https://arxiv.org/pdf/1512.02325
Badge 교육에서 공부한 SSD : Single Shot Multibox Detector에 대해 리뷰하겠습니다. 이전에도 이 논문에 대해 리뷰한 적이 있었는데, 이번 공부를 통해 이전에 했던 리뷰는 아무런 것도 아니였다는 것을 느꼈습니다.
SSD의 학습 과정에 따라 리뷰를 진행하겠습니다. 학습 과정은 다음과 같습니다.
1. 이미지 전처리
2. VGG-16기반의 convolution network를 통해 feature map 추출
3. feature map을 통해 default box와 계산 될 class와 location의 predict값 추출
4. predicted score, predicted location 둘을 default box 와 Matching
5. loss 계산 및 back propagation을 통한 학습
6. Evaluate
이미지 전처리 ( Data augmentation )
1. 원본이미지 사용, 2. Sample a patch, 3. Randomly sample a patch
라고 적혀있는데, 이 부분은 잘 이해가 가지 않았습니다.
이렇게 3중 1개의 옵션을 각 이미지에 랜덤하게 적용하고, Conv net에 태웁니다.
이미지는 300×300 혹은 512×512로 resize하여 사용합니다. 이미지 크기에 따라 성능이 달라집니다. 또, 논문에서 expansion 이라고 칭하는 augmentation trick을 제안합니다. zoom out의 효과가 있다고 하고, 3%p 가량의 성능 향상을 보입니다.
Convolution net work
전처리된 이미지를 SSD의 모델에 태워 feature를 뽑고, 이를 통해 class와 category의 예측값을 구합니다.
SSD의 모델은 다음과 같습니다.

VGG-16을 backbone으로 사용합니다. VGG-16의 제일 끝단을 수정합니다. fc6과 fc layer를 convolution layer로 바꾸고, 2 x 2 – s2 의 pool5 layer를 3 x 3 – s1으로 바꾸어줍니다. 그리고 a`trous algorithm을 적용했습니다. (Conv7은 1×1이기 때문에, Conv6에만 적용됩니다.) 또한, 모든 dropout layer와 fc8 layer를 제거했습니다.
수정된 VGG-16 레이어 이후 Extra Feature Layers가 붙습니다. Conv의 구성은 위의 그림과 같습니다. stride의 기본값은 1, padding은 0입니다. stride가 언급된 layer에서는 이전과 다음 feature map의 size에 따라 계산하면 됩니다.
이때 Conv4_3 layer는 다른 layers와 비교할때, different feature scale을 갖기 때문에, L2 normalization technique를 통해 rescale 해줍니다. 이때 초기 20의 값으로 rescale 해주고, 이후 back propagation을 통해 이 값을 학습합니다.
Predict
SSD 모델의 Conv4_3, Conv7, Conv8_2, Conv9_2, Conv10_2, Conv11_2 layer 6개 layer의 각각의 feature map에서 default box와 계산될 predict 값을 추출합니다.
default box는 미리 정해놓은 scale과 aspect ratio로 각 feature map의 크기에 맞도록 만들어 놓은 box입니다. 모델이 예측하는 값은 바로 이 default box가 얼마만큼 움직인 곳에 물체가 있는지에 대한 정보입니다. default box가 곧 object의 위치를 나타낸다고 보면 되고, 거의 모든 영역을 아우를 수 있습니다.
default box는 [cx cy w h] 의 값을 갖습니다.
cx cy는 feature map의 각 좌표에 0.5를 더한 값을 feature map의 크기로 나눈 값입니다. 예를 들어 conv4_3의 feature map의 크기는 38 x 38 이기 때문에, 각 좌표를 중심으로 box를 만든다고 보면 됩니다. 상대적인 값을 갖기 때문에, 38로 나누어줍니다.
w와 h는 scale과 aspect ratio에 따라 결정합니다. 둘은 feature map마다 정해져 있습니다.
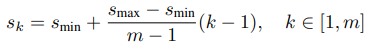
aspect ratio = { 1/1, 1/2, 1/3, 2/1, 3/1 }
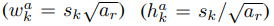
위의 공식들을 통해 w와 h의 값을 구하여 [cx cy w h] 의 box를 만듭니다.
aspect ratio = 1 일때 scale
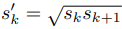
을 하나더 추가해 총 6쌍의 w와 h를 통해 default box를 만들 수 있습니다.
PASCAL VOC2007 dataset 기준, Conv4_3, Conv10_2, Conv11_2는 1/3과 3/1 ratio를 제외한 4개의 ratio, 나머지는 6개의 ratio( 1/1은 2개 취급) 기준의 default box를 만듭니다. 또한 Conv4_3의 scale은 0.1로 설정하고, 이후 5개의 feature map은 s_min 0.2, s_max 0.9로 계산하여 차례로 0.2, 0.375, 0.55, 0.725, 0.9를 scale로 갖게됩니다.
그렇게하면
Conv4_3 = 38 x 38 x 4 = 5776
Conv7 = 19 x 19 x 6 = 2166
Conv8_2 = 10 x 10 x 6 = 600
Conv9_2 = 5 x 5 x 6 = 150
Conv10_2 = 3 x 3 x 4 = 36
Conv11_2 = 1 x 1 x 4 = 4
총 합 8732개의 default box가 만들어 집니다.
다양한 스케일의 feature map과 default box의 크기는 작은 스케일부터 큰 스케일까지 넓은 영역의 물체를 detect 할 수 있도록 해줍니다. 아래 사진은 이렇게 만들어진 default box를 300 x 300의 빈 이미지에 그린 사진입니다.

앞서 언급한 것 처럼 모델은 object가 default box를 얼마만큼 움직인 위치에 있는지를 학습합니다. 이를 학습하기 위해 모델은 8732개의 각 default box에 해당하는 class와 cx cy w h 의 변화량을 예측합니다.
그러면
(class의 수 + background class 1개 ) * 8732의 classification을,
gcx gcy gw gh(각 변화해야하는 수치) 4개 * 8732개의 localization을
예측합니다.
3 x 3 padding=1 stride=1 conv2d layer를 통해 예측합니다.
conv layer에서 변화하는 것은 이미지의 크기가 아니라 차원이므로, output channel을 각 layer의 이미지 좌표가 만드는 default box의 수 (ex conv4_3 = 4) * class의 수 + 1 짜리 1개와, 4짜리 1개 총 2개의 layer를 통해 구합니다.
그후 concatenate하고 view를 바꾸어 (batch, 8732, 4), (batch, 8732, #of classes+1) 를 predict 값으로 return 합니다.
Matching
Loss를 구하기 위해서는 GT인 box의 xmin ymin xmax ymax (혹은 x y w h, cx, cy, w, h)의 값을 모델이 predict할 수 있는 값으로 바꾸어 주어야 합니다. (label은 cross entropy loss를 구할 수 있도록 shape만 맞추어 주면 됩니다.)
우선 GT인 object box와 앞서 생성한 각 default box와의 IoU를 구해 특정 Thresh hold ( = 0.5 )를 넘는 default box의 index를 구합니다.
구한 default box의 index에 해당하는 즉, 8732개의 default box 중 IoU가 0.5가 넘는 default box에 대해서, 다음 공식을 통해 GT box와의 cx cy w h의 변화량을 구합니다.
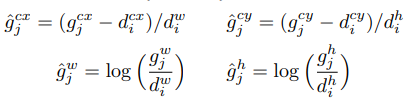
여기서 구한 g^cx, g^cy, g^w, g^h와, model이 예측한 값들 중, 위에서 구한 index에 해당하는 값들과의 차를 Loss로 계산합니다.
Loss
localization에는 smooth L1 loss function을, classification에는 cross entropy loss function을 사용합니다.
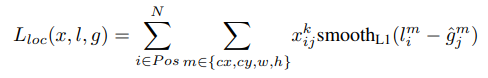
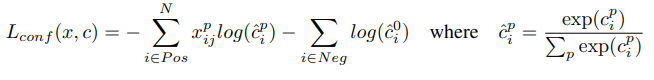
구한 두 loss중 confidence loss( classification loss )에 알파를 곱한 값과 loc loss의 합에서 구한 index의 수 ( positive box ) 즉, 실제 object가 있는( IoU >= 0.5)인 default box의 수로 나눠준 값을 loss로 사용합니다. 여기서 알파 값은 논문에서 교차검증에 의해 1로 설정했다고 합니다.
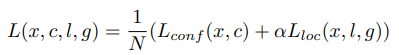
이 때, confidence loss에서 positive box의 수에 일정 비율( 0.3 )을 곱한 수 만큼의 수를 loss에 추가하는데요, 이를 Hard negative mining 이라고 합니다.
Hard negative mining의 방법은 다음과 같습니다.
1. 전체 8732개의 default box에 대한 예측값 중, 위의 conf loss로 사용한 positive box를 0으로 제외시킵니다.
2. 그렇게 되면 실제로 물체가 없는 상자( IoU < 0.5 )를 물체가 있다고 예측한 상자만 남게됩니다.
3. 그렇게 남은 상자를 내림차순으로 정렬합니다. 그렇게 되면 물체가 없는 부분을 있다고 강하게 가정한 loss 배열이 됩니다.
4. index 0부터 위에서 일정비율을 곱한 수 만큼의 loss를 추가로 구합니다.
5. 이를 positive loss와 더한값을 conf loss로 사용합니다.
위에서 구한 값을 loss로 사용하여 학습을 진행합니다.
Evaluation
SSD 모델이 예측하는 값은 8732개의 default box 전체에 대한 변화량 입니다. 따라서 한 이미지에 8732개가 이미지에 그려지게 되는데요,

그러면 이것이 제대로 찾은것인지 알기 어렵습니다. 따라서 모델의 evaluation하기 위해서는 8732개의 default box중 유의미한 box만을 추려내는 작업이 필요합니다.
1. predict score이 min score( 0.01 )을 기준으로 보다 높은 값을 갖는 상자만을 추립니다.
2. 가장 높은 score의 상자로 내림차순 정렬을 합니다.
3. 가장 높은 상자부터 차례로 그것의 아랫 상자들( score가 더 낮은 상자)과의 IoU를 구하여 일정 threshold( 0.45 ) 이상이 된다면, 서로 같은 물체를 예측했다고 가정하여 score가 더 낮은 상자를 제거합니다.
4. 이를 내림차순 정렬한 모든 상자( 제거된 상자는 내림차순에 업데이트 )에 적용하면 유의미한 상자들로 추려지게 됩니다.
이를 NMS라고 합니다. NMS를 적용한 상자들을 최종 eval에 사용하게 됩니다.
논문만을 보고 코드를 구현한다는것은 아주 어려운 일이였습니다. 짜여진 코드를 보고 논문과 비교하며 이해하는것과, 논문만을 보고 코드를 짜는것은 차원이 다른 영역인 것을 깨달았습니다.
SSD에 대해서 디테일한 리뷰 감사합니다. 본인이 생각하는 SSD의 문제는 무엇인지(개선할 부분은 무엇인지) 그리고 그와 비슷하게 실제 SSD는 어떻게 개선되고 있는지 궁금합니다(이후 개선된 SSD 관련 논문은 어떻게 되는지)