

Action classification 분야에서는 이전에 주로 UCF101, HMDB51와 같은 작은 규모의 데이터 셋을 사용하곤 했습니다. 그런데 다른 task에서 마찬가지로 학습을 시킬 때 충분히 큰 규모의 데이터셋으로 학습시킨다면 성능을 향상시킬 수 있을 것 입니다. 이러한 이유로 인해 본 논문의 저자는 400개 이상의 human action class를 400개 이상의 영상으로 지니고 있는 Kinetics 데이터 셋을 공개하였습니다. 그리고 SOTA network인 I3D를 제안하였으며 이를 Kinetics 데이터 셋으로 전이 학습시켜 다른 데이터 셋에서도 SOTA의 성능을 얻었습니다.
1. Action classification architecture
본 논문에서는 이전까지 action classification 분야의 문제를 해결하기 위해 사용했던 network를 소개하고 제안한 I3D network에 대해 설명합니다. 이전에 사용했던 network 중에서는 현재에도 활발히 연구되는 network도 있으나 이 논문 기준으로 이전 논문이기에 Old 라고 표기하며 설명하고 있습니다.
1.1 The Old I: ConvNet+LSTM
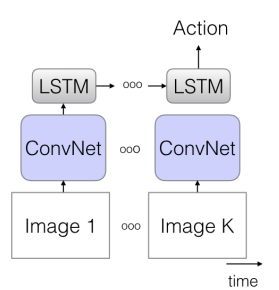
기존 image classification 분야에서 좋은 성능을 내고 있는 2D convolution에 시계열 데이터를 다루는 데 널리 쓰이는 LSTM을 결합한 network 입니다. 2D convolution 에서 feature volume 들을 추출한 뒤 LSTM으로 매 스텝의 정보를 학습하여 action classification 문제를 푸는 방식인데 해당 논문에서는 입력으로 25 fps의 영상을 5 frame에 한장 씩, 사실상 5 fps의 영상으로 만들어 사용해 성능 비교를 하였습니다.
1.2 The Old II: 3D ConvNets
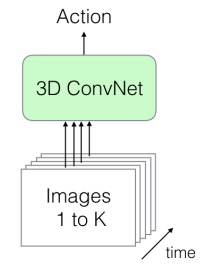
2D convolution 에서 spatial한 filter만을 사용했다면 3D convolution에서는 spatio-temporal한 filter를 사용합니다. 주로 C3D라고 불리우는 3D convolution를 8개의 convolution layer와 5개의 pooling layer, 2개의 fully connected layer로 구성한 뒤, 112×112 pixel의 16-frame의 clip 을 입력으로 넣어 성능 비교를 하였습니다.
1.3 The Old III: Two-Stream Networks
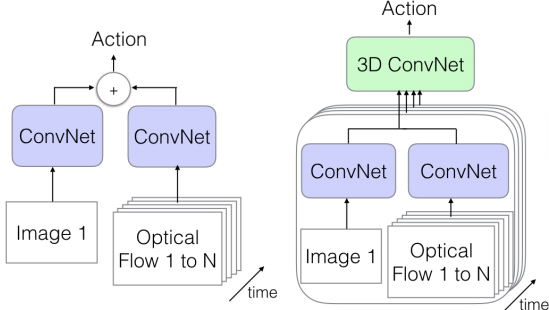
RGB 영상과 Optical Flow로 2D convolution 시켜 사용하는 방식입니다. Optical Flow는 기존 영상처리 분야에서 움직이는 객체의 방향을 추적할 때 사용하는 방식으로 frame 간의 변화하는 점을 pixel 단위로 추적하는 방식입니다. 성능을 비교하기 위해 RGB 영상과 10frame을 누적 시킨 Optical Flow를 사용하였습니다. 그리고 이 구조에서 나온 feature volume을 다시 누적시켜 3D convolution 한 network도 성능 비교를 위해 사용하였습니다.
1.4 The New: Two-Stream Inflated 3D ConvNets (I3D)
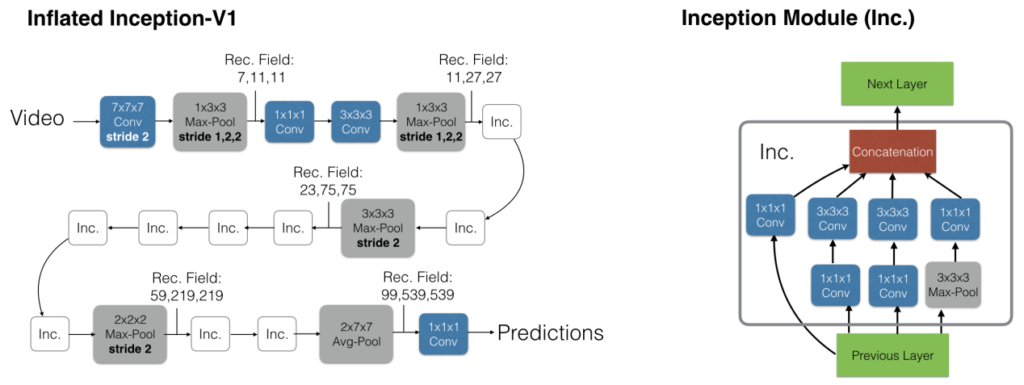
- Inflating 2D ConvNets into 3D
새로운 3D network를 만든 것이 아닌, 기존의 image classification에서의 성능이 뛰어난 network의 NxN filter를 단순히 NxNxN의 차원으로 늘려 3D convolution의 filter 로 사용하였다고 합니다.
- Bootstrapping 3D filters from 2D filters
그리고 저자는 널리 쓰이던 ImageNet의 pretrained weight를 어떻게든 사용하고 싶었기 때문에 Inception-v1 기반으로 ImageNet에 pretrain된 NxN의 filter를 시간 축으로(비디오가 입력으로 들어가니까) 반복적으로 N번 늘리고 각 값을 N으로 나눠 NxNxN 크기의 filter를 사용하는 Inflated Inception-V1을 구성하였습니다. 이렇게 되면 실질적으로 convolution 연산을 할 때 결과를 내는 부분이 같다고 합니다.
- Pacing receptive field frowth in space, time and network depth
Filter의 차원이 늘어난만큼 각 축으로의 stride를 설정하는 것도 중요한 문제가 됩니다. 주로 2D convolution이나 pooling 에서는 영상의 width 축과 height 축에 대해 같은 stride를 주며 대칭형으로 사용하게되고 이는 network가 깊어질수록 width 축의 방향이든 height 축의 방향이든 공간적으로 멀리 떨어져 있는 pixel은 똑같이 영향을 받는다는 것을 의미합니다. 그러나 이것은 시간 축을 고려하게 되면 최적의 방식이 아니게 됩니다. 예를 들어 공간 축에 비해 시간 축이 너무 빨리 증가하면, 즉 시간 축의 stride가 훨씬 크게 되면 공간적인 정보를 제대로 파악하지 못하게 되고 시간 축에 비해 공간 축이 너무 빨리 증가하면, 즉 공간 축의 stride가 훨씬 크게 되면 정지 영상과 다를게 없기에 행동을 잘 인식하지 못하게 됩니다. 이러한 문제를 고려하여 경험적으로 Inception-v1의 첫번째와 두번째 maxpooling layer의 시간 축에 대한 stride가 1일 때 더 좋다는 것을 찾아 이와 같이 구성하게 되었다고 합니다.
- Two 3D Streams
제안된 I3D network는 RGB 만으로도 어느정도 성능이 나오고, 결국엔 RGB 만으로 motion feature를 학습할 수 있어야하지만, 아직은 Optical Flow를 같이 사용했을 때 움직이는 객체를 반복적으로 최적화 할 수 있어 더 좋은 성능을 보였기에 같이 사용했다고 합니다. Inference 시엔 두 network에서 나온 출력 값을 평균내어 사용하게 됩니다.
2. Experiments

Table 1 은 앞서 설명한 network들의 파라미터 수와 사용한 비디오의 시간 길이 입니다. SOTA를 달성한 I3D는 높은 정확도에 비해 파라미터 수가 적은 것을 확인할 수 있습니다.

Table 2 는 제안된 Kinetics 데이터 셋과 기존에 action classification에서 사용하던 데이터 셋에서의 network들 간의 성능 차이 입니다. 처음에 소개 드렸던 대로 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
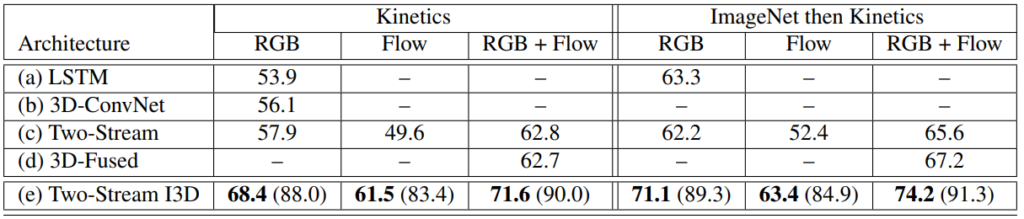
Table 3 은 앞서 설명드린 방법으로 ImageNet pretrained 파라미터를 사용했을 때와 사용하지 않았을 때의 Kinetics 데이터셋에서의 성능 차이 입니다. 입력을 어떻게 넣든, 어떤 network든 ImageNet pretrained 파라미터를 사용한 것이 더 좋은 성능을 낸 것을 확인할 수 있습니다.
kinetics 데이터셋의 길이는 대략 얼마나 되죠? CDVA 로 Keyframe selection 을 시도한다고 했을 때 Ucf101 보다 여럿 자1히려나요?
한 video 당 10초정도로 UCF101보단 길기 때문에 keyframe selection을 했을 때 좀 더 많은 프레임이 잡힐 듯 합니다
Action classification 분야도 있다는걸 처음 알았습니다. 오브젝트 디텍션이나 Classification을 위해 쓰이는 대표적인 데이터셋 image net, coco, caltech 들 처럼 action classification에도 대표적인 데이터셋이 있나요? 그것의 Class는 무엇이 있는지(어떤 action들을 구분하는지) 궁금합니다
action classification 분야에서는 주로 UCF101, HMDB-51, 그리고 이 논문에서 제안된 Kinetics 와 같은 데이터 셋을 사용합니다.
class로는 UCF101 기준 아래 처럼 나뉩니다.
1 ApplyEyeMakeup
2 ApplyLipstick
3 Archery
4 BabyCrawling
5 BalanceBeam
6 BandMarching
7 BaseballPitch
8 Basketball
9 BasketballDunk
10 BenchPress
11 Biking
12 Billiards
… … …
95 Typing
96 UnevenBars
97 VolleyballSpiking
98 WalkingWithDog
99 WallPushups
100 WritingOnBoard
101 YoYo