예전에 한번 Faster R-CNN 논문을 읽고 리뷰를 적었지만, 그 당시 내용을 지금 보니 많이 부족하다고 느꼈습니다. 그래서 이번 기회에 Faster R-CNN에 대한 code level까지 설명하는 tutorial 형식의 리뷰글을 작성하게 되었습니다.
설명에 사용한 코드는 https://github.com/chenyuntc/simple-faster-rcnn-pytorch 를 참고하여 제가 작성한 코드입니다.
혹시나 Faster R-CNN에 대해 처음 접하시는 분들은 부족하긴 하지만 저가 예전에 작성한 review (http://server.rcv.sejong.ac.kr:8080/2020/04/03/faster-r-cnn-%ec%a0%95%eb%a6%ac/) 를 읽고 오시면 좋을 듯 합니다.
Introduction
먼저 Faster R-CNN의 가장 큰 특징은 바로 Region Proposal Network(RPN) 입니다. 기존 Fast R-CNN은 Proposal을 Selective Search 알고리즘을 통해 추출하였는데, 이러한 방식이 속도의 큰 저하를 일으켰기에, Faster R-CNN에서는 Deep learning 방식으로 Proposal을 추출하는 Network를 설계하였습니다.
그 뒤에 방식은 Fast R-CNN과 동일하게 (RPN에서 나온) proposal을 가지고 Region of Interest(ROI)를 만들어서 ROI pooling 후에 FC layer로 Dection을 진행합니다.
Faster R-CNN의 학습 과정은 다음과 같은 흐름으로 작동합니다.
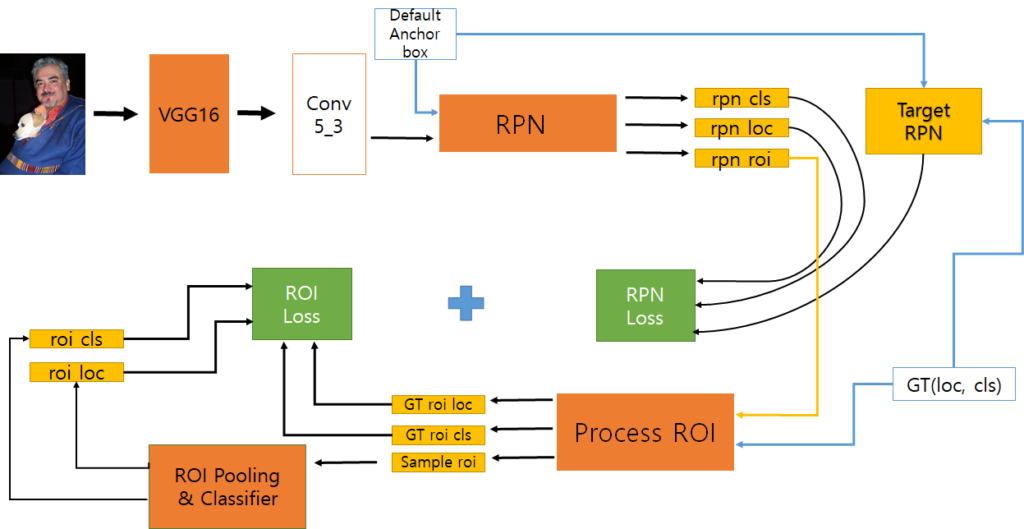
한눈에 보기에는 매우 복잡해 보이는데, 차근차근 과정을 살펴보면 크게 어렵지는 않습니다.
Data Augmentation
학습에 들어가기 전에 영상 전처리 과정부터 살펴보겠습니다. Faster R-CNN은 영상의 사이즈가 특정한 값으로 고정되어 있지 않습니다. 그저 하나의 조건만을 만족하면 되는데 이는 바로 영상에서 가장 긴 변이 최대 1000 또는 가장 짧은 변이 최대 600 해상도를 가져야만 합니다.
# Resize image W,H = dims min_size = min(W,H) max_size = max(W,H) min_range = 600 max_range = 1000 # 영상의 긴 변 또는 작은 변이 600~1000 사이어야 함. a = min_range/min_size b = max_range/max_size resize_scale = min(a,b) W = int(W * resize_scale) H = int(H * resize_scale) new_image = FT.resize(image, (H,W))
코드를 보시면 좀 더 이해하기 쉬우실텐데, 영상의 width와 height 중에서 긴변과 짧은 변을 구분하고, 그 후 각각의 제약범위(긴 변은 1000, 짧은 변은 600) 만큼 늘렸을 때 각각의 resize scale 중 보다 작은 scale을 골라서 적용시키는 것입니다.
이러한 방식으로 train 및 test 영상을 resize하다보니, 모든 영상들의 size가 각기 달라서 여러장을 batch로 묶어서 학습하지 않습니다.
마지막으로 Faster RCNN은 다양한 data augmentation을 적용하지 않고 단순히 horizontal Flip만을 적용하여 학습하였다고 합니다.
Feature extractor & Default Anchor Box
RPN의 input 값은 VGG16 네트워크를 통해 나온 Conv5_3 feature map과 Default Anchor box가 필요합니다.
VGG16은 Image-net으로 Pretrained된 모델을 이용하는데, 이때 Faster R-CNN의 연산량이 크다보니, VGG16의 모든 레이어를 학습하지 않고, Conv2 layer까지는 Freeze 시킨다고 합니다.
또한 뒤에 Detection Network에서 사용할 FC layer도 VGG16의 classifier를 사용하는데 이때 dropout은 제거하여 사용합니다.
def pretrained_vgg16(self): model = models.vgg16(pretrained=True) features = list(model.features)[:30] #freeze before conv3_1 for layer in features[:10]: for param in layer.parameters(): param.requires_grad = False classifier = list(model.classifier) del classifier[6], classifier[5], classifier[2] #뒤에서부터 del해야 함. features = nn.Sequential(*features) classifier = nn.Sequential(*classifier) return features, classifier
VGG16 pretrained 모델을 가져오는 코드
Default Anchor box를 만드는 과정 또한 간단합니다. Faster R-CNN에서는 Default Anchor를 만들기 위해 3개의 scale과 3개의 ratio를 통해 총 9개의 Default Anchor box를 Setting합니다.
그리고 해당 Setting 값을 Conv5_3 feature map에 Sliding하면서 만들게 되는데, 총(Conv5_3 feature map의 width * height * 9)개의 Anchor box가 만들어집니다.
def set_default_anchor(self):
ratio = [0.5, 1, 2]
scale = [8, 16, 32]#128, 256, 512 / pooling four time
cx = 8
cy = 8
default = torch.zeros((len(ratio) * len(scale), 4), dtype = torch.float32)
for i, r in enumerate(ratio):
for j, s in enumerate(scale):
w = 16 * s * math.sqrt(r)
h = 16 * s / math.sqrt(r)
index = i*len(scale) + j
default[index, 0] = cx - w/2.
default[index, 1] = cy - h/2.
default[index, 2] = cx + w/2.
default[index, 3] = cy + h/2.
return default.to(device)
def make_default_anchor(self,sets, height, width, stride = 16):
# start_time = time.time()
feat_H = torch.arange(0., height * stride, stride).to(device)
feat_W = torch.arange(0., width * stride, stride).to(device)
grid_y, grid_x = torch.meshgrid(feat_H, feat_W)
grid = torch.stack((grid_x.contiguous().view(-1),\
grid_y.contiguous().view(-1),\
grid_x.contiguous().view(-1),\
grid_y.contiguous().view(-1)), dim = 1)
# (W*H,1,4) + (1,9,4) = (W*H,9,4)
anchor = grid.unsqueeze(1) + sets.unsqueeze(0)
return anchor.view(-1,4)
Default Anchor를 Setting하는 함수와 이를 토대로 만드는 함수
해당 Default Anchor Box는 xyxy 좌표값으로 저장됩니다.
Region Proposal Network(RPN)
그러면 이제 RPN의 학습 과정을 살펴봅시다.
VGG16에서 나온 Conv5_3 feature map에서 한번 더 window size가 3인 layer를 통과시킵니다. 그 뒤에 나온 feature map을 가지고 각 셀 별로 RPN의 Location(offset(4) * anchor box 갯수(9))과 Class(objectness(2) * anchor box 갯수(9))를 predict하게 됩니다.
여기서 한가지 중요한 점은 RPN에서 Cls로 예측되는 값의 종류가 총 2가지입니다. 즉 어떤 object인지를 맞추는 것이 아니라, 해당 proposal에는 object가 존재하는가 안하는가를 나타내는 Objectness를 예측합니다.
#RPN Network를 설정할 때 각 layer setting 값 self.middleConv = nn.Conv2d(512, 512, kernel_size = 3, padding = 1, bias = True) self.locConv = nn.Conv2d(512, 4*9, kernel_size = 1, padding = 0, bias = True) self.clsConv = nn.Conv2d(512, 2*9, kernel_size = 1, padding = 0, bias = True) #network가 forward 할 때 학습 과정 middleConv = F.relu(self.middleConv(conv5_3)) locConv = self.locConv(middleConv) locConv = locConv.permute(0,2,3,1).contiguous() locConv = locConv.view(batch_size, -1, 4)#shape(1,w*h*9,4) clsConv = self.clsConv(middleConv) clsConv = clsConv.permute(0,2,3,1).contiguous() object_cls_score = F.softmax(clsConv.view(1, H, W, 9, 2), dim=4) object_cls_score = object_cls_score[:,:,:,:,1].contiguous().view(1,-1) clsConv = clsConv.view(batch_size, -1, 2)#shape(1,w*h*9,2)
RPN의 loc와 cls 예측 layer 설정
내용을 이해하시고 위에 코드를 보시면 한가지 궁금한 점이 있으실 것입니다. 바로 object_cls_score라는 변수인데, 이 값은 RPN network에서 나온 RPN_loc와 RPN_cls 값을 가지고 Object Detection에 사용할 ROI를 구할 때 사용됩니다.
제가 작성한 코드에서는 RPN에서 ROI를 구하는 과정까지 다 진행을 하게 되는데, ROI를 구하는 과정은 뒤에서 자세히 설명하겠습니다.
Target RPN
RPN에서 proposal의 loc와 cls를 예측하였으니, 이제 학습을 하기 위해서는 Gt proposal도 만들어야 합니다. Gt proposal을 만드는 과정은 다음과 같습니다.
- 범위를 벗어난 anchor box들을 제거하여 valid box만을 남긴다.
- GT box와 anchor box들 간에 IOU를 구한다.
- 구한 IoU를 토대로 정해진 제약 조건을 통해 positive, negative proposal을 나눈다.
- positive proposal과 negative proposal들 중에 n개의 sample만을 1:1 비율로 sampling하여 최종적으로 가져온다.
먼저 저가 위에서도 설명드렸지만 초기에 anchor box는 Conv5_3 feautre map의 width * height * 9 개가 만들어진다고 했습니다. 그렇게 되면 영상의 해상도가 최대 1000*600 이라고 가정했을 때 anchor의 갯수도 최대 24000개가 만들어집니다.
이 때 영상의 테두리 쪽에 위치한 anchor box들 중에는 영상의 범위를 벗어난 박스들이 존재합니다. 먼저 이렇게 벗어난 박스들은 제거하고 영상 해상도 범위 내에 존재하는 박스들(valid anchor)을 남깁니다.
valid_anchor_index = np.where((anchor_np[:,0] >=0) &\ (anchor_np[:,1] >= 0) &\ (anchor_np[:,2] <= W) &\ (anchor_np[:,3] <= H))[0] valid_anchor = anchor[valid_anchor_index]
valid anchor만 추출하는 코드
그 후 valid anchor와 gt box의 loc값을 통해 IoU계산을 하여 overlap을 구합니다. 그 다음 Overlap이 큰 anchor들로 정렬을 하여 특정 제약조건을 토대로 positive와 negative 구분을 진행하는데, 제약조건은 다음과 같습니다.
- 일정 positive threshold보다 크면 positive proposal, negative threshold보다 작으면 negative proposal로 구분한다.
- 비록 positive threshold를 넘지 못하더라도, overlap이 가장 큰 proposal들은 positive로 놓는다.
논문에서는 positive threshold를 0.7, negative threshold를 0.3으로 설정했습니다. 그리고 0.3~0.7 사이의 값들은 negative도 positive도 아니기에, ignore 처리한 채 학습에 사용하지 않습니다.
valid_anchor = anchor[valid_anchor_index]
overlap = find_overlap_rpt(boxes, valid_anchor)
max_overlap, max_overlap_label = overlap.max(dim=0)
#영상 속 gt obj 각각의 가장 큰 iou의 index
max_overlap_obj = overlap.argmax(dim=1)
#positive label은 1, negative label 0을 부여. 그 외 중간 값들은 -1인 상태
anchor_label = torch.full(max_overlap.shape, -1, device = 'cuda')
anchor_label[max_overlap < 0.3] = 0
anchor_label[max_overlap >= 0.3] = -1
tmp = overlap[torch.arange(0, overlap.size(0), 1), max_overlap_obj].detach().cpu().numpy()
overlap_clone = overlap.clone().detach().cpu().numpy()
max_overlap_index = list()
for i in range(overlap.size(0)):
max_overlap_index.extend(np.where(overlap_clone == tmp[i])[1].tolist())
#가장 높은 iou값들은 항상 postiive (case2)
anchor_label[max_overlap_index] = 1
#일정 th 이상인 iou들은 postiive (case1)
anchor_label[max_overlap >=0.7] = 1
#가장 큰 iou는 항상 pos anchor
max_overlap[max_overlap_index] = 1.
overlap 연산 후 제약 조건에 맞추어 postiive와 negtaive proposal을 설정
자 그러면 이제 valid anchor들 중에서 gt box와 overlap 큰 anchor를 positive proposal, overlap이 매우 작은 anchor를 negative proposal, 그 외에는 ignore proposal로 나누었습니다.
하지만 아직도 문제가 하나 존재하는데, 이는 바로 negative proposal이 positive proposal보다 훨씬 더 많다는 점입니다. 이러한 positive와 negative의 imbalance는 학습에 큰 영향을 주기에, 저희는 positive와 negative를 각각 1:1 비율로 256개 만큼 sampling합니다.
neg_index = np.where((anchor_label == 0).cpu())[0] pos_index = np.where((anchor_label == 1).cpu())[0] n_pos = int(self.pos_ratio * self.mini_batch) if pos_index.size > n_pos: ignore_index = np.random.choice(pos_index, size = pos_index.size - n_pos, replace = False) anchor_label[ignore_index] = -1 n_pos = (anchor_label == 1).sum().item() n_neg = self.mini_batch - n_pos if neg_index.size > n_neg: ignore_index = np.random.choice(neg_index, size = neg_index.size - n_neg, replace = False) anchor_label[ignore_index] = -1
positive와 negative를 sampling 하는 코드
이 때 만약 positive의 개수가 128개가 되지 못한다면, 남은 숫자는 negative로 보충해서 넣습니다. 즉 positive가 28개밖에 없다면, negative는 128+(128-28)개 만큼 sampling합니다.
위의 과정들을 통하여 최종적으로 pos와 neg의 index를 가지고 Proposal의 labeling을 적용하여 Target label과 Target loc를 구합니다.
gt_loc = convert_cxcy_gxgy(convert_xy_cxcy(boxes[max_overlap_label]),\ convert_xy_cxcy(valid_anchor)) target_label = torch.full((anchor.shape[0],), -1, device = 'cuda') target_label[valid_anchor_index] = anchor_label target_loc = torch.full((anchor.shape), 0, device = 'cuda') target_loc[valid_anchor_index, :] = gt_loc return target_loc, target_label
최종적인 TargetRPN return 값
RPN Loss
Loss는 매우 간단합니다. RPN에서 예측한 proposal의 class값과 gt porposal class끼리는 CrossEntropy를, loc값끼리는 smooth L1Loss를 적용합니다.
CrossEntropy는 잘 아실테니 설명을 넘어가고, smooth L1Loss는 Faster R-CNN에서 제안된 loss인데 간략하게 설명하면 L1 loss보다 더 빠르게 수렴하는 것으로 아시면 될 것 같습니다. Pytorch에서 smoothL1loss를 제공하고 있습니다만, 저는 참고한 코드를 따라 코드로 작성하여 사용했습니다.
def RPNLOSS(self, predicted_locs, predicted_cls, gt_locs, gt_cls):
rpn_loc = predicted_locs[0]
rpn_cls = predicted_cls[0]
cls_loss = self.rpn_cross_entropy(rpn_cls, gt_cls.long())
N_reg = (gt_cls >= 0).sum().float()
in_weight = torch.zeros(gt_locs.shape).cuda()
in_weight[(gt_cls > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1
loc_loss = self._smooth_l1_loss(predicted_locs, gt_locs, in_weight, self.rpn_sigma)
loc_loss = loc_loss / N_reg
return cls_loss + (self.rpn_lambda * loc_loss)
def _smooth_l1_loss(self, x, t, in_weight, sigma):
sigma2 = sigma ** 2
diff = in_weight * (x - t)
abs_diff = diff.abs()
flag = (abs_diff.data < (1. / sigma2)).float()
y = (flag * (sigma2 / 2.) * (diff ** 2) +
(1 - flag) * (abs_diff - 0.5 / sigma2))
return y.sum()
ROI sampling
RPN에 대하여 끝났으니 ROI에 대해서 알아봅시다. 위에 RPN 파트를 설명할 때 object_cls_score를 통하여 roi를 구한다고 했습니다. 그것에 대해서 자세히 알아보도록 합시다.
먼저 우리는 초기 anchor box가 최대 24000개까지 만들어지는 것을 알고 있습니다. 그리고 이렇게 만들어진 anchor와 RPN에서 예측한 rpn loc값을 통해 roi를 만들게 되므로, roi 역시 초기에 최대 24000개가 생성됩니다.
이렇게 많은 roi를 학습에 다 사용하기에는 필요없는 roi들이 많고, 연산량도 많기에 우리는 여러 제약조건을 통해 학습에 필요한 roi만을 고르는 작업을 해야합니다.
그리하여 roi를 고르는 첫번째 작업은 해당 roi의 objectness를 내림차순으로 정렬하여 1.2k개만큼 자르는 것입니다. 이때 objectness를 기준으로 roi를 sampling 하기 위해 object_cls_score 변수를 미리 만들어 둔 것입니다.
object_cls_score는 predict rpn cls[1]에서 가져오게 되는데, 이는 rpn cls가 object의 존재여부(0 또는 1)를 나타내는 값이므로, 그 중 존재하는 값들을 사용하는 것입니다.
요약하자면 object가 존재하는 proposal들 중에, 가장 확률 값이 높은 순서대로 나열하여 해당 인덱스에 위치한 roi를 가져온다고 보시면 될 것 같습니다.
그리고 roi도 역시 영상의 해상도 범위를 벗어난 것들이 존재합니다. 이때 Target RPN에서와 같이 범위를 벗어난 박스들을 제거해버리는 것이 아니라, 0~img size만큼의 영역으로 제한시켜버립니다. 위에 내용에 대한 코드는 아래와 같습니다.
roi_xy = convert_cxcy_xy(convert_gxgy_cxcy(locConv[i],\
convert_xy_cxcy(default_anchor)))
#clip the predicted box
roi_xy[:,0::2] = torch.clamp_(roi_xy[:,0::2], min = 0, max = img_W)
roi_xy[:,1::2] = torch.clamp_(roi_xy[:,1::2], min = 0, max = img_H)
#remove predicted boxes with either hieght or width < threshold size
roi_xy = roi_xy.detach().cpu().numpy()
ws = roi_xy[:,2] - roi_xy[:,0]
hs = roi_xy[:,3] - roi_xy[:,1]
min_scale = self.min_scale * resize_scale
keep = np.where((ws >= min_scale) & (hs >= min_scale))[0]
roi = roi_xy[keep, :]
object_score = object_cls_score[i,keep]
#score가 높은 순으로 내림차순 진행(argsort에서 descending하면, index의 내림차순이 아닌 score의 내림차순으로 정렬됨)
order = torch.flatten(object_score).argsort(descending = True)
order = order[:n_pre_nms].detach().cpu().numpy()
roi = roi[order, :]
#기존 order를 pre_nms만큼 잘랐으니, 범위에 맞추어 인덱싱 하기 위해 다시 argsort를 함.
object_score = object_score[order]
order = object_score.argsort(descending = True).detach().cpu().numpy()
초기 roi의 개수를 1.2k개 이하로 처리하는 코드
자 그러면 이제 roi에 대한 전처리 과정이 어느정도 완료가 되었는데요, 그래도 아직 roi의 개수가 많기는 합니다. 이는 roi끼리 매우 촘촘하게 분포하기 때문인데, 아래 그림을 보시다시피 기존 default anchor 자체가 매우 dense하게 위치합니다.
그래서 objectness가 높은 순으로 proposal을 뽑아 roi의 개수를 1.2k 이하로 줄이더라도, 해당 proposal 위치에는 아직 많은 양의 roi가 존재하게 되는 것입니다.

초기 Valid anchor box
이를 해결하고자 NMS 과정을 진행하게 됩니다. NMS는 쉽게 말하면 어떠한 object에 대하여 비슷한 overlap을 가진 box들이 다닥다닥 붙어있는 것을 하나의 box만 남도록 제거하는 기법으로 다양한 object Detection 알고리즘에서 사용됩니다. NMS에 대하여 자세한 설명은 https://towardsdatascience.com/non-maximum-suppression-nms-93ce178e177c 에서 확인하실 수 있습니다.
NMS 과정을 거치면 대략 2000개 정도의 roi로 추려지게 되는데 이중에서 학습 시에는 최대 2000개의 roi만을 학습에 사용합니다.(test시에는 300개)
#NMS x_min = roi[:,0] y_min = roi[:,1] x_max = roi[:,2] y_max = roi[:,3] area = (x_max - x_min) * (y_max - y_min) keep = [] while order.size > 0: i = order[0] left_top = np.maximum(roi[i,:2], roi[order[1:],:2]) right_bot = np.minimum(roi[i,2:], roi[order[1:],2:]) wh = np.maximum(0.0, right_bot - left_top) intersect = wh[:,0] * wh[:,1] iou = intersect / (area[i] + area[order[1:]] - intersect) inds = np.where(iou <= 0.7)[0] keep.append(i) order = order[inds + 1] keep = keep[:n_post_nms] roi = torch.FloatTensor(roi[keep]).to(device) batch_roi.append(roi) return locConv, clsConv, batch_roi, default_anchor
NMS 처리 및 최종 ROI를 반환하는 코드
Target ROI
이제 roi에 대하여 학습하기 위해서 roi 대한 target을 만들어야 합니다. 해당 작업의 과정은 다음과 같습니다.
- 각각의 roi에 대해서 gt box와 IoU계산을 통해 overlap을 구한다.
- 구한 overlap에 특정 제약 조건을 만족하면 positive, 만족하지 못하면 negative로 분류한다.
- 분류된 roi들 중에서 positive와 negative 를 각각 1:3 비율로 총 128개에 맞추어 random sampling 한다.
얼핏 보시면 RPN target을 구할 때와 과정이 유사해보이며 실제로도 그렇습니다. 먼저 gt box와 roi간에 overlap을 구한 후 영상 속 object와 가장 큰 overlap을 가진 roi에 대하여 positive label을 부여합니다.
그 후 일정thresh hold(0.5)를 넘은 roi는 positive, 그렇지 못하면 negtaive로 분류하게 됩니다. 코드 상으로는 아래와 같습니다.
n_obj,_ = box.shape overlap = find_overlap_rpt(box, roi) high_overlap, high_overlap_label = overlap.max(dim=0) #case2 각 label별로 가장 높은 iou를 가진 iou는 항상 pos prior_max_overlap = overlap.argmax(dim=1) #RPN taget anchor와 달리 가장 큰 iou는 각 obj별로 1개씩 밖에 없음. high_overlap[prior_max_overlap] = 1 high_overlap_label[prior_max_overlap] = torch.LongTensor(range(n_obj)).to(device) gt_label = label[high_overlap_label] # thresh hold로 pos neg 분리 pos_index = self.pos_iou_thresh <= high_overlap pos_index = pos_index.detach().cpu().numpy() neg_index = np.where(pos_index == 0)[0] pos_index = np.where(pos_index == 1)[0]
그 후에 positive와 negative를 1:3 비율로 하여 128개를 뽑아야하는데, 다시 말해 positive는 최대 32개, negative는 96개를 random하게 sampling 해야 합니다.
그리고 만약 positive가 32개 미만일 경우 negative에서 보충하여 128개를 채웁니다. 하지만 종종 negative도 개수가 모자라 전체 roi 개수를 128개로 못 맞출 때가 있는데, 어처피 뒷단에 classifier에서 FC layer를 통과하기에 반드시 128로 크기를 맞출 필요는 없습니다.
#pos neg 비율 1:3으로 맞춰주는데, 이때 무작위로 선별하여 가져온다. if pos_index.size != 0: rand_size = int(min(pos_index.size, self.n_sample * self.pos_ratio)) pos_index = np.random.choice(pos_index, size = rand_size, replace = False) if neg_index.size != 0: rand_size = int(min(neg_index.size, self.n_sample - pos_index.size)) neg_index = np.random.choice(neg_index, size = rand_size, replace = False) sample_index = np.append(pos_index, neg_index)#pos+neg로 총 128개의 sampling index를 의미.
randomsampling 하는 코드
최종적으로 sampling 된 index를 통하여 gt loc와 gt cls를 가져오며, 학습할 때에도 역시 sampling 된 roi를 바로 사용하기에, sample roi도 반환합니다. 그리고 혹시나 학습이 안된 초기에 올바르게 학습을 하고자 gt값 그 자체를 해당 반환값에 추가하여 반환합니다.
gt_label = gt_label[sample_index] gt_label[pos_index.size:] = 0 #neg == background == 0 sample_roi_xy = roi[sample_index]#sample_roi.shape = (n_sample, 4) sample_roi_cxcy = convert_xy_cxcy(sample_roi_xy) #sample_roi와 loc regression을 할 gt box를 sample index로 불러옴 gt_box_xy = box[high_overlap_label[sample_index]] gt_box_cxcy = convert_xy_cxcy(gt_box_xy) gt_locs = convert_cxcy_gxgy(gt_box_cxcy, sample_roi_cxcy) add = torch.FloatTensor([0., 0., 0., 0.,]).unsqueeze(0).expand_as(box).to(device)#(n_objects, 4) gt_locs = torch.cat((gt_locs, add), dim = 0) #(n_sample + n_objects, 4) sample_roi_xy = torch.cat((sample_roi_xy, box), dim = 0) gt_label = torch.cat((gt_label, label), dim = 0) gt_locs[:,:2]=gt_locs[:,:2]*10 gt_locs[:,2:]=gt_locs[:,2:]*20 return sample_roi_xy, gt_locs, gt_label
ROI Target의 최종 반환 값
ROI Pooling
ROI Pooling은 Fast R-CNN에서 이미 사용하는 기법이기에 간략하게 설명드리겠습니다. 저희가 위에 과정들을 통해 구한 roi는 일정한 값으로 정해져있지 않고, 어떤 물체인지에 따라 크기가 제각각으로 다릅니다.
하지만 FC layer를 통과하여 분류를 하기 위해서는 각각의 roi들 크기가 서로 동일해야 하므로 크기를 맞춰주기 위해 pooling 작업을 진행해야 합니다. 즉 input으로 들어오는 roi의 크기와 상관없이 항상 고정된 크기(VGG16 기준 7×7)의 roi를 출력하도록 해야합니다.
코드는 아래와 같습니다.
def ROIPool(self, feature, sample_roi): img_index = torch.zeros(len(sample_roi), device='cuda') # shape(N,5) N is the num of roi, 5(0 = img_index, 1~4 = roi_xy coordinate) img_roi = torch.cat([img_index.unsqueeze(1),sample_roi], dim = 1) output = [] img_roi[:,1:].mul_(1/16.) #product sub_sample ratio img_roi_clone = img_roi.clone().long() for rr in img_roi_clone: im_idx = rr[0] im = feature.narrow(0,im_idx,1)[..., rr[2]:(rr[4]+1), rr[1]:(rr[3]+1)]#feature크기 서순이 C,H,W이므로 y좌표,x좌표 순으로 인덱싱 output.append(self.pool(im)) output = torch.cat(output, dim = 0)#(128, 512, 7, 7) return output.view(output.shape[0], -1)
ROI Pooling code
코드를 보시면 먼저 roi에 값이 input size 크기에 맞춰있기에, 이들 값을 16으로 나누어 Conv5_3 feature map과 동일한 사이즈로 맞추어줍니다.(Pooling이 총 4번 있으므로 16으로 나누어 줌.)
그 후 feature map에 대하여 roi별 값으로 section을 나눈 다음, pytorch에서 제공하는 AdaptiveMaxPool2d을 사용하면 ROI Pooling이 완료됩니다.
그 후에는 7×7로 pooling된 roi들을 reshape 하여 FC layer의 크기와 맞춘 다음 roi의 cls와 loc 값을 예측하면 됩니다.
def forward(self, feats, sample_roi, image): norm = feats.pow(2).sum(dim=1, keepdim=True).sqrt() feats = feats / norm feats = feats * self.rescale_factors pool_roi = self.ROIPool(feats, sample_roi) out = self.roi_classifier(pool_roi) roi_cls_loc = self.loclayer(out) roi_cls_score = self.clslayer(out) return roi_cls_loc, roi_cls_score
ROI Classifier를 통해 roi_cls와 roi_loc를 예측하는 코드
ROI Loss
ROI loss는 RPN loss와 마찬가지로 저희가 구한 predict cls와 target cls 끼리는 Cross entropy를, loc끼리는 Smooth L1Loss를 진행하면 되므로 설명을 생략하도록 하겠습니다.
Conclusion
최종적으로는 저희가 위에서 구한 RPN Loss값과 위에 ROI loss값을 합쳐서 만든 total loss를 backward 시키면 학습이 한번 완료됩니다.
해당 글에서 설명드리지 않은 세부적인 디테일을 짧게 적고 글을 마무리 하도록 하겠습니다.
- VGG16에서 conv3~5를 제외하고, Faster R-CNN에 사용되는 모든 Layer들은 mean = 0, std = 0.01의 random weight init을 하였습니다.
- ROI에 대한 loc loss가 cls loss에 비해 상당히 작은 scale의 값을 가지고 있으므로 해당 값에 가중치를 곱해줘야 좋은 학습 결과를 얻을 수 있습니다.
- 학습은 Pascal VOC 2007을 기준으로 60k(lr 0.001) 와 20k(lr 0.0001) 총 80k iteration을 통해 학습하였으며 성능은 아래와 같습니다.
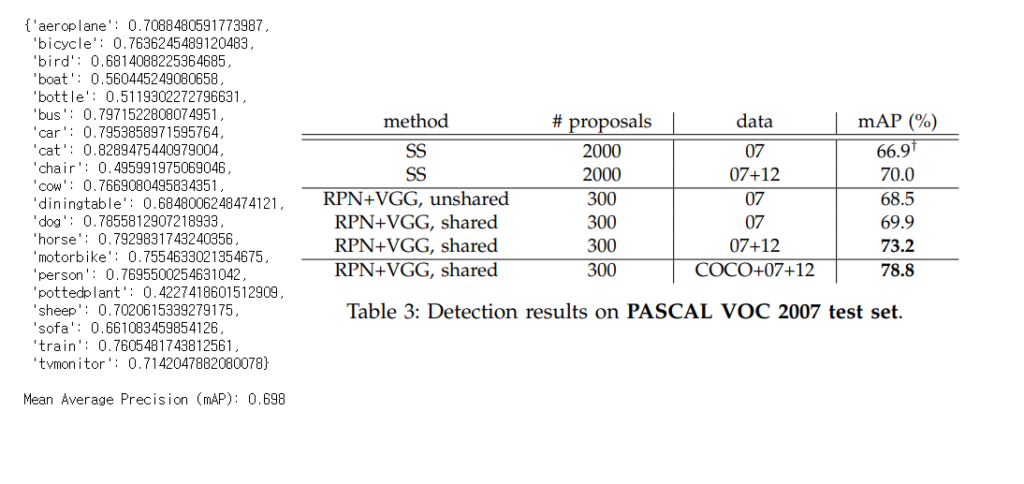
tutorial code 성능(좌측)과 Faster R-CNN논문 성능(우측)
“영상에서 가장 긴 변이 최대 1000 또는 가장 짧은 변이 최대 600 해상도를 가져야만 합니다.” 라고 하셨는데, 코드단을 보면 최대, 최소 모두 1000, 600 이상으로 resize 시키는걸로 보이는데 이유가 있나요? 두 개중에 하나만 조건을 충족시켜도 지장이없는건가요? 두개 중에 하나만 충족시켜도 성능에 지장이 없는지 궁금했습니다.
그리고 Faster RCNN은 Selective-search 가아닌 Deep- learning 방식의 RPN을 사용하여 속도를 향상시켰다가 메인컨셉인거 같은데, 이 속도가 향상된 이유가 GPU연산을 가능하게 함으로써 속도가 향상된게 맞나요?
질문 감사합니다.
먼저 첫번째 질문에 대한 답을 드리자면, 코드 상에서는 문제가 없습니다만 제 설명이 조금 헷갈린듯 하여 코드에 대한 자세한 예시를 보이겠습니다.
먼저 resize 전 크기가 width = 400, height = 300인 영상이 있다고 가정하겠습니다. 해당 resize 함수에서 먼저 min과 max함수를 통하여 어느변이 짧고 긴지를 결정하게 됩니다.(해당 예시에서는 W가 max_size, H가 min_size가 되겠네요.)
그 후에는 짧은 변은 600으로 나누고, 긴 변은 1000으로 나누게 되는데, 그렇게 되면 짧은 변의 몫은 2가 되고(600/300 = 2) 긴 변의 몫은 2.5가 됩니다.(1000/400 = 2.5)
그 후 해당 몫에 대해 min 함수를 통하여 최소값을 구하게 되는데 이 값이 resize_scale 값이 됩니다. 이 예시에서 resize scale은 2가 됩니다.
그 후 해당 resize scale을 각 width와 height에 곱하게 되면 800,600이 되므로 짧은 변이 600이거나, 긴 변이 1000이 되는 조건 중 짧은 변이 600이 되는 조건을 성립하게 됩니다.
이런 방향성으로 영상들을 계속해서 resize하게 되는데, 만약 width가 500이고 height가 200이라면, resize scale은 height의 몫보다 더 작은 width의 몫을 사용하게 될 것입니다.(3>2)
그럼 최종 resize 결과도 width = 1000, height = 400이 되므로 긴변이 1000이 되는 상황을 만족하게 됩니다.
결론적으로는 반드시 긴변이 1000이 되거나, 짧은 변이 600이 되게끔 resize가 적용된다고 보시면 될 것 같습니다.
두 번째 질문에 대한 대답을 드리자면, GPU연산도 속도의 향상을 주었다고 볼 수 있지만, 가장 메인 키 포인트는 한번 추출한 Convolution feature map을 공유하여 Proposal 및 roi 추출에 사용했다는 점입니다.
기존에 Fast R-CNN은 selective search를 통해 따로 proposal을 구하고, roi는 feature map에 투영시켜 roi pooling등의 작업을 통하여 추출하였습니다. 여기서 어처피 roi를 추출할 때 feature map을 사용한다면 proposal을 추출할 때도 해당 feature map을 같이 사용할 수는 없을까? 해서 만들어진게 Faster R-CNN입니다.
즉 한번 추출한 Conv5_3 feature map을 가지고 proposal도 추출하고, roi도 추출하는 알찬? 모습을 통하여 속도를 줄인 것으로 생각하시면 될 것 같습니다. 물론 feature map을 가지고 proposal을 추출하기 위해서는 말씀하신대로 Deep learng 기반의 layer를 학습해야 합니다. 즉 학습 때 GPU를 사용하므로 얻는 이점도 있을 것입니다.
Pascal Voc trainval dataset을 모두 사용하셨나요? 아니면 difficult는 빼고 학습하셨나요?