ICCV2019에서도 발표된 논문으로 KCCV를 통해 알게됐고, 저자에게 직접 질문하며 논문의 Contribution을 이해할 수 있었던 논문입니다. (영어가 모국어였거나,내가 원어민처럼 잘했다면 국제학회는 이런느낌이겠구나를 간접적으로 체험할 수 있던 기회였습니다. )
배경지식
해당 논문의 핵심은 “Super-Resolution을 이용해 Small Object Detection을 찾아내자!” 입니다. 여기서 Super Resolution을 처음 듣는 분이 있을수도 있다고 생각돼 다음 그림을 통해 잠시 설명하겠습니다.

위의 영상에서도 잘 설명하고 있지만 다시 글로 나타내면 예를들어 10×10의 이미지는 가로 10 픽셀, 세로 10픽셀의 영상을 의미하며 이를 100×100으로 키운다고 가정하면 기존 100개의 픽셀을 가지고 10000개의 픽셀의 영상을 채워야하는 것을 의미합니다. 100개를제외한 나머지 9900개는 어떻게 할까요..? 기존 100개를 이용해서 만드는데 평균값으로 만들지 아니면 똑같이 만들지 등등 다양한 방법들이 존재하고 보통 이를 보간법(interpolation)이라고 명명합니다. 선형, 바이큐빅 등등 다양한 보간법들이 존재하고 딥러닝이 발전하면서 이러한 보간법도 딥러닝을 통해서 해결하고자 하는 연구들을 Super Resolution 이라고 합니다.
자 그러면 이정도로 Super Resolution의 설명을 마치고, 다시 Object Detection으로 돌아와서 Object Detection에서 다양한 난제들이 존재합니다. 예를들면 Occlusion이라고 부르는 Object가 가려진 문제도 있을 수 있고, 멀리있어서 작게 보이는 Object를 찾아내는 문제도 있을 수 있습니다. 그래서 이러한 문제들을 해결하기 위한 많은 연구가 이뤄지고 있으며, 이 논문은 Small Object Detection을 어떻게하면 잘 찾아낼 수 있을까에 대해서 다루고 있습니다.
Super Resolution과 Small Object Detection 이 두개를 합쳐 해당 논문은 Small Object를 기존 다른 네트워크들에 비해서 더욱 잘 찾아내고 있는데요. 해당 논문에서는 어떠한 방법을 사용하였을까요?
소개
처음 해당 논문의 제목만 보고 제가 생각한 컨셉은 위의 소제목과 같습니다. 하지만 해당 논문은 제 생각과는 다르게 이미지 자체의 Resolution을 키우는게 아니라 feature map의 Resolution의 크기를 키우고 있습니다. 하지만 이 아이디어는 다음 그림과 같이 기존에 있던 컨셉이라고 합니다.

위의 그림은 SR을 통해서 Small object의 feature map을 키우고 이를 가지고 평가를 진행하는 모델입니다. 여기서는 GAN의 Discriminator를 사용해 SR의 GT가 없지만 GT역할을 하도록 설계하여 모델을 학습시켰습니다. 하지만 해당 논문에서는 이러한 방법이 없는것보다 낫지만 최선의 방법은 아니라고 설명하고 있습니다.
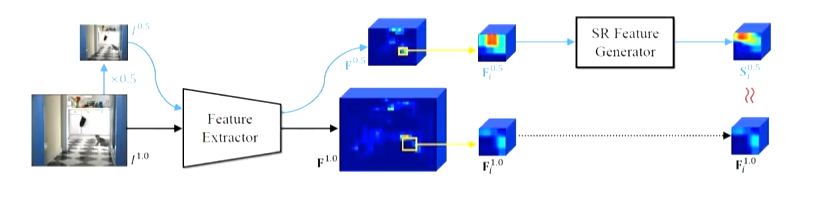
그렇다면 원래 이미지를 반으로 줄여서 그것을 원래 이미지와 동일한 Feature Extractor에 입력으로 넣고 해당 원본사이즈 그리고 반으로 줄인 사이즈의 이미지에서 추출한 각각의 피쳐맵을 가지고 이 둘이 같아지도록 학습을 시도하면 되지 안을까요?? 이는 가장 나이브한 방법입니다. 큰 문제는 없을것 같아 보이지만, 실제로는 가장 큰 문제를 갖는데 그것은 바로 두 이미지로 추출한 각각의 feature map의 ROI의 Receptive Field가 다르다는 점입니다. 어느정도 크기가 큰 Object는 괜찮겠지만 small object라면 이러한 Receptive Field가 RoI의 왜곡에 의해서 큰 영향을 받는다고 논문은 이야기하고 또 그것을 설명하고 있습니다. 그렇다면 이러한 문제를 어떻게 해결할 수 있을까요?
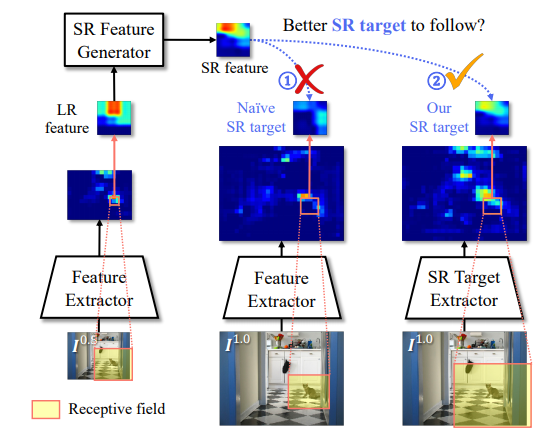
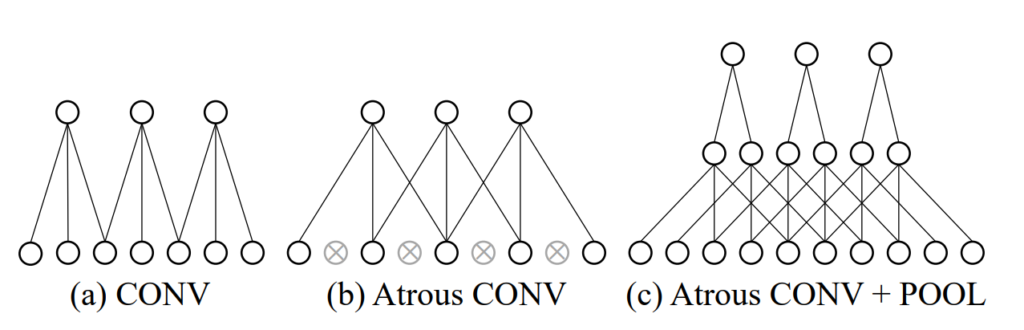
논문에서는 기존의 방법은 그대로 유지하돼, 작은 Object Detection에 대해서는 Receptive field가 달라지기 때문에 0.5 I와 1.0 I의 Feature Extractor 부분에서 0.5I는 기존 Feature Extractor를 사용하고 같은 weight를 share하지만 좀 더 Receptive field를 갖도록 설계된 SR Target Extractor를 통해서 1.0I의 이미지 피처를 추출하자는 것이 해당 논문의 Contribution 입니다. 정리하면 SR Target Extractor로 만들어진 feature map을 SR Feature Generator의 GT로 사용하는 것입니다. 여기서 weight를 share하면서 Receptive field를 키우기 위해서 사용된 방법은 Atrous Convolution과 POOLing을 결합한 방법입니다. 이러한 이유는 기존 Atrous 방법은 stride가 2가되 놓치는 부분이 있기때문에 해당 Atrous의 stride를 1로 변경하고 대신 Pooling을 진행하게 됩니다.
전체 네트워크
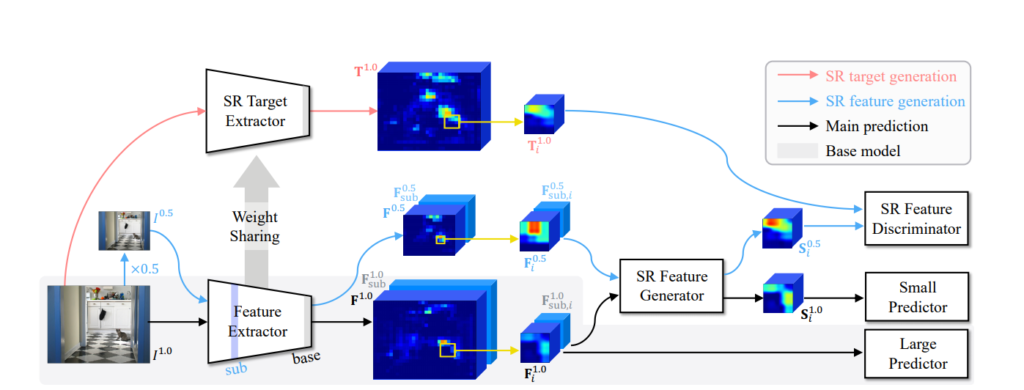
위의 그림이 전체 구조입니다. 기존의 방법처럼 원본 이미지와 이의 0.5 사이즈의 이미지를 가지고 Detection을 수행하는데 사이즈가 큰 이미지는 기존과 같은 방법으로, 사이즈가 작은 이미지는 SR Feature Generator를 이용해 새롭게 피처맵을 기술하고 이를 가지고 Detection을 수행하는 것 입니다. 이때 SR Feature Generator는 GAN의 구조로 Discrimnator와 함께 학습이 진행되는데 이때 Target 즉 GT는 앞서 언급한 기존 Feature Extractor와 weight는 share하지만 더 많은 receptive field를 반영하도록 만들어진 SR Target Extractor를 통해서 만들게 됩니다.
결과
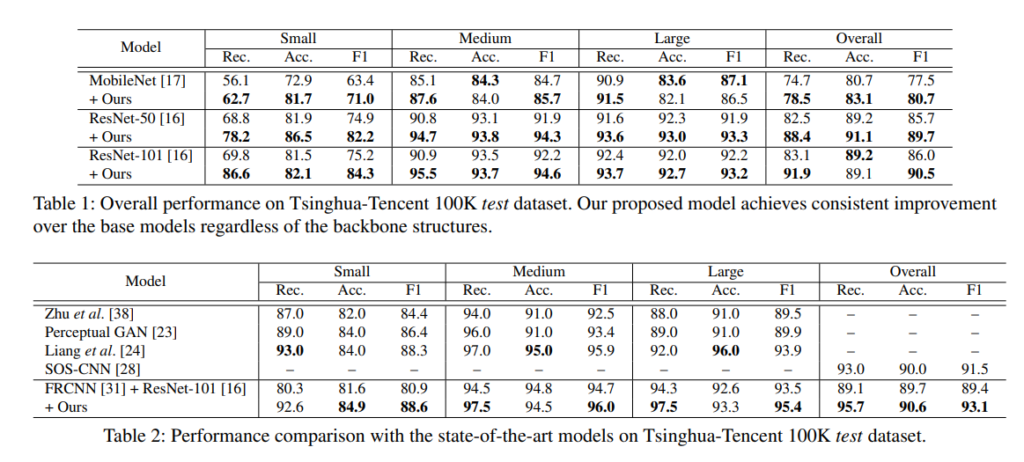
다른 방법론에 자신들의 아이디어를 적용했을때 Small object뿐만 아니라 전체적으로 성능 향상을 이루고 몇몇 데이터셋에 대해서는 SoTA를 달성할 수 있었다고 합니다.
정리
Small Object를 찾아내기 위해서 SR을 통해서 찾아내는 연구가 있다는 것을 새롭게 알게됐고, 하지만 SR을 사용하면서 발생하는 파라미터 갯수의 증가나 속도는 어떻게 해결할 수 있는지 의문이 들었습니다. 그리고 KCCV에서 해당 발표를 듣고 포스터 세션 시간때 해당 포스터 ZOOM에서 저자와 많은 이야기를 나누었습니다. 일단 해당 논문은 Faster-RCNN (혹은 비슷한 네트워크) 에서 사용되는 RPN을 이용합니다. 결국 네트워크가 예측한 ROI들에 대해서 다음 방법론을 적용해 성능을 향상시켰습니다. 이말은 RPN이 예측하지 못하는 영역에 대해서는 아무런 효과가 없는것이라고도 생각할 수 있습니다. 이에 대해서 저자분께서는 “그 부분이 우리가 제안하는 방법론의 한계이지만, 실제 ROI가 충분히 많이 뽑기 때문에크게 문제되지 않는다”라고 이야기했습니다. 그리고 object가 수 없이 겹쳐있는 상황이라면 SR을 통해서 없던 혹은 잘못된 feature가 생성될 순 없는지 질문드렸는데, 현재 논문은 각각의 Object이고 또 간혹 1~2개의 Object가 겹쳐있는 상황에서만 실험을 수행하여 다중의 Object가 겹쳐있는 경우까지 실험해보지 않았다고 이야기하셨습니다. 그리고 최종 네트워크를 보면 small object와 small object가 아닌 object에 대새서 마지막에 나눠서 진행하고 있는데, 왜 한번에 진행할 수 없는지 질문 드렸는데, “해당 내용에 대해서 실험을 진행하였는데 결국 나눠서 평가하는게 가장 좋은 성능을 나타냈다”고 설명해주셨습니다.