논문: https://arxiv.org/pdf/1909.11065.pdf
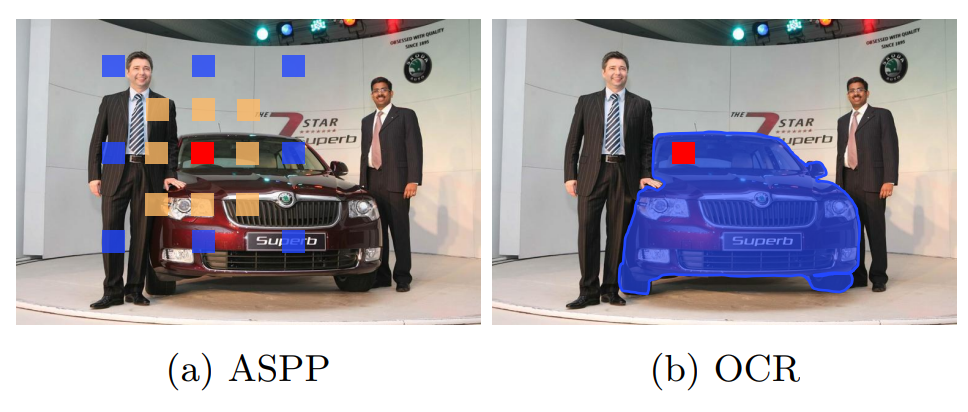
Object-Contextual Representations for Semantic Segmentation (이하 OCRNet)은 context schemes와 관련된 흐름의 연구이다. 이전에 리뷰했던 논문은 multi-scale context로 성능을 높였다면(PSPNet, DeepLab) 이 논문은 relational context를 이용하여 성능을 높였다. 이 둘을 비교하기에 적절한 그림은 아래 그림1과 같다.
Architecture
Backbone:
dilated ResNet-101[1] 또는 HRNetW48 [2]의 일부를 backbone으로 사용하였다. 이러한 network의 도움을 받아 pixel을 course한 object regions으로 나눈다. 이후에 이러한 region을 통합하여 객체의 표현을 확대한다.
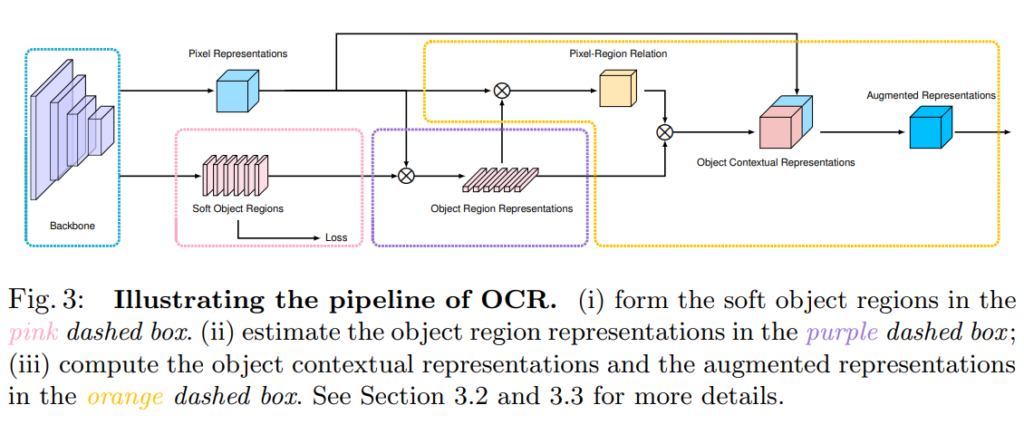
OCR module:
OCR module은 위의 Fig3 과 같고, soft object region을 구하는 분홍색 박스 영역과, final segmentation영역에는 linear function with pixel-wise cross-entropy loss를 이용하였고 나머지 영역은 논문의 3절에 설명된 공식들을 구현하였다.
실험
표1과 2의 실험에서는 dilated ResNet-101을 backbone으로 사용하였다.


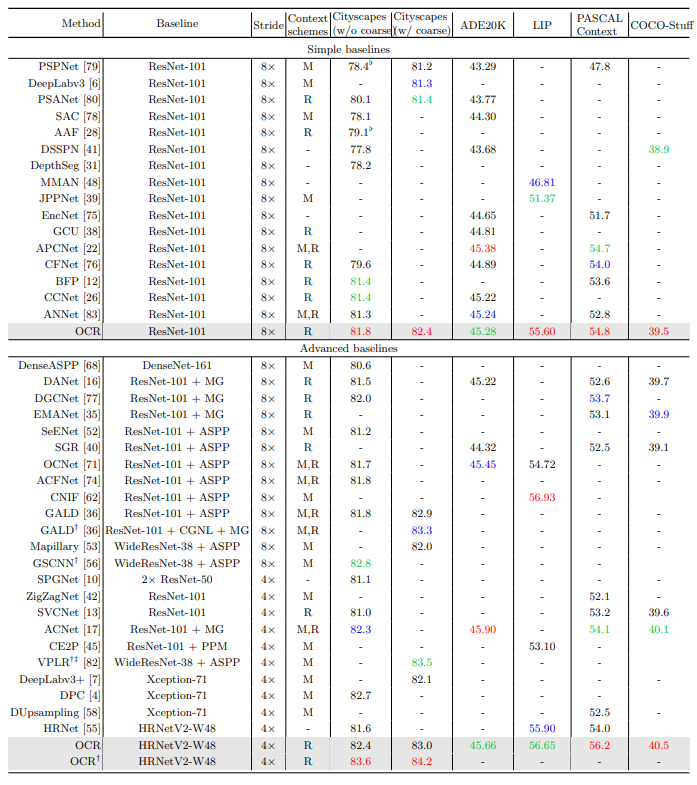
참조
[1] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
[2] Sun, K., Zhao, Y., Jiang, B., Cheng, T., Xiao, B., Liu, D., Mu, Y., Wang, X., Liu, W., Wang, J.: High-resolution representations for labeling pixels and regions. arXiv:1904.04514 (2019)
relational context 빙법론들간의 컨셉적인 차이를 설명부탁드립니다.