이번 리뷰는 KCCV OE-03( 8/18 )에서 발표된 논문이며, 라이브로 해당 연구의 발표를 들으면서도 많은 흥미를 가지고 본 논문이기도 합니다.
최근 챌린지를 통해 3D object에 대한 관심이 생겼고, 3D object를 이용한 연구 및 방법론들이 2D 영상만을 이용한 방법론들의 한계를 극복할 수 있는 수단이 될 것이라는 생각에 해당 논문을 리뷰하게 되었습니다.
Intro
Visual recognition 문제에서 spatial transformations을 해결하기 위한 문제는 꾸준히 연구되어 왔습니다. 하지만 기존 연구들은 영상, 즉 이차원 공간에서 해결하는 것에 그쳐왔습니다.
하지만 view point는 3차원 공간에 존재하는 3D object로 부터 관측된 뷰포인트에 따라 영상의 모습이 달라지기 때문에 visual recognition 문제를 해결하는데 어려움이 발생합니다.
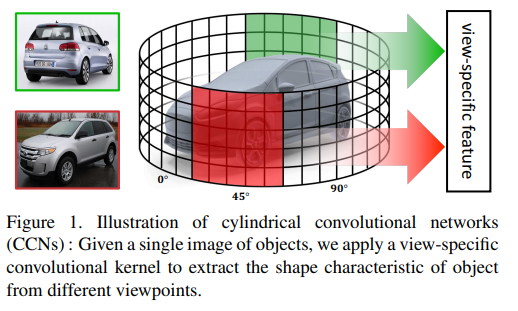
해당 방법론(Cylindrical Convolutional Network, 이하 CCN)은 3D object 주위의 3차원 공간에서 원기둥형 convolution kernel을 정의함으로써 view specific kernel이 특정 뷰포인트에서 얻을 수 있는 3d object의 feature를 얻는 것을 최종 목적으로 합니다.
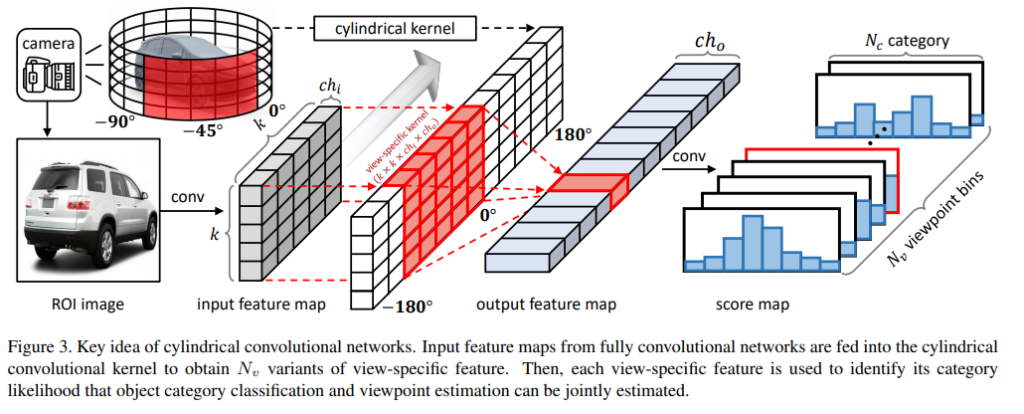
Proposed Method

첫번째로 CCN에 대해 설명을 드리자면, input으로 2d 영상을 CNN으로 통하여 얻은 2d feature map을 이용합니다. 제안한 cylindrical kernel과 convolution을 진행함으로써 최종적으로 여러개의 view point를 가진 output feature map을 얻을 수 있습니다.

이후 여러개의 output feature map을 view-space feature에 대한 classification을 진행하여 Nv * (Nc + 1)개의 score map을 얻게 됩니다.
얻어진 score map을 soft-max를 통해 normalization을 수행합니다.
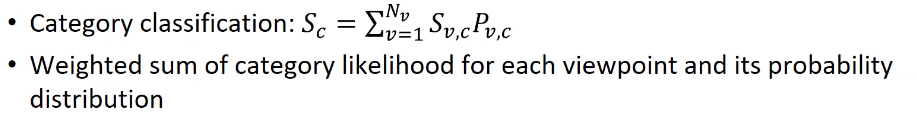
이후 첫번째로는 category classification을 수행하여 S_v,c(특정 뷰 포인트 빈), P_v,c 특정 클래스에 해당하는 score들에 대한 weight sum을 통해 객체 카테고리를 분류하게 됩니다.
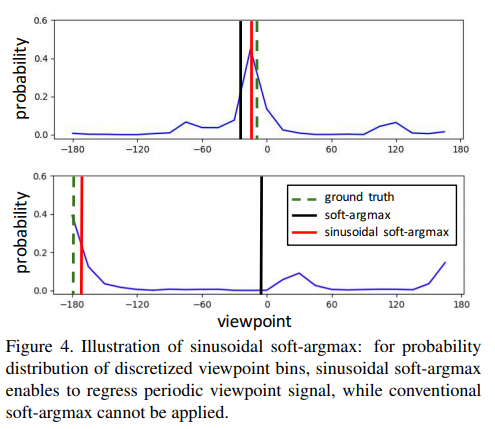
두번째로 view point estimation을 수행합니다. 이를 수행하기 위해서 뷰포인트는 continues 해야하며, 2파이(360도)의 주기성을 가져야합니다. 이를 해결하기 위해서 sinusoidal soft-argmax를 제안했습니다. 이를 통해 한번에 학습이 가능해지게 됩니다.
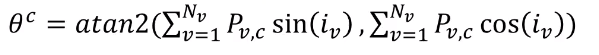
Experiments
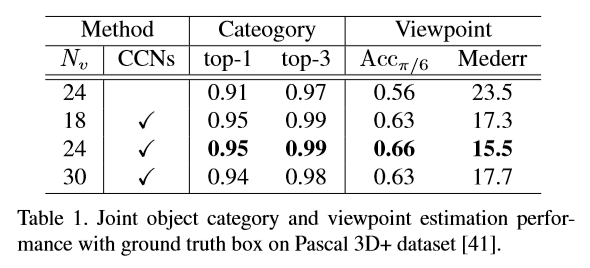
Nv -> 18~30 (뷰포인트 분할 구간)으로 나눴을때도 성능이 보장되는 것을 확인 할 수 있습니다.

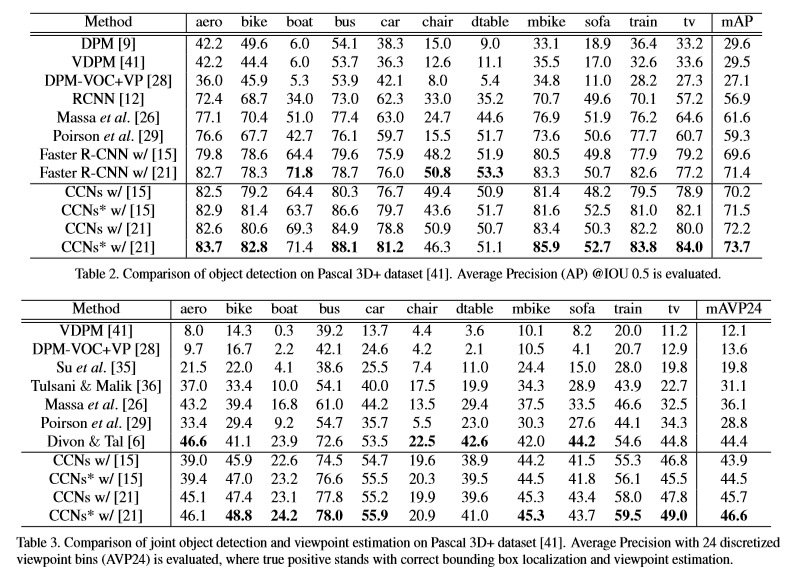
Grad-CAM(Fig 5. 2 row)에 비해 CCN(Fig 5. 3 row)이 전체적으로 object의 shape information을 정확히 추정 하는 것 을 볼 수 있습니다.
정략적인 결과


정성적인 결과
Conclusion
- CCN을 제안 joint object detection and viewpoint estimation에서 좋은 성능을 냄
- Viewpoint Variation을 해결하고자 3차원 공간에 원기둥 컨볼루션 컨얼을 정의 view-specific convolution kernel이 뷰포인트에 따른 3D 오브젝트의 2D을 피쳐를 효과적을 얻을 알 수 있었습니다.
- 보다 정확한 정확한 2D 추정을 위해서 sinusoidal soft-argmax를 제안하였다.
제안하는 network의 구조를 추가하면 더 이해가 쉬울 것 같습니다! 네트워크에서 view-specific features를 추출하는것이 원기둥 컨볼루션을 이용하여 추출 해서 view의 위치정보를 포함하게 되는 것인가요?