본 논문은 하나의 이미지와 그 이미지의 pixel-level segmentation mask 만으로, query segmentation을 진행하는 것을 목표로 한다. 논문이 제안하는 아키텍처에 대해 설명하기 앞서 k-shot learning을 classification 문제를 기준으로 간단하게 소개하고자 한다.
k-shot learning은 classification문제에서 N-way k-shot learning으로 불리기도 하며, k개의 support data를 이용하여 query data에 대해 테스트를 진행하는 형식이다. 기존의 네트워크를 이용한 문제는 많은 수의 파라미터를 가진 모델은 많은 데이터로 학습시키는 과정을 통해 분류기를 학습하였다. 그러나 k-shot learning은 특성상 같은 구조로 학습을 진행하면 너무 적은 데이터에 과적합이 발생할 수 있다. 그래서 기존의 네트워크를 이용하여 추출한 고차원의 feature를 feature간의 유사도를 비교하는 방법이 one-shot task를 해결하기 위한 방법 중 하나였다. 그 예시 중 하나가, Siamese Network를 이용한 것이다. 대칭인 Siamese Network에서 추출한 feature의 거리를 L2 Loss나 Triple loss를 이용하여 학습을 하는 것이다. (물론 논문의 구조는 에서 말한 siamese Network와 직접적인 관련은 없어보이나, 실험시 siamese 구조를 이용한 네트워크와 비교하였다.)
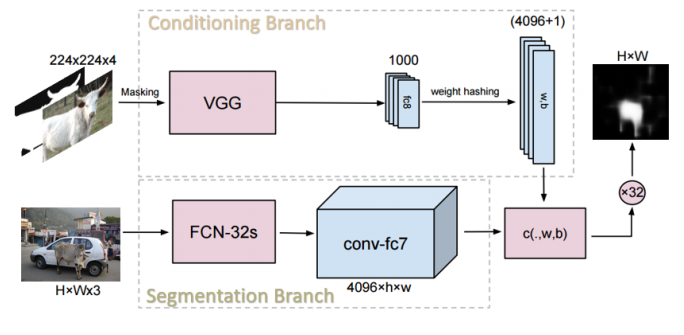
[그림 1]에서 확인할 수 있듯이 Support data는 하나의 이미지와 label 쌍이고, 이를 통해 분류기 파라미터 w,b를 생성한다. 이 Support data를 이용하여, query data의 pixel level 예측을 진행한다.
의 논문의 contributions 은 다음과 같다
(1) we propose a novel technique for oneshot segmentation which outperforms baselines while remaining significantly faster.
(2) we show that our technique can do this without weak labels for the new classes.
(3) we show that meta-learning can be effectively performed even with only a few classes having strong annotations available.
(4) we set up a benchmark for the challenging k-shot semantic segmentation task on PASCAL.
논문의 contributions에서 가장 인상깊었던 부분은 보통 few-shot learning은 class가 다양해야한다는 통념과 다르게, 적은 class 갯수로도 좋은 성능을 보였다는 내용이 있었는데, 물론 2017년에 쓰인 논문이지만 one-shot learning은 class의 갯수가 많을수록 좋다는 점에서 이 논문을 조사하는 목적(한개의 클래스를 가진 식물 데이터셋의 segmentation)과 적합하지 않을 수도 있다는 점을 알게되었다. 이 논문을 읽게되기 전 읽은 논문인 CRNet은 기존의 방식인 support set의 정보만 이용하는 것이 아닌 서로(query와 support set)의 정보를 이용하는 방식이라 하는데, 이는 다음에 소개해보도록 하겠다.
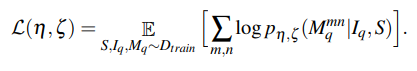
논문의 수식은 위와같다. 여기서 S는 support set pair(mask와 이미지)이고, M은 query image의 마스크이다. 이는 다음과 같이 정의된다.
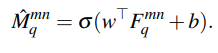
w와 b는 모델 아키텍쳐의 첫번째 branch의 output (conditioning branch)이며, σ 는 sigmoid 함수이다. (수식의 경우 명확하게 이해한 것이 아니여서 이후 내용이 수정될 수 있습니다 죄송합니다)
이후 논문에서는 k-shot learning으로 확장하는 실험도 소개하였지만, one-shot learning에 더 최적화 된 모델이라 소개하였으므로 생략한다.다음은 miou를 통해 측정한 실험 결과이며, 1-NN은 최근접 이웃 알고리즘, LogReg는 logistic regression,Tine-tuning은 support set에 fine tuneing 한 네트워크를 통해 query set에 대한 측정을 진행한 내용이다. Siamese는 글의 초입에설명한 방식의 기법에 FCNs을 이용하여 Dense Matching을 진행한 것이다. fine-tuning에 관련하여는 논문 One-shot video object segmentation 를 참고하였다고 한다.
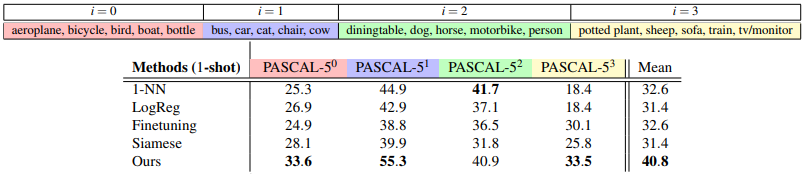
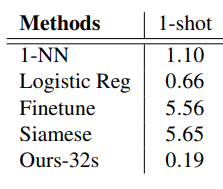

참고
https://www.kakaobrain.com/blog/106
https://www.youtube.com/watch?v=1v_knTWJl9s
https://3months.tistory.com/507
“one-shot learning은 class의 갯수가 많을수록 좋다는 점에서 이 논문을 조사하는 목적(한개의 클래스를 가진 식물 데이터셋의 segmentation)과 적합하지 않을 수도 있다는 점을 알게되었다.” 라고 말씀하셨는데, 왜 그렇게 생각하셨는지 알 수 있을까요?