
[그림 1] Localization에서 사용되는 segmentation을 맨 오른쪽 처럼 정의한다.
Localization task에서 영상에 일관성있는 특징을 주기 위해서 Segmentation mask를 활용하는 방법들을 자주 이요한다. 하지만 기존 방법론들은 한정되어있는 class를 표현하는 단점을 갖고있어 서 다양한 상황에 대해서 표현을 하지 못하는 순간이 생긴다. 이러한 Segmentation mask의 단점을 보완하기 위해서 이 논문에선는 클래스를 데이터셋의 kmeans cluster로 정의한 후 각 cluster를 class로 사용하는 방식을 차용해 Self-Supervised 방식의 Segmentation Mask를 제안한다.
- Introduction
- Fine-Grained Segmentation NetWork(FGSN) 을 제안한다. 이 네트워크는 사람이 정의한 class가 아닌 k-means로 정의된 Dense segmentation mask를 output으로 나온다.
- 이 K-means로 정의된 방식이 visual Localization에 적용시켰을때 성능향상을 이룬다.
2. Method
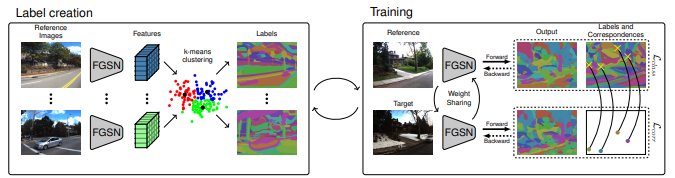
2.1 Fine-Grained Segmentation Networks
- FGSN은 기존 Segmeatation Newtworks 구조와 동일한다.
- 그림2 에서처럼 학습 중 일정 구간 마다 FGSN으로 추출한 Feature들로 Kmeans cluster를 구한 후 각 pixel에 해당하는 class로 정의한다. 그 후 그 class로 학습을 진행한다.
- 계절의 변화와 시각적인 변화에 강인성을 주기 위해서 같은 위치를 촬영한 영상(reference image)을 학습시에 사용하고 두 영상이 같은 Segmantation mask 를 생성하도록 학습한다.
2.1.1 Label creation
- 라벨은 학습 일정 순간 마다 재정의 된다.
- 모든 reference image에서 cluster를 추출한다.
- 빈 cluster center가 있을경우 비어있지않은 center값에서 random 하게 가져온다.
2.1.2 Loss
loss를 두가지로 구성되어있다. correscpondence를 계산하는 Lcorr과 Pixel당 class를 맞게 생성했는지 보는 Lclass이다.
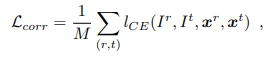
- Lcorr: Ir은 기준 영상이고, It는 Cor image, xr은 sample pixel이고 xt는 xr에 대응하는 pixel이다. M은 샘플의 갯수. ICE는 식2와 같다.
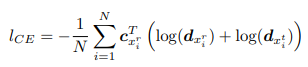
- Lclass: 모든 Sample의 평균
3. Results
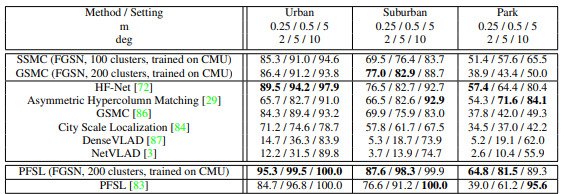
기존 방법론들과 비교했을때 PFSL에 FGSN을 적용시킨것이 최고 성능을 보이는 것을 확인할 수있다.
“Localization task에서 영상에 일관성있는 특징을 주기 위해서 Segmentation mask를 활용하는 방법들을 자주 이요한다. ” (요 ->용)
라는 설명이 있는데 이 내용이 정확히 무슨 의미인가요 …? Segmentation mask를 이용해 일관성있는 특징을 준다는게 무슨말인지 모르겠습니다.
매 input 마다 kmeans cluster 를 찾고 할당하면 시간이 오래 걸릴 듯한데 이에 대한 시간은 따로 리포팅 된 게 있을까요?