서울대학교에서 진행한 AI여름학교 모든 발표를 듣고 정리하는것을 목표로 하였으나, 네이버랩스 챌린지 발표등의 이유로 모든 강연을 듣지 못하였습니다. 그래서 가장 인상깊었던 강연들 위주로 작성하고자 합니다.
1일차

1일차에서 가장 인상깊었던 강의는 위에 형광펜으로 표기한 강연이다. 각 내용에 대한 전반적인 내용을 리뷰하고자 합니다. 발표자료를 얻을 수 없기 때문에 제가 들었던 내용을 제 방식대로 정리했습니다.
1-1. A Computational Approach to Sensing, Measuring, and Modeling Humans in 3D

2020CVPR 에서 Oral Paper로 선정된 ‘ PIFuHD: Multi-Level Pixel-Aligned Implicit Function for High-Resolution 3D Human Digitization ‘ 논문의 저자인 주한별님은 FAIR에서 근무하고 계신다고 한다. 주한별님은 이번 발표에서 3D 모델링을 위해서 어떻게 데이터셋을 구축하고 또 3D 모델링하는 연구들이 어떻게 발전됐는지 설명해주셨다.
위의 영상은 실제 3D 모델링을 위한 2D 이미지, 3D 키네틱 센서 등을 수집하기 위한 돔 형태의 스튜디오다. 스튜디오 안에서는 전방향으로 Object에 대한 2D 이미지 데이터와 3D 키네틱 데이터를 수집할 수 있고, 이는 딥러닝기반 3D 모델링 연구를 위한 데이터셋 된다. 박사과정 해당 스튜디오를 만들고 스튜디오에서 데이터를 수집하는 과정을 소개하면서 Peta 단위의 방대한 데이터처리하는데 있던 어려움들을 발표에서 이야기하셨다.
이후 딥러닝으로 사람을 3D 모델링하는 논문들에 대해서도 발표하셨는데, 위 스튜디오를 통해 데이터셋을 구축했기 때문에 딥러닝 모델 학습이 가능했었다. 주한별님이 발표하신 논문들은 아래 영상에 나타난다.
각 논문들에 대한 내용들 그리고 실질적으로 위의 데모 영상들을 설명해주셨는데, 자세한 내용은 따로 논문을 통해서 확인할 수 있다. 해당 강의의 컨셉은 ‘3D 모델링을 위해서 주한별님이 박사과정때 구축한 스튜디오에 관한 설명과 그러한 데이터셋을 가지고 연구를 수행한 전반적인 내용이다’
주한별님은 다음과 같은 발표 Open Problem을 남기고 강의를 마무리하셨다.

주한별 : https://jhugestar.github.io/
1-2. Learning and Optimization Methods for Legged Robots
하세훈님은 2019년 조지아텍 교수로 임용된 분이시다. 하세훈님의 연구는 다리가 달린 로봇에 대한 연구이며, 발표에서는 RL에 대한 내용이 주를 이루었다.
인상깊었던 점은 로보틱스에서 RL이 활발히 사용되며 RL을 통해서 4족 로봇이 다양한 바닥 환경(메모리폼, 평지, 카펫(?) 등등)에서 RL을 통해서 로봇이 스스로 어떻게 하면 잘 걸을 수 있는지 학습하는 것에 대해서 발표하셨다.
https://sites.google.com/view/minitaur-locomotion/
해당 사이트에 잘 나타나 있으며 영상을 몇개 첨부하자면,
실제 저 로봇이 RL을 통해서 스스로 걷는 방법을 학습한 결과이다. 정확히 모든 내용을 알지 못했지만, 그래도 로보틱스 분야에서 RL 연구가 활발히 이뤄지고 있으며 RL의 중요성도 높아지고 있음을 확인할 수 있었다. (RL공부를 시작해야겠다)
1-3. AL for the Real World
카이스트 황성주교수님의 발표로 이 연구실은 실제 딥러닝으로 개발한 모델들을 Real 환경에서 작동하도록 하는 연구를 수행하신다. 우리 연구실과 비슷하다는 느낌을 많이 받았다.
Real World를 위해서 딥러닝이 해결야할 문제들을 3가지를 정의하셨고 이와 관련해 연구를 수행하신다고 하셨다. 그 중 기억나는 2가지는 1. Safe AI 2. Efficient inference 이다.
Safe AI에 대해서 이야기하자면 모델이 사람을 찾을때 사람일 확률을 0.7이라고 예측했으면, 실제 이 0.7가 실제 0.7라는 것을 의미하는 것인지에 대한 문제 등이 있다.
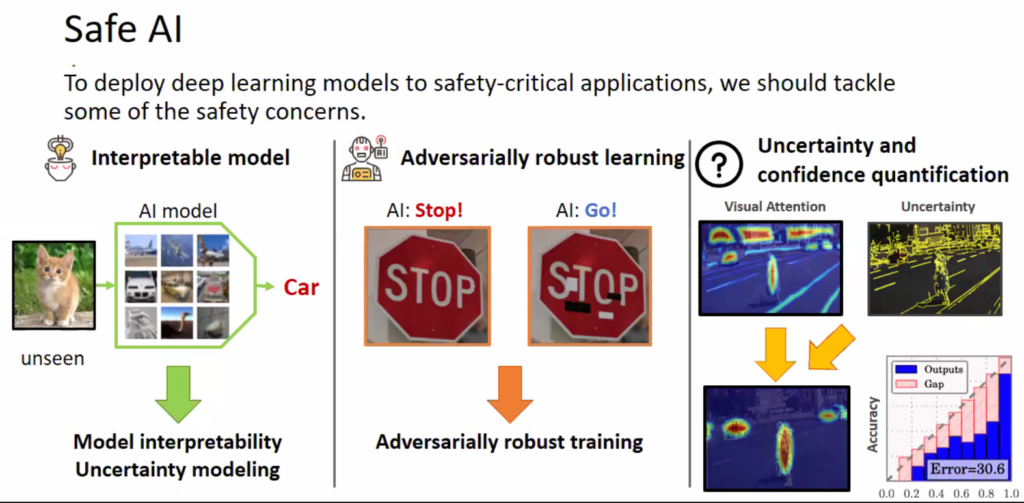
두번 째로는 Efficient Inference 인데, 이는 실제 딥러닝 모델들이 무겁기 때문에 속도도 느리고 많은 메모리를 차지하는 점을 해결해야하는 이슈이다. 이를 위해서 해당 연구실에서 제안한 것이 흥미로웠는데 내용은 다음과 같다.
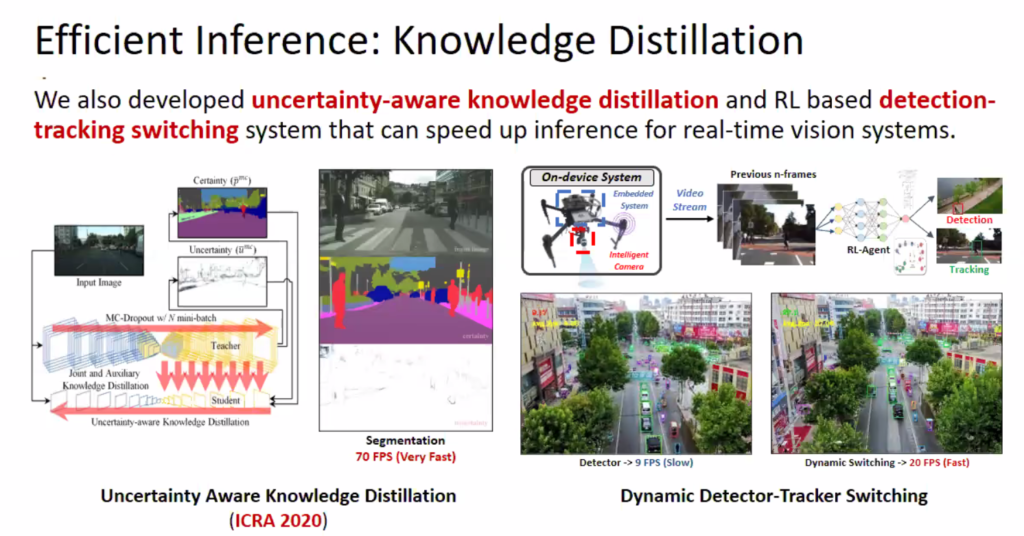
기존 Object Detection을 수행할때 속도가 많이 느린 점이 있는데 이를 Tracking 과 합쳐서 속도를 향상시킬 수 있다는 내용이다. Object Detection은 매 프레임마다 Detection을 수행해야 하기 때문에 JetsonTX에서는 1FPS의 성능밖에 나오지 않는다고 이야기하시면서(? 1FPS밖에 안나온다니..) Tracking은 실제 기존 object의 이동정도만 계산하면 되기 때문에 훨씬 더 빠른 inference가 가능하고 이를 Object Detection과 결합해 사용하면 실시간으로 빠른 detection이 가능하다고 하셨다. 그리고 Object Detection과 Tracking을 수행하는데 있어서 어떤 프레임에서 Object Detection을 수행하고 어떤 프레임에서 Tracking을 수행해야할지 판단해야하는데, 이는 RL을 통해서 결정한다고 한다. 자세한 내용은 X리뷰를 이용해 진행할 예정이다.
2일차

2일차에서 가장 인상깊었던 강의는 위에 형광펜으로 표기한 강연이다. 각 내용에 대한 전반적인 내용을 리뷰하고자 합니다. 발표자료를 얻을 수 없기 때문에 제가 들었던 내용을 제 방식대로 정리했습니다.
2-1. Task-free continual learning
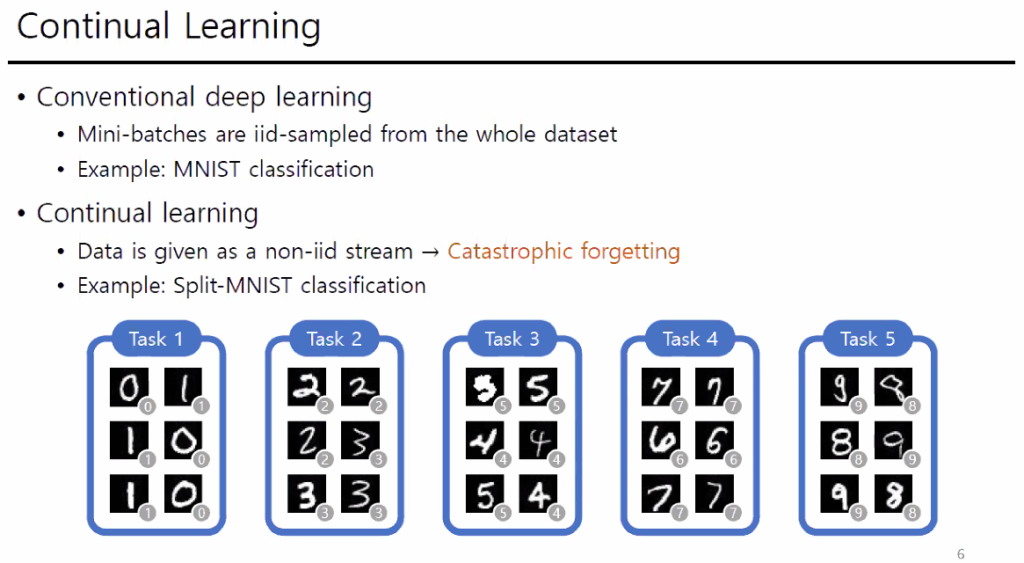
Continual learning은 실시간으로 모델이 학습하면서 inference를 하는 온라인 학습과 같은 의미이다. 이러한 Task에서 가장 해결해야할 문제는 ‘Catastrophic forgetting’을 해결하는 것이다. Catastrophic forgetting은 이전에 기 학습된 모델이 새로운 class를 학습하면 이전에 학습된 부분을 업데이트하여서 이전 학습된 클래스에 대한 성능이 떨어지고 새로 학습되는 클래스에 대해서 성능이 높아지는 것을 의미한다.
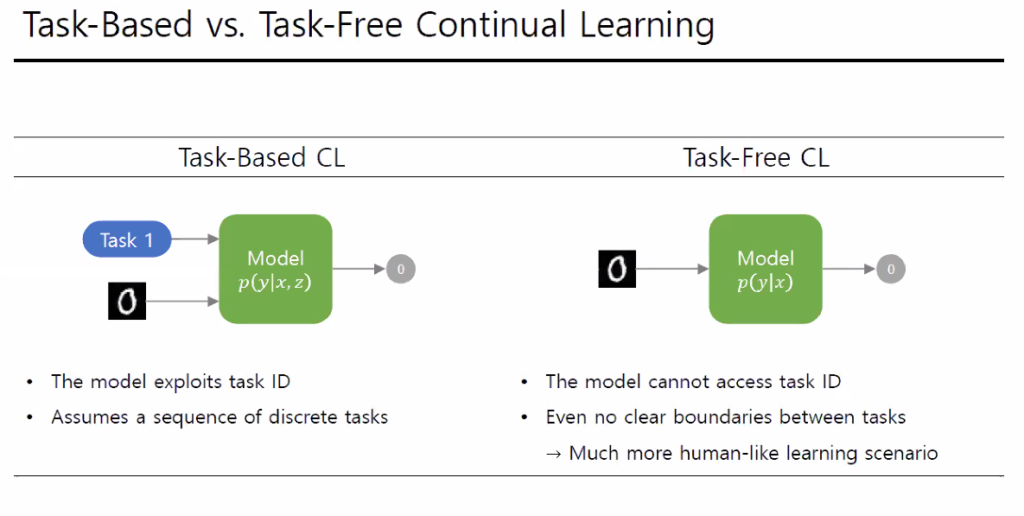
그래서 Continual Learning연구자들은 해당 문제를 해결하기 위해서 크게 Task free 와 Task base 방식으로 모델을 학습한다고 한다. 여기서 Task Base란 학습 또는 테스트에서 Task Id가 주어지는경우, Task Free란 Task Id가 주어지지 않는 경우를 의미한다.
그리고 연구의 방향은 다음과 같다.
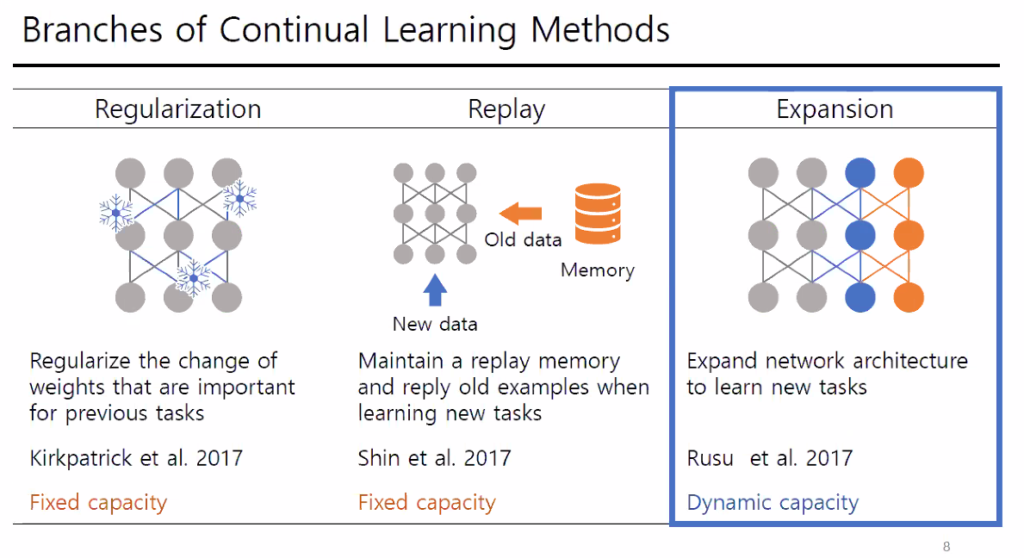
실제 바로 산업에 적용할때는 Replay 방식의 성능이 앞도적이기 때문에 해당 방법을 사용하고 발표에서도 Continual Learning에서 당장 성능을 높이려면 replay 방식을 사용하라고 하셨다. Replay 방식은 이전에 학습한 클래스까지 모두 합쳐서 학습을 진행하는 방법이다. 이러한 방법들은 Fixed capacity 방법으로 모델의 용량은 변하지 않는다. 하지만 Expansion 방법은 새로운 클래스가 추가될때 모델의 레이어를 계속적으로 추가하는 방법을 의미한다. 해당 연구실은 이 Expansion 방법으로 연구를 수행하고 있으며 연구내용은 다음과 같다.
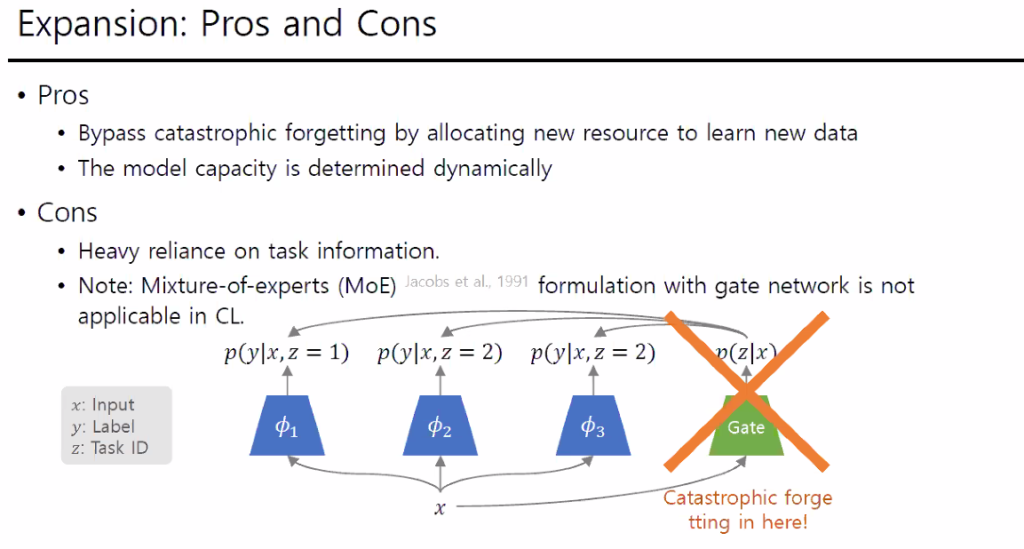
기억이 나는 부분만 설명하자면, 해당 방법은 Task base 방법으로 새로운 클래스가 속한 Task Id를 구하고(z값) 해당 Task Id의 모델로 결과를 예측하는 것이라고 한다.
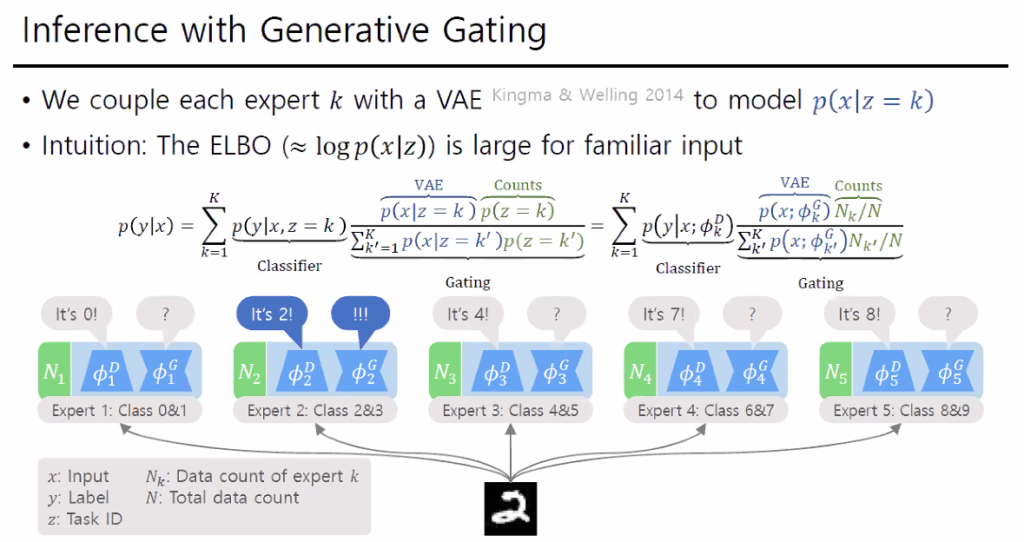
다만 이때도 Task ID를 결정하는 Gate에도 Catastrophic forgetting이 발생하기때문에 이를 해결하기 위해서 모든 Task에 Generater를 만들어서 문제를 해결했다고 설명하셨다.
사실 해당 부분은 잘 모르지만 Catastrophic forgetting은 단순히 Continual Learning에만 발생하는 문제는 아니기 때문에 관심있게 지켜보면서 다른 부분에서 어떻게 응용할 수 있을지 고민해봐야겠다고 생각했다.
2.2 Computer System Optimizationi for Autonomous Driving

해당 강연은 영상으로 녹화하였는데 NAS에서 확인이 가능하다.
Z:\RCV_Study
정말 좋은 강연들이 있었고, 정말 훌륭한 연사들이 있는 서울대학교 AI 여름학교 였다. 이런 기회가 흔한 기회는 아닌데 더 집중해서 듣지 못해 후회된다.
1-3 관련 리뷰는 다음주 작성이신가요
언더리뷰 상태가 아니라면 다음주에 리뷰하겠습니다
(1-2 관련 질문입니다)로봇이 가상 환경에서 학습과정을 진행 한 후 로봇이 작동을 하게 되는 것인가요? 맞다면, 바닥 모델링 진행은 어떻게 이루어지나요?
실제 해당 로봇을 특정 바닥에서 RL학습을 진행시키는 것입니다. 가상이 아닌 진짜 환경에서요 영상에 나타난 환경에서 그냥 바로 학습시키는거에요
@황유진, 저렇게 Hardware in the loop 을 통한 피드백 제어를 히곤 합니다.