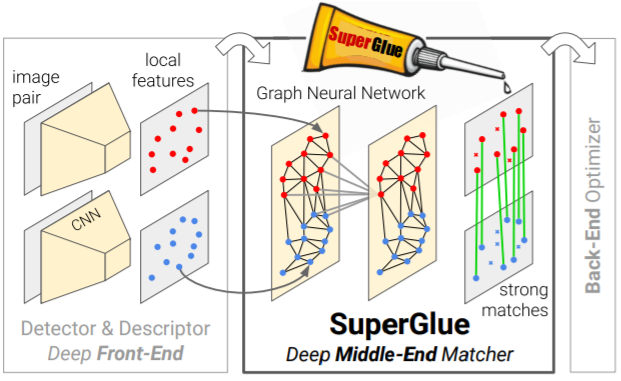
이 논문은 SIFT + BF matching 와같이 두 영상의 local descriptor 끼리 유사한 것들끼리 묶고 불필요한 feature 들은 제거하는 알고리즘을 DNN 방식으로 하는 것을 제안합니다. DNN 기반의 Local Descriptor 추출 자인 SuperPoint 의 저자 논문으로 이 논문에서 또한 Superpoint를 Local Descriptor로 사용한다. GNN을 사용해 각 keypoint 간의 정보를 처리하는데 GNN에 관한 지식이 많이 없어, 식에 관해서 생략이 되었다는 점 유의하시길 바랍니다.
1. Intrduction
기존 heuristics방식보다 나은 그와 비슷한 방식의 것들과는 다르게 Local feature로 부터 학습을해 매칭을 진행하는 SuperGlue를 제안한다. GNN(Graph Nueral Networ)를 활용해 각 local feature 의 위치와 생김새를 잘 표현하는 vector를 생성한다. 이 벡터를 후처리하여 두 영상의 local feature 간의 연관성을 학습한다. 이러한 학습 방식을 통해서 매칭은 기존 매칭 방식들이 갖고있던 고질적인 문제들을 해결한다. 그리고 그림 2와 같이 강한 매칭을 통해 여러 각도에서도 매칭이 되도록하여 3D 추정과 포즈 추정에서도 좋은 성능을 낼 수 있도록 도와준다.

2. Method
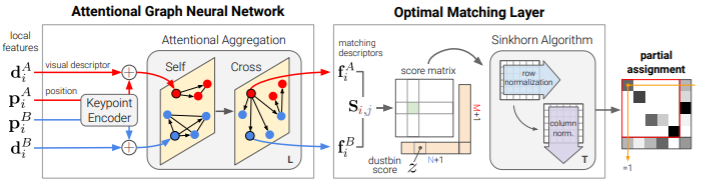
2.1 Attentional Graph Neural Network
2.1.1 keypoint Encoder
그림 3을 토대로 설명드리면, d는 keypoint descriptor 이고 p는 keypoint position 입니다. 두 정보(d,p)를 모두 고려하여 각 feature들 간의 관계성을 고려하기 위해 keypoint Encoder라는 것을 정의해서 두 정보를 하나로 합칩니다. 합치는 방식은 식(1) 과 같습니다.
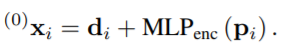
MLP란 Multilayer Perceptron 으로 NN layer이다 이렇게 두 정보를 합치는 방식은 language processiong에서 인기있는 방식이라고한다.
2.1.2 Multiplex Graph Neural Network
Graph의 노드는 각 영상의 keypoint이고, Edge는 두가지로 구성한다. 첫번째는 하나의 영상 내 keypoint 끼리 연결하는 self edges이고, 두번째는 두 영상의 포인트 끼리 연결한는 cross edges이다. GNN을 구성하고 message passing formulation 을 사용하여 두 종류의 Edge를 따라서 정보를 전파한다.
그 결과 GNN은 각 노드에 대해 고차원적인 상태로 시작하여 모든 노드에 대해 주어진 모든 에지에 걸쳐 메시지를 동시에 집계함으로써 각 계층에서 업데이트된 표현을 계산한다.
2.2 Optimal matching layer
두번째 블록인 optimal matching layer는 partial assignment matrix를 생성한다. 이는 두 영상 키포인트간의 유사도 행렬이다. P를 구하는 과정에서 Score를 계산하고, 불필요한 키포인트들을 음의 수로 바꾸는 과정이 진행된다.
3 Result
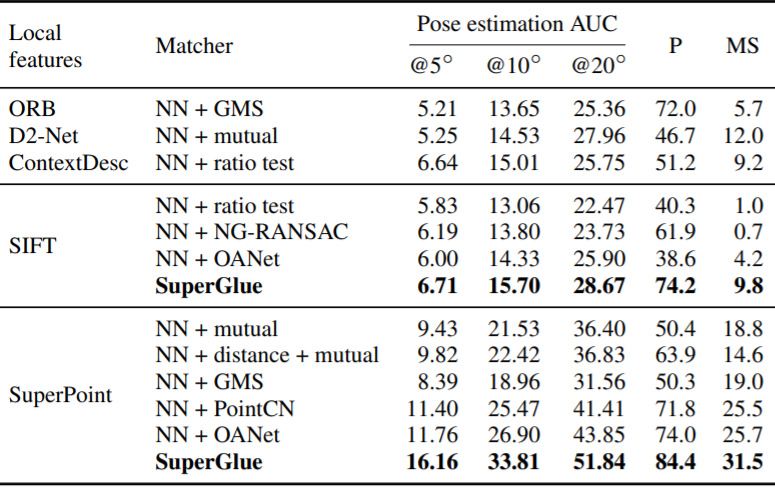
기존 방법론 대비 월등히 높은 성능을 보이는 것을 확인할수있다.
pose estimation AUC는 어떤 방식으로 평가하는 지표인가요?
매칭에 대해서는 설명하고있는데, Pose Estimation에 대해서는 설명이 없는것 같습니다. 마지막 결과를 보면 PoseEstimation AUC라고해서 5도, 10도, 20도에 대한 성능을 리포팅하고 있는데, 해당 결과들은 2D이미지만 가지고 3D Pose를 예측하였을때 정확도인가요?