
이번 리뷰는 오랜만에 GAN 논문을 들고 왔습니다. GAN은 정말 다양하고 창의적인 영상을 만들어냄으로써 여러 분야에 사용할 수 있는데, 해당 논문은 예술작품을 주제로 삼았습니다.
좀 더 부연설명을 하자면 기존의 GAN이 어떻게 학습하면 창의적인 영상을 만들어낼 수 있을지에 대해 연구한 논문으로, 기술적으로 훌륭한 방법론을 제안하거나 그러지는 않습니다. 그래도 한번 읽어보기에는 흥미로운 내용들이 많으니, 해당 분야에 대해 흥미있으시거나 그렇지 않으시더라도 가볍게 읽으시기엔 좋을 듯 하여 리뷰합니다.
만약 우리가 기계에게 예술 작품과 예술의 스타일(장르)에 대해 학습을 시킨 후, 완전히 새로운 형식의 예술 작품을 만들라고 한다면, 기계는 무슨 작품을 만들어 낼까요?
그리고 기계가 만들어낸 작품이 사람이 봐도 그럴듯한, 예술적인 작품이 될 수 있을까? 마지막으로 이러한 제품에 대해서 우리는 예술이라고 말을 할 수 있을까?
해당 논문은 이러한 질문을 가진 채로 시작합니다. 논문의 목표는 Generator가 창의적인 예술작품을 만들어내는 것이지만, 그렇다고 해서 너무 창의적으로 만들면 안된다고 합니다.
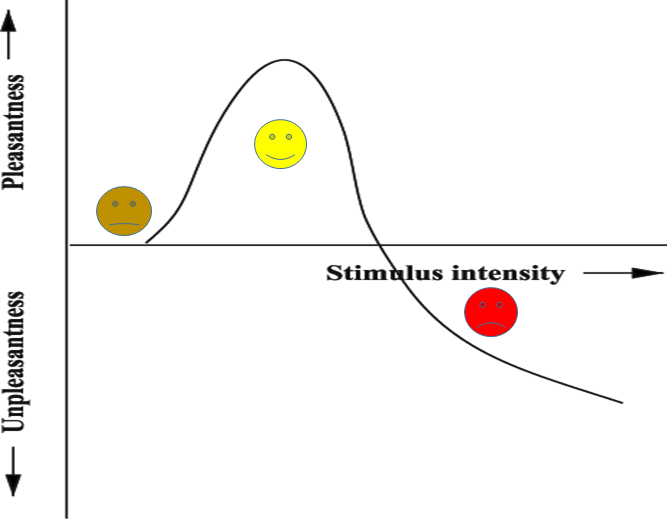
[그림1] Wundt curve
이게 무슨 의미인지에 대해 위에 표를 통해 설명을 드리자면, 먼저 해당 표는 Wundt curve라고 하는 곡선입니다. x축은 Stimulus intensity로 어떠한 행위를 했을 때 사람이 느끼는 자극을 뜻하며 해당 자극의 예시로는 다음과 같이 존재합니다.
- Novelty
- Surprisingness
- Complexity
- Ambiguity
- Puzzlingness
y축은 사람이 어떠한 행위를 했을 때 얻는 즐거움이라고 보시면 될 것 같습니다. 그래서 해당 커브에 대하여 예를 들어보자면 우리가 어떤 퀴즈를 푼다고 해봅시다.
해당 퀴즈가 너무 쉽다면 푸는 사람 입장에서는 별다른 감흥을 느끼지 못할 것입니다.(갈색 스마일 영역)
그리고 문제의 난이도(Complexity)가 적절한 수준으로 올라간다면, 문제에 대한 호기심과 그 문제를 풀었을 때의 만족감을 느낄 수 있을 것입니다.
하지만 문제가 난이도가 너무 어려워지는 바람에 문제를 풀 수 없을 지경까지 되어버린다면, 결국 문제를 푸는 사람은 해당 퀴즈에 대해 부정적인 감정을 가지게 되겠죠.(문제가 xx해서 화가 나는 등?)
이러한 Wundt curve의 특성을 예술작품에도 충분히 적용할 수 있습니다. 어떠한 예술 작품에 대해서 참신함이 많이 떨어진다면, 해당 작품을 감상하는 사람들은 별 감흥을 느끼지 못할 것 입니다.
반대로 작품이 일정수준의 창의성과 참신함을 가진다면, 그 작품을 감상하는 사람들은 좋은 감정을 느낄 수 있겠죠. 하지만 이러한 창의성과 참신함을 과하게 발휘하게 되면, 오히려 보는 사람 입장에서는 긍정적인 감정보다는 부정적인 감정을 가질 수 있다는 것 입니다.
논문에서는 GAN이 어떠한 창의적인 에술 작품을 만들어낼 때 위에서 말한 것처럼 사람들 좋아할 수 있는, 적절한 창의성과 참신함을 고려하지 못한 채 최대한 창의적이게끔만 만들려고한다는 것이 문제점이라고 말합니다.

[그림2] GAN을 통해 생성한 명화[좌측]와 원본 명화[우측]. 객관적으로 보기에 그림이 많이 부담스러워 보인다.
예술 작품을 생성하기 위한 GAN 학습 데이터 셋으로는 WikiArt Dataset(2015)를 사용합니다. 해당 데이터 셋은, 미술작품을 모아놓은 데이터 셋으로, 각 영상마다 style label(바로크, Pop-Art 등등)이 제공됩니다.
GAN: Emulative and not Creative
논문의 저자는 GAN이 모방을 잘하는 것이지, Creative하지는 못한다고 말합니다. gan의 목적은 training data에 대한 distribution을 잘 배우려고 하는 것이기에, 어떠한 미지의(새로운) 무언가를 만들고자 하기에는 무리가 있습니다.
그렇다면 어떻게 해야 GAN을 좀 더 Creative하게 만들 수 있을까요?
해당 논문에서는 기존 GAN의 Loss function에서 새로운 loss 항목을 추가합니다.
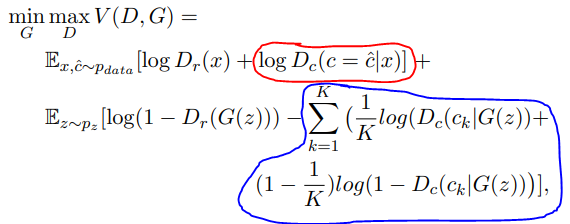
[그림3]CAN Loss function
위에 그림을 보면 박스가 포함되지 않은 곳은 기존 GAN loss를 나타내고, 빨간색 박스가 style classification loss, 파란색 박스가 style ambiguity loss를 나타내는 요소입니다.
수식을 보시면 기존의 GAN과 달리, 두 개의 Discriminator loss가 존재를 하는데, 먼저 기존 GAN과 동일하게 영상의 fake와 real을 구분하는 D_{r} 와, CAN에서 새로 추가된, art의 style을 구분하는 D_{c} 가 있습니다.
그렇다면 D_{c} 의 역할은 무엇일까요? 원리는 정말 간단합니다. Generator는 학습 데이터를 모방하여 새로운 영상(그렇지만 기존 Art style을 모방한 영상)을 만들게 됩니다.
그러면 D_{c} 는 그 영상을 보고, 해당 영상이 기존 예술계에 존재하는 style들(바로크, Pop art, realism, Cubism 등등) 중 하나로 영상의 Label을 판단하게 되고 영상을 Fake 처리해버립니다.
그러므로 Generator는 기존의 Art style과는 다른 방식으로 영상을 생성하는 방향을 가지며 학습하게 됩니다. 이를 통해 기존의 Art style과는 다른 보다 창의적인 예술 작품을 만들어낼 수 있다고 기대합니다.

[그림4]CAN 모델에 대한 학습과정
학습 방법도 일반적인 GAN과 매우 유사한데, 기존에서 추가된 부분은 step6과 step8f로 영상의 진위여부 뿐만 아니라 해당 영상에 대한 label(art stype)도 구분하는 과정이 추가된 것을 보실 수 있습니다.
아무래도 해당 주제가 예술을 접목하다 보니, 결과 분석이 상당히 난해하고 아리송한게 많았습니다. 논문의 저자 역시 실험의 결과를 최대한 논리적으로 설명하려고 많은 노력을 한 듯 보이지만 이해하기가 상당히 난해해서…
글의 마무리를 어떻게 지을지 몰라 이러한 방식으로 학습된 CAN을 통해 생성된 결과 영상을 보여주고 리뷰를 마무리 하도록 하겠습니다.

본문 내용의 표현을 보니 GAN 응용을 여러번 리뷰하신 모양이네요? 그럼 GAN 씨리즈를 한전 리뷰해쥬시죠. 요청합니다.
http://jaejunyoo.blogspot.com/2017/04/pr12-1-video-slides-gan.html?m=1
참고하세요
학습을 시킬 때 pair를 주고 학습하나요?
GAN이 새로운 것을 배우는 것 보단 모방을 하는 것이라는 분석과 새로운 것을 창조하기 위해 D_c를 제안한 내용은 흥미로웠습니다. 그렇다면 D_c는 기존의 것을 구분하는 방법이 궁금해지는데 추가적인 설명 부탁합니다.