
1 Abstract
- Text정보 Descriptor로 활용해 Place Recognition을 하는 첫번째 방법론, Text정보는 환경이 바뀌더라도 똑같은 정보를 갖는다.
- Metric localization을 제시함
- Visual localization 방법론으로 방법론의 타당성을 증명한다.
2.Method
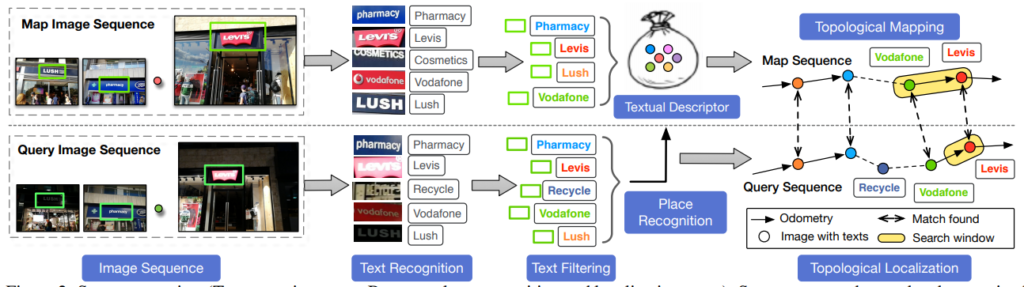
TextPlace의 Pipe line은 그림 2와 같이 크게 두가지로 나눌 수 있다.
- Mapping stage: Sequence한 영상들과 Visual odometry 정보를 토대로, Text정보의 Topological Metric map을 구축한다.
- Place Recognition: Sequence한 Query 영상들 또는 새로 운 카메라는 Text정보와 글들의 일관성있는 환경정보를 바탕으로 Topological Map 에서 localize된다.
2.1 Textual Descriptor
영상에서 Text 정보를 추출하는 방식으로는 TextBoxes++[1]라는 방식을 사용하였다.
2.1.1 Text Filtering
Text정보중에서도 “이것”과 “그것”같은 정보보다는 “GUCCI”같은 상호명이 더욱 중요하므로, 미리 중요한 단어들을 정의하여 불필요한 정보를 필터링할 필요가 있다. 또한 영상의 퀄리티와 잘 사용되지않는 글씨체등의 이유로 Text정보가 Noise가 될수가 있다 따라서 이러한 것들또한 필터링이 필요하다. 따라서 필터링으로 Levenshtein distance을 이용해서 미리 정의한 사전과 비교해 필터링을 진행한다.
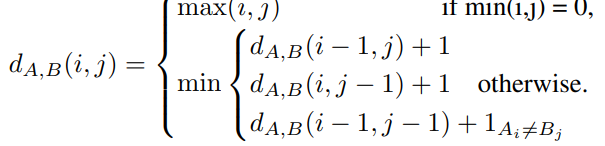
Levenshtein distance은 두단어의 유사도를 측정하는 식으로 식 1과 같다.
필터링 후 영상 마다 Text정보가 남을 것이고 이것이 영상의 Textual Descriptor가 된다.
2.2 Topological Mapping
각 노드는 Text descriptor와 Camerapose를 포함하고 있으며, Node 사이의 Edge는 Camera pose estimation을 위해서 , 상대적인 변환 방식을 뜻한다.
Topological Map은 텍스트의 공간적 일관성을 모델링하며 장소 인식을 위해 그래프에서 텍스트 설명자의 뚜렷한 조합을 형성한다
2.3. Place Recognition
Topological Map 이 구축 되면 Query 이미지데 대해 Place recognition과 Topological localization이 가능해진다.
Query영상에 대해 Text detection과 Text filter을 DB구축 때처럼 진행한다. 그 후 text 정보를 활용해서 DB와 QR를 비교해 Place recognition이 진행 된다.
2.3.1 Spatial-temporal Dependence
Text정보는 대체적으로 공간적인 상관관계르 갖는다. 따라서 TextPlace에서는 Search Window를 이용해서 Similarity에 제한을 준다. 이것은 Large-scale Dataset에서 효율적인 속도와 Robust한 결과를 보여준다.
2.3.2 Similarity Matching
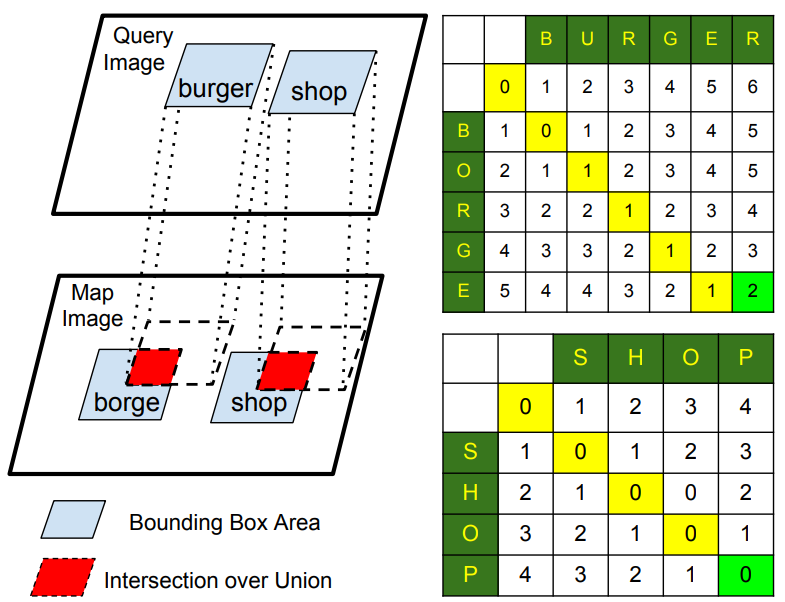
DB와 Query의 Text정보의 Similarity 를 계산하는데 두가지를이용한다.
- Levenshtein distance
- IOU
첫번쨰는 Text간의 유사도 이고, 두번쨰는 Text Box간의 유사도이다. 첫번쨰 를 통해서 Text가 맞는 지 파악하는 것이고 두번째는 Text의 위치를 통해 Camera가 얼마나 다른 곳에서 촬영된것인지 파악한다.
2.4 Topological Localization
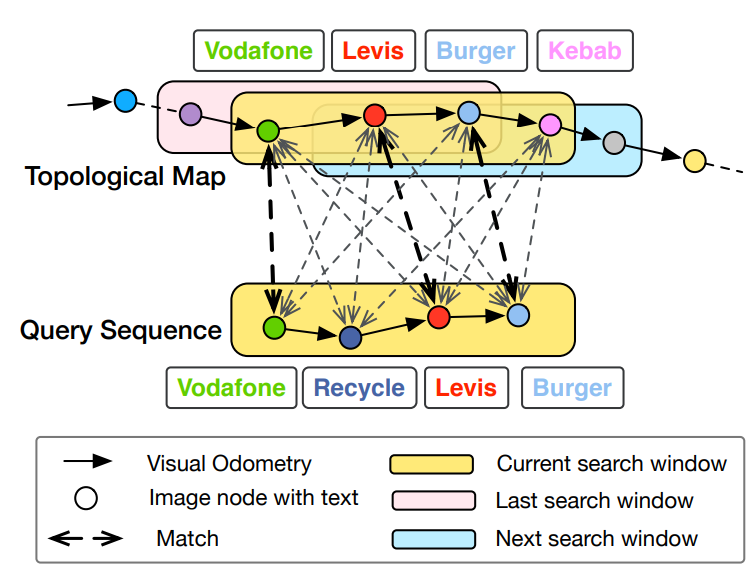
전체 DB를 활용해 QR의 Pose를 예측하는 순서는 다음과 같다.
- Searching을 위한 Window를 Sequence한 Query의 유사도가 가장 큰 것으로 한다.
- Visual Odometry를 이용해 유사한 노드를 찾는다.
- 없을경우 Window를 옮겨가며 Searching을 계속한다.
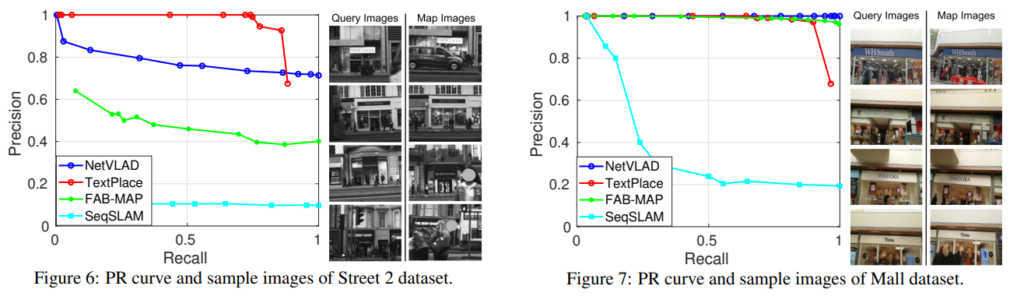
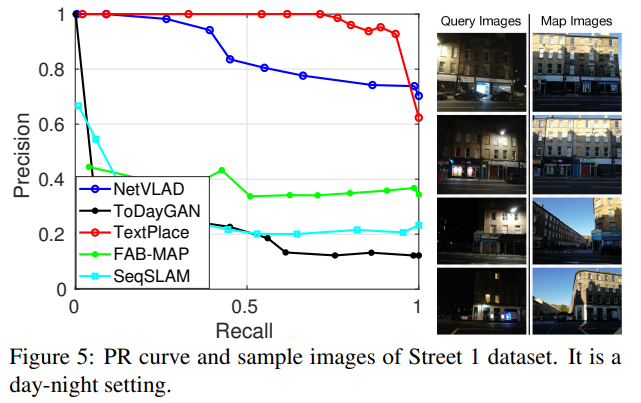
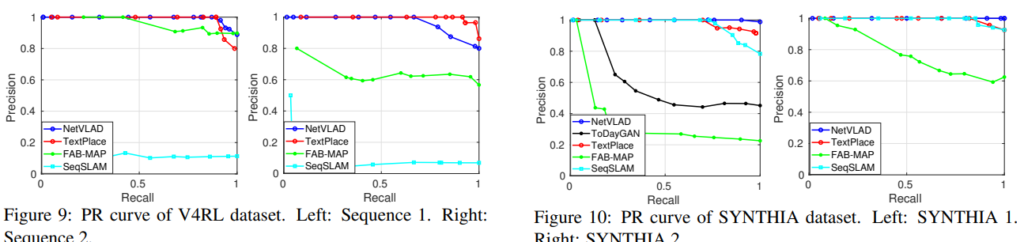
다양한 Datatset에서 좋은 성능을 보이는 것을 확인할 수 있다 . 환경이 많이 변하는 Dataset에서도 좋은 성능을 보이고있다.
해당 방법론이 빌딩에 수없이 많고 비슷한 간판이 있는 우리나라 환경에서도 적합할까요
Text를 활용한 방식인데 간판이 아닌 광고들처럼 수시로 text가 바꾸는 물체들에 대한 대처도 있나요?
@지원, 비슷한 긴판이라는 것이 비슷한 상호명을 뜻하나요? 아니면 단순하게 간판 디자인을 의미하나요?
@태주, 따라서 주기적인 Map의 업데이트가 필요합니다. 모빌아이의 REM 이라는 방식이 클라우드 방식으로 맵을 만들고 업데이트 하는 방식의 예시이구요. 즉, 지도는 한번 만들고 만게 아니라 지속적인 업데이트가 중요하지요. 따라서 이 업데이트를 어떻게 효율적으로 운용할 것인가가 지도회사의 미래와 관련이 있습니다. 즉, text를 이용하는 위치인식에거 뿐만 아니라 비전기반 위치인식 연구자들 모두가 고민해야할 질문입니다.
위에 클라우드 => 크라우드… 오타입니다
리트리버를 text정보로만 진행하나요? 아니면 이미지다른 descriptor도 사용하나요?