최근에 Object Detection의 대표격인 SSD와 Faster-RCNN에 대해 공부를 했었습니다. 이를 기반으로 새로운 detection 모델 논문들을 조금씩 읽고 있었는데, 모두 Anchor box 기반 모델이더군요.
그래서 이번 리뷰로는 anchor free로 작동하는 CornerNet에 대하여 리뷰를 작성하려고 합니다. 사실 해당 논문에 대해서는 예전에 세미나에서도 종종 들어보았고, 다른 연구원님이 리뷰도 작성하셨지만, 역시 제 지식으로 만들기에는 어려움이 있었습니다. 그래서 이번 기회에 직접 논문을 읽고 정리하고자 합니다.
Introduction
먼저 CornerNet과 다른 Ojbect Detection 모델에 가장 큰 차이점은 Anchor free라는 점입니다. 유명한 Detection 모델인 R-CNN, SSD, YOLO와 같은 모델들은 모두 Anchor box를 사용해서 학습 및 테스트를 진행하는 반면, CornerNet은 default anchor box 없이 object의 Left-Top과 Right-Bottom을 검출하도록 학습하는 것입니다.
논문에서는 Anchor box 기반 모델들의 단점에 대해 언급하는데, 이는 다음과 같습니다.
- 너무나 많은 초기 anchor box를 설정한다.
- anchor box를 설정하기 위한 하이퍼 파라미터와 설계 값들이 너무 많다.
먼저 첫번째 부터 설명드리면, Anchor box 기반 모델인 DSSD에 경우에는 초기 40k개의 Default box를 만들며, RetinaNet에 경우에는 100k개가 넘는다고 합니다.
이렇게 많은 박스들을 만들 수 밖에 없는 이유는, 실제 object가 영상 속 어디에 존재하는지 모르기 때문에, 이를 찾기 위해서 일단 영상 전체에 대하여 빽빽하게 default box를 설정한 후, 실제 GT box와 overlap을 구하여 positive box를 찾아내는 것입니다.
하지만 이렇게 찾은 positive box는 영상 내에서 많이 있지 않기에, positive box와 negative box 개수의 매우 큰 불균형으로 인하여 학습의 속도가 느려진다는 단점이 존재합니다.
두번째로는, default box를 설정하는데 있어 해당 박스의 scale과 aspect ratio가 필요합니다. 이러한 값들은 multiscale architecture에서는 각각의 구조에 대해 박스 값들을 따로 설정해줘야 하기에, 모델 설계가 매우 복잡해질 수 있습니다.
하지만 CornerNet은 물체의 bounding box의 좌상단과 우하단 점들을 검출하는 것이므로 anchor box를 사용하지 않기에 위에 단점들이 없습니다.
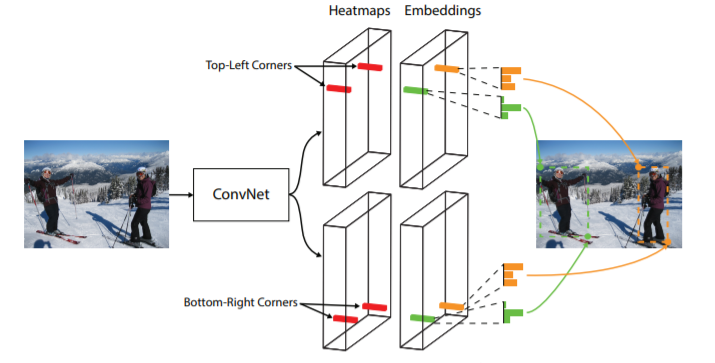
CornerNet은 또한 one stage로 구성되어 있으며 해당 모델에서는 2개의 heat map을 예측하는데, 이 heatmap들은 각각 물체의 좌상단과 우하단을 검출합니다. 그 후에 각각의 예측 코너들에 대하여 벡터 임베딩을 진행하는데, 자세한 얘기는 바로 밑에서 하겠습니다.
CornerNet
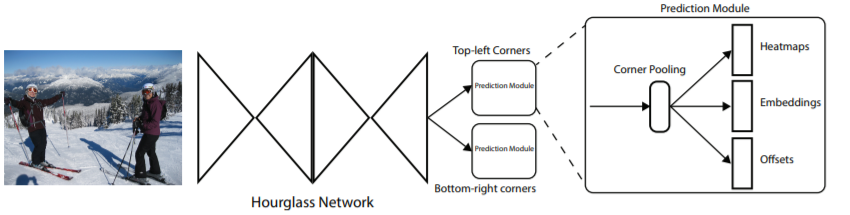
CornerNet의 전반적인 흐름
CornerNet의 특징들을 나열하면 다음과 같습니다.
- 물체의 bounding box의 좌상단, 우하단 코너점을 예측한다.
- Anchor Free 방식이다.
- One stage 학습 방식을 가진다.
- predict 값으로 2개의 heatmap(좌상단,우하단)과 offset(좀 더 예측을 타이트하게끔 하기 위해), Embedding이 존재.
- 보다 정확한 검출을 위해 Corner Pooling 을 추가.
- 단일 scale의 feature map만을 사용.
위에 그림에서 Hourglass Network는 pose estimation을 추정하는 모델에서 사용되는 backborn이라 하는데, 저가 그쪽 논문을 읽어보지 않아서 자세히 알고 넘어가지는 못하였습니다.
그럼 이제 자세히 보시죠. 먼저 heatmap은 H×W×C로 이루어져 있는데, 이때 C는 검출할 물체 종류의 개수를 의미합니다. CornerNet은 background class가 존재하지 않으며, 각 채널은 해당 카테고리의 물체의 코너인지 아닌지 2진 분류 형식으로 나누게끔 되어 있습니다.
각각의 코너별로 하나의 GT positive location이 존재하며 그 외에는 negative로 분류합니다. 그러면 positive location이 되기 위해서는 predict corner가 GT corner와 정확하게 일치해야만 할까요?
당연히 아닙니다. 보통 key point detection에서는 radius가 나오게 되는데, radius는 아래 그림을 보시면 이해가 빠르실 것 같습니다.

그림에서, 빨간 박스는 GT 박스를 의미하며 초록색 점선 박스는 predict한 값을 나타냅니다. 해당 예측값은 GT box의 코너와 완전히 동일하지는 않지만, GT corner를 중심으로 일정 반경안에 예측 코너점이 위치한다면, 해당 코너를 positive로 볼 수 있는 것입니다.
Heatmap Loss
위에서 우리가 예측값으로 Heatmaps, Embeddings, Offsets을 가진다고 했으니, loss 설계도 해당 값들에 맞게끔 설정해줘야 합니다. 먼저 Heatmap의 loss에 대해서 알아보도록 합시다.
먼저 위에서 설명한 radius를 학습하기 위해 해당 논문에서는 GT corner를 다음과 같은 unnormalized된 가우시안 값으로 적용시켰다고 합니다.
e^{- \frac{x^{2}+y^{2}}{2 \sigma ^{2}}}
해당 수식에서 sigma는 반경의 1/3크기 값을 가지며 해당 센터값은 positive location 입니다. 아무튼 학습에서 예측하는 값도 가우시안 형식의 값을 학습 및 예측하게 됩니다.
하지만 heatmap에서도 역시 positive한 값은 코너 점 중심 일정 영역에만 해당하고, 그 외에는 negative인 class imbalance 현상이 발생하는데, 논문에서는 이를 해결하고자 focal loss를 설계했다고 합니다.
focal loss는 일단 아래와 같습니다.
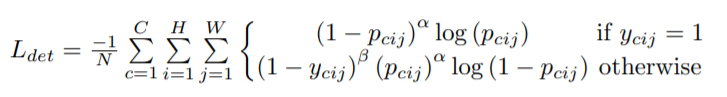
- p_{cij} – ‘c’ class에 대한 location(i, j)의 score
- y_{cij} – Unnormalized 가우시안 형식의 ‘GT’ heatmap
- N – 영상 속 object의 개수
- \alpha \beta 각 포인트를 제어하는 hyper-parameters
focal loss는 간략하게 설명드리면, 학습할 때 흔히 발생하는 positive, negative 비율의 심각한 불균형을 해결하고자 제안된 loss로, easy negative에 대한 가중치는 낮추고, hard negative에 대한 가중치는 높이는 방식입니다.
이러한 focal loss를 이용해 CornerNet에 맞게 customize를 하여 heatmap loss를 설계하였습니다.
Offsets Loss
다음은 offset loss입니다. 일반적으로, convolution으로 이루어진 network를 태우면, 해당 결과값은 input image보다 더 작은 해상도의 feature map이 나오게 됩니다.
CornerNet에서는 기존 입력 영상의 location을 (x, y)로 한다면, heatmap안에서는 down sampling factor인 n이 추가로 붙어 ([x/n], [y/n])이 됩니다.
이때, 해당 heatmap 상에 location ([x/n], [y/n])을 input 영상의 해상도로 remap한다면, 엉뚱한 위치로 remap이 될 가능성이 존재합니다.
이를 해결하고자 offset을 통하여 위치를 조정해주는데 해당 논문에서는 Faster R-CNN과 같이 SmoothL1 loss를 이용하여 offset에 대한 loss를 구합니다.
o_{k} = \big(\frac{x_{k}}{n} - [\frac{x_{k}}{n}], \frac{y <em>{k}}{n} - [\frac{y</em>{k}}{n}]\big)o_{k}는 offset을 나타내며, x_{k}, y_{k} 는 k에 대한 x, y 좌표를 의미합니다.
Grouping Corners
아마 해당 챕터가 이 논문에서 가장 중요한 부분이 아닐까 생각이 듭니다. 먼저 영상 속에는 대부분 하나의 object가 존재하는 것이 아니라, multiple object가 존재합니다.
그러므로 해당 object의 개수만큼의 좌상단 코너점들과, 우하단 코너점들이 존재하게 될 것입니다. 그러면 이제 이 코너점들 중에서 같은 bounding box의 코너쌍(좌상단-우하단)끼리 매칭을 시켜줘야 하는데, 이를 어떻게 하면 좋을까요?
해당 논문에서는 multi-person pose estimation task에서 제안된 Associative Embedding method에 영감을 받았다고 합니다.
방법은 매우 간단한데, 각 코너점들의 embedding vector를 학습하여 예측하고, 이 값들의 distance를 서로 계산하는 것입니다.
그래서 만약 어떠한 좌상단 코너점의 embedding과, 우하단 코너점의 embedding 사이의 거리가 짧다면, 이 두 코너점은 하나의 bounding box안에 있다고 볼 수 있는 것입니다.
여기서 제가 논문을 읽으며 흥미로웠던 점은,, 학습된 embedding의 실제 값은 중요하지 않는다는 점입니다.
결국 embedding distance로 매칭을 하는 것이기 때문에, 우리가 중요하게 보는 것은 올바른 매칭이 되는 코너점들끼리의 embedding distance가 짧아지도록 학습되는 것입니다.
그래서 해당 부분의 loss는 크게 2가지로 나뉘어 지는데, 이는 아래와 같습니다.
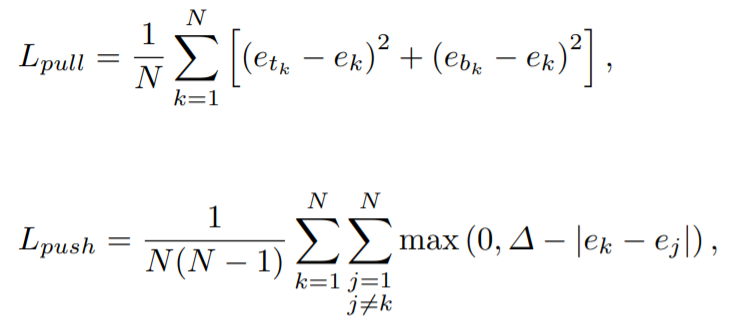
- e_{t_{k}} - 'k' object가 가지는 좌상단 코너의 embedding 값.
- e_{b_{k}} - 'k' object가 가지는 우하단 코너의 embedding 값.
- e_{k} - 좌상단 코너의 embedding과 우하단 코너의 embedding 값의 평균값
일단 loss 이름이 ‘pull’과 ‘push’로 되어있는데, 대충 보면 pull loss에서 가까이 있어야 할 코너점들끼리 더 가까이 그룹을 지을 수 있게끔 하는 것이고, 반대로 push loss에서는 멀어져야할 코너들끼리는 더 분리되게끔 해주는 것입니다.
수식으로 살펴보면, 먼저 pull loss에서는 좌상단과 우하단의 embedding값을 각각 평균 embedding값과 L2 loss로 계산하여 더하는데, 이를 통해 좌상단, 우하단 embedding 값이 평균 embedding 값에 가까워지게끔 학습합니다.
그리고 push loss에서는, 위에 pull loss에서 사용한 평균 embedding 값들을 이제 비교하게 되는데, 각 ojbect 별로 평균 embedding을 가지고 있으므로, 서로 다른 object들 끼리의 평균 embedding은 멀리 위치하게끔 설계한 것 같습니다.
Corner Pooling
마지막으로 Corner Pooling입니다. 먼저 이 Corner Pooling을 왜 사용하는지에 대해 말씀을 드리자면 아래 그림과 같이, 어떠한 물체를 표시하는 bounding box의 각 코너로부터 해당 물체가 멀리 있는 경우가 존재합니다.

위와 같이 물체와 코너가 저 멀리 떨어지는 경우에도 코너를 알맞게 설정해주어야 하는데, 이를 설정할 때 사용할 마땅한 feature (논문에서는 이를 local visual evidence 라고 하네요.) 가 없는 상황입니다.
이를 해결하고자 논문에서는, 코너 지점에서 수평으로 쭉 향했을 때 object와 만나는 지점의 정보와, 수직으로도 쭉 가서 object와 만나는 지점의 정보를 이용하면 되지 않을까 라고 생각하였고 이를 통해 만든 것이 Corner Pooling 입니다.
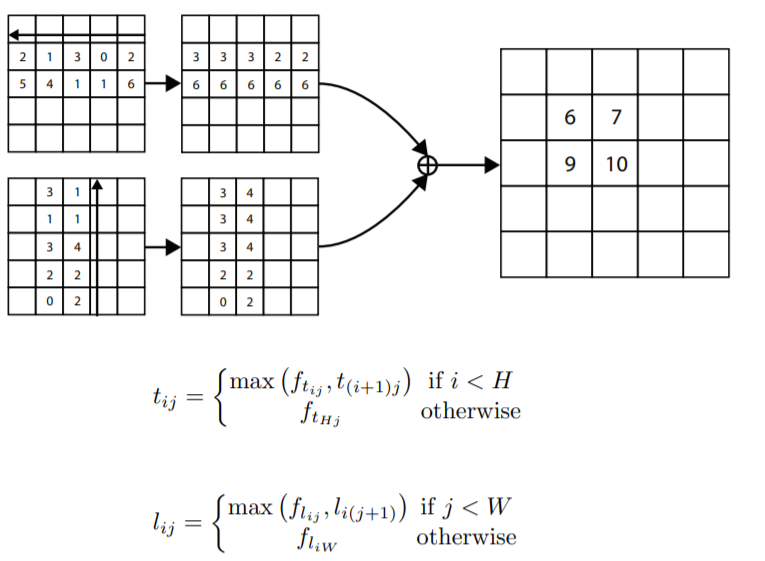
개념적으로 이해하는 것이 생각보다 어려우실 수 있는데 실제 작동 방식은 생각보다 매우 간단합니다. 먼저 위에 그림에서 첫번째 줄에 그림은 수평방향을, 두번째 줄에 그림은 수직방향에서 corner pooling이 적용되는 과정을 나타낸 것입니다.
방향은 수평기준 오른쪽에서 왼쪽으로 진행되고, 수직기준 아래쪽에서 위쪽으로 향합니다. 수평기준으로 설명드리면, 먼저 feature map에 제일 오른쪽에 위치한 2 값과 거기에 한칸 옆에 있는 0 값의 크기를 비교합니다.
그 중에서 값이 더 큰 값(해당 예시에서는 2)를 작은값에 위치에 덮어씌웁니다. 그 다음 2와 그 옆에 위치한 값 3을 비교하는데, 여기서는 3이 더 크기때문에, 해당 3값이 유지가 됩니다.
그 다음에 다시 3과 그 옆에 값 1과 비교하여 3이 더 크므로 1의 값은 3으로 대체되고, 이런식으로 쭉쭉 진행하게 됩니다. 수직 방향 역시 수평방향과 마찬가지로 아래서부터 크기 비교하여 값을 메꿔 나갑니다.
이 과정이 모두 마친 수평방향과 수직방향의 feature map을 이제 element wise sum을 진행하게 되는데, 그렇게 해서 나온 값(우측그림의 6, 7, 9, 10)이 바로 corner pooling의 결과값입니다.
Result

위에는 해당 CornerNet의 결과를 다른 One-stage detector들과 성능 비교한 표입니다. 보시면 정확도 측면에서는 CornerNet이 다른 detector들에 비해 높은 편에 속한 것을 확인하실 수 있습니다.

위에는 CornerNet의 정성적인 결과입니다. 논문에 올라온 사진이다보니 잘 검출한 영상들만이 올라와 있네요 허허.
동일한 수직 또는 수평선 상에 연속적으로 존재하게 되는 objects들에 적용되는 corner pooling의 효과에 대해서 자세히 설명해주세요!