I. INTRODUCTION
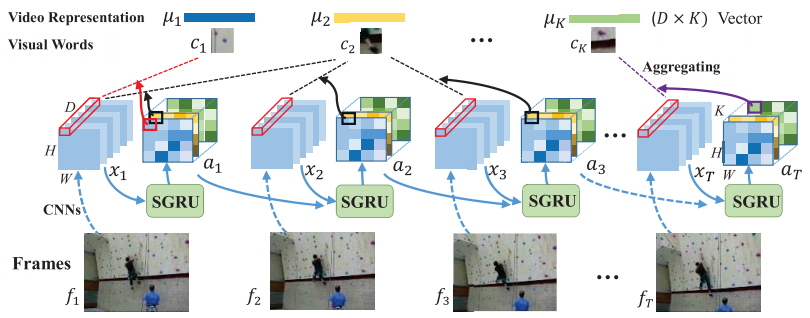
- Sequential Vidio VLAD layer를 제안한다. 학습 가능한 VLAD layer와 RCN 네트워크가 전체 framework에 다 들어 가 있다. Sequence한 VLAD layer를 RCN에 넣음으로 써 각 프레임의 정보 뿐만이 아닌 연속적인 영상들의 움직임 정보도 취합 할 수 있게된다.
- RCN의 하나의 방식인 GRU(Gated Recurrent Unit) 을 향상 시킨 SGRU(shared GRU)를 제안한다. 이는 보다 적은 파라미터를 갖고 있어 overfitting을 막고 좋은 성능을 보인다.
2. Shared GRU-RCN
RCN(Recurrent Convolution Networks)는 RNNs와 CNN을 잘 합쳐서 Videofeature를 잘 학습 시킬 수 있도록 만든 모듈이다 . 학습을 하며 RCN전체적인 visual의 변화에 집주하고 디테일한 움직임 정보는 버리는 경향성이 있는 것으로 확인 됐다. 이러한 문제를 해결하기 위해, GRU는 fully connected unit을 반복되는 Convolution으로 대체하였다. 이 과정에 의해서 , GRU-RCN은 input과 output는 3-dimensional feautue map이 된다.
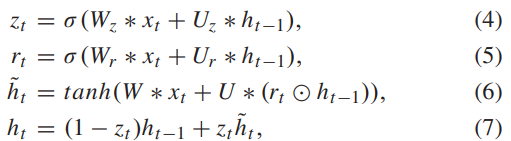
기존 GRU 유닛은 식 1과 같다. 세개의 W 파라미터로 다음 유닛에 정보를 전해주는 방식이다. 이 이후 Stack GRU같은 파라미터를 몇개를 쌓는 지에 대한 여러 논문에서 제시했지만, 파라미터의 깊이가 깊어지면 성능에 부담이 오고 오퍼피팅이 생기는 경향이 있는것이 확인됐다. 그러한 문제를 막기 위해서 SharedGRU(SGRU)라는 기존보다 파라미터가 적은 Unit을 이 논문에서 제안한다.
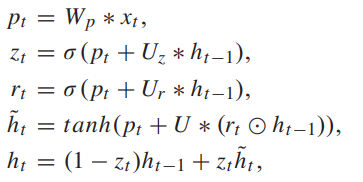
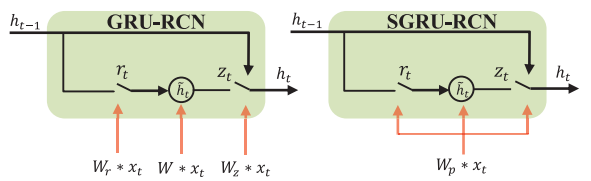
GRU와 SGRU의 차이는 그림 2를 통해서 간략하게 알 수 있고, 좀더 자세히 차이점을 이야기 하자면 ,식1과 2를 통해서 W가 3개에서 1개로 바뀐 것을 확인 할 수 있다.
3. Training Aggregation Locally and Temporally
그럼 SGRU feature 가 어떻게 NetVLAD에 적용되는지에 대해 이야기 해보도록 하겠다.
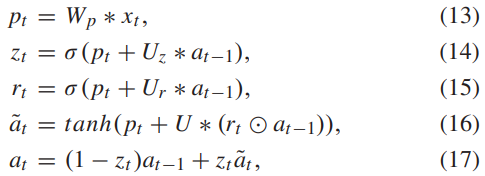
기존 NetVLAD에서 Softassignment 부분을 SGRU 의 Unit output으로 대체하는 것이 SeqVLAD의 방식이다.
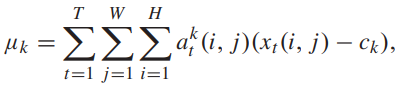
SGRU 를 통해서 assignment를 구한후 기존 NetVLAD처럼 곱한다음 더하면 Video의 VLAD descritptor를 얻을 수 있다. 기존 ActionVLAD는 assignment를 Conv으로 구해서 Seq한 정보를 활용할 수 없었지만 SGRU를 활용해 Seq한 정보를 이용해 더욱 성능 좋은 descriptor를 추출할 수 있게 되었다.
Result
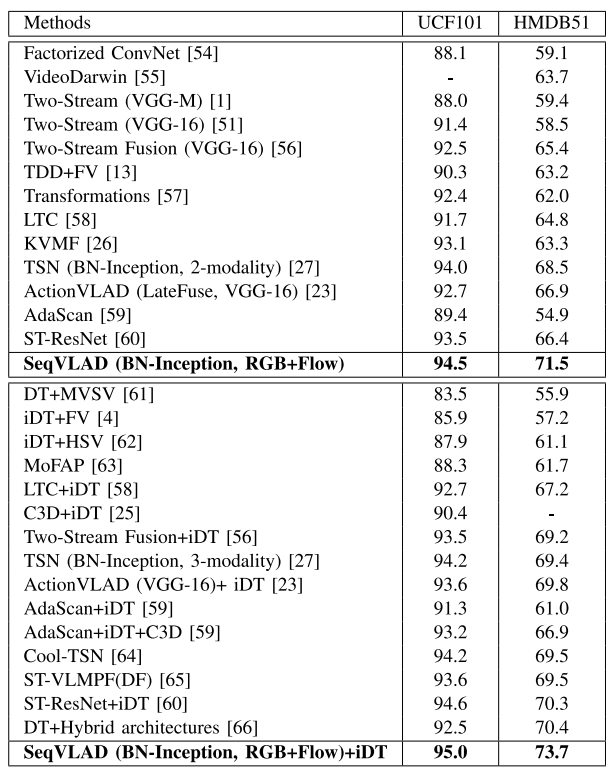
SeqVLAD는 Vald layer와 shared-GRU의 unit의 결합이 메인이고, NetVLAD와 동일하게 CNN으로부터 feature map을 추출한 값을 이용하는 것인가요? 그렇다면 어떤 backborn network를 사용하였나요?
맞습니다ㅏ. Resnet을 백본으로 사ㅛ했습니ㅏㄷ