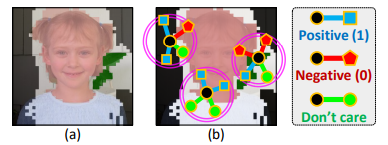
affinity label은 특정 픽셀에 대해서 CAM기준으로 positive,negative,don’t care로 라벨링하는거 같은데 맞나요…? 만약 맞다면 CAM도 결국은 모델을 태워서 얻는건데 해당 내용으로 라벨링을하려면 backbone에 영향이 커질것 같은데 맞나요…? 그리고 CAM은 어떤 object에 대해서 고르게 나타나는게 아니라 몇몇 부분만 활성화된걸로 나타날텐데 부분을 라벨링해 학습해서 어떻게 전체에 대해서 구별할 수 있는걸까요..
affinity label은 특정 픽셀에 대해서 CAM기준으로 positive,negative,don’t care로 라벨링하는거 같은데 맞나요…?
넵 맞습니다
CAM도 결국은 모델을 태워서 얻는건데 해당 내용으로 라벨링을하려면 backbone에 영향이 커질것 같은데 맞나요…?
실험을 해보지 않아 정확하지 않으나, CAM을 이용하여 다른 확률적 방법을 이용하므로 backbone만의 성능은 아닐 것이라 생각합니다!
CAM은 어떤 object에 대해서 고르게 나타나는게 아니라 몇몇 부분만 활성화된걸로 나타날텐데 부분을 라벨링해 학습해서 어떻게 전체에 대해서 구별할 수 있는걸까요..
CAM 이후 dCRF 과정을 통해 map을 후처리하는 과정이 있습니다. 물론 후처리 이후에도 pixel level label처럼 완벽하지는 않으나, 1번 질문과 같이 positive,negative,don’t care 라벨을 이용하여 학습하고, 이후 확률적 과정을 이용하여 전체에 대한 segmentation mask를 예측합니다
http://server.rcv.sejong.ac.kr:8080/2020/09/20/cvpr2018learning-pixel-level-semantic-affinity-with-image-level-supervision-for-weakly-supervised-semantic-segmentation_2/ 에 추가적인 내용도 참고해 주시면 감사하겠습니다
해당 논문에서 AffinityNet가 제일 중요하다고 말씀하셨는데, 해당 네트워크를 나타내는 구조 그림과 더불어 진행 과정에 대한 부연 설명이 있었으면 더 좋을 것 같습니다.
AffineNet의 진행과정에 대해 보충 설명을 추가하였습니다! training 과정은 아직 상세한 설명을 추가하지 않았으나, 내용을 수정하여 추가 하거나 세미나 발표에 추가하겠습니다http://server.rcv.sejong.ac.kr:8080/2020/09/20/cvpr2018learning-pixel-level-semantic-affinity-with-image-level-supervision-for-weakly-supervised-semantic-segmentation_2/