
논문: ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
블로그 시리즈:
1. Review: PointNet
2. Review: PointNet++
3. Review: VoteNet
3D object detection 시리즈의 마지막 논문인 ImVoteNet입니다. 직전 블로그인 VoteNet[1]에서는 point clouds data만을 사용하여 object detection을 하였습니다. 그렇지만 테이블과 의자가 겹쳐있는 points를 구별하는 것은 어려운 일이죠. 반면 image를 이용하는 detection의 경우 pixel 값의 변화에 따라 구분을 하는 방식이므로 2D data (image)와 3D data (point clouds data)의 장점을 이용하여 3D object detection의 성능을 올리는게 이 연구의 목표입니다.
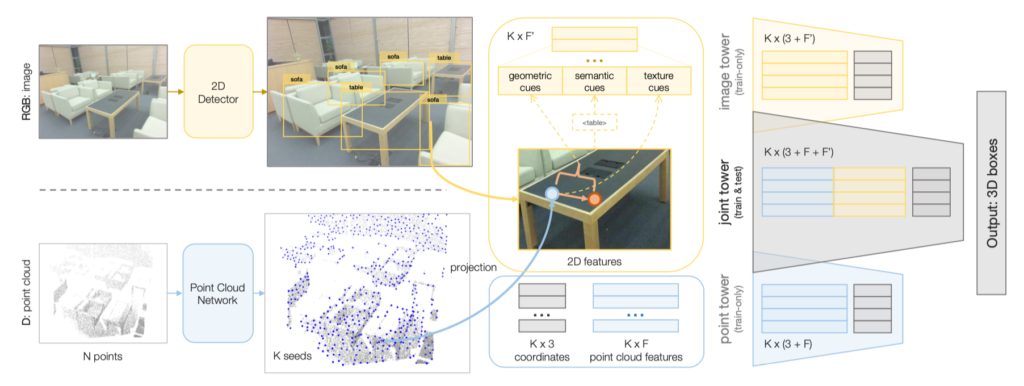
ImVoteNet은 그림 1과 같이 geometric, semantic, texture에 대한 조합을 사용하게 됩니다. 기본적으로 이 모델을 사용하기 위해서는 RGB image와 point clouds의 pair가 필요합니다. 그림 1과 같이 영상의 image를 입력으로 하고 2D detector로 Faster R-CNN[2]를 사용합니다 (물론 데이터에 맞게 2D detection 모델을 학습시켜놔야 합니다). 또한 PointNet++[3]를 사용하여 obejct 별로 seeds를 추출하여 (x, y, z) 좌표 값과 feature를 얻습니다.
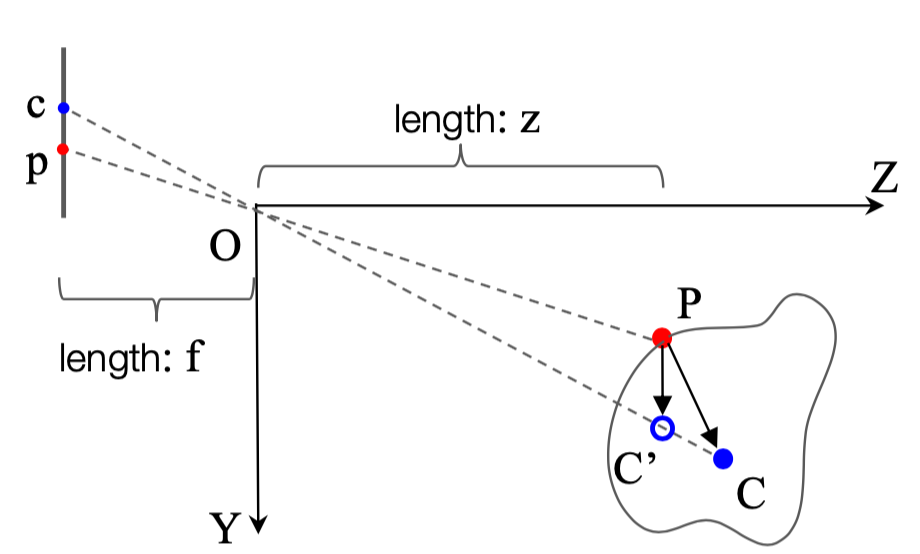
3D vote를 하기 위해 object의 centroid를 찾아야 하는데요. 그림 2를 보면 왼쪽이 object의 2D image를 의미하고, 오른쪽은 3D seeds 좌표를 나타냅니다. 그리고, f 와 z 는 해당 포인트와의 거리를 말하며 C 는 3D object의 중점, C\prime은 \vec{OC} 상에 프로젝션한 중점, P = (x_{1}, y_{1}, z_{1}) 입니다. 또한 \vec{pc} 는 (\Delta u, \Delta v) 로 표현합니다. 이 관계를 가지고 geometric cues를 수식 1과 같이 표현할 수 있습니다.
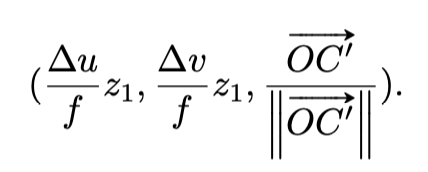
서두에서 언급하였던 겹쳐있던 object에 대해 2D image의 장점을 적용할 차례입니다. 3D seeds를 2D detector에서 찾았던 ROI에서 class의 one-hot score를 semantic cues라고 말하고, 3D vote를 2D image에 프로젝션 시킨 후 해당 포인트의 RGB 값을 그대로 가져오는 것을 texture cues라고 말합니다. 앞서 언급한 geometric, semantic, texture cues는 concatenation을 하여 K\prime 의 길이로 표현하고 2D features라고 합니다.
훈련은 크게 3개의 tower로 진행하는데, 2D features와 3D 좌표를 사용하는 image tower, 3D features와 3D 좌표를 사용하는 point tower, 그리고 모든 것을 사용하는 joint tower로 구분됩니다. Image tower와 point tower는 학습에서만 사용되며, joint tower는 학습과 추론 모두 사용됩니다. 각 tower의 loss는 각 loss별로 weight를 두어 합을 한 것으로 (img, point, joint) = (0.3, 0.3, 0.4) 로 두었을 때 가장 좋은 성능을 보여주었습니다.
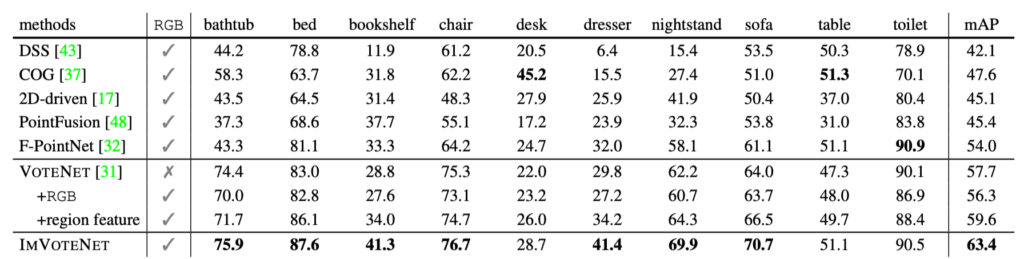
표 1에서는 대부분의 object에서 최고 성능을 나타내고 있으며, 특히 직전의 VoteNet에 비해 모든 class에서 눈에 띄는 성능 향상을 보여주고 있습니다.
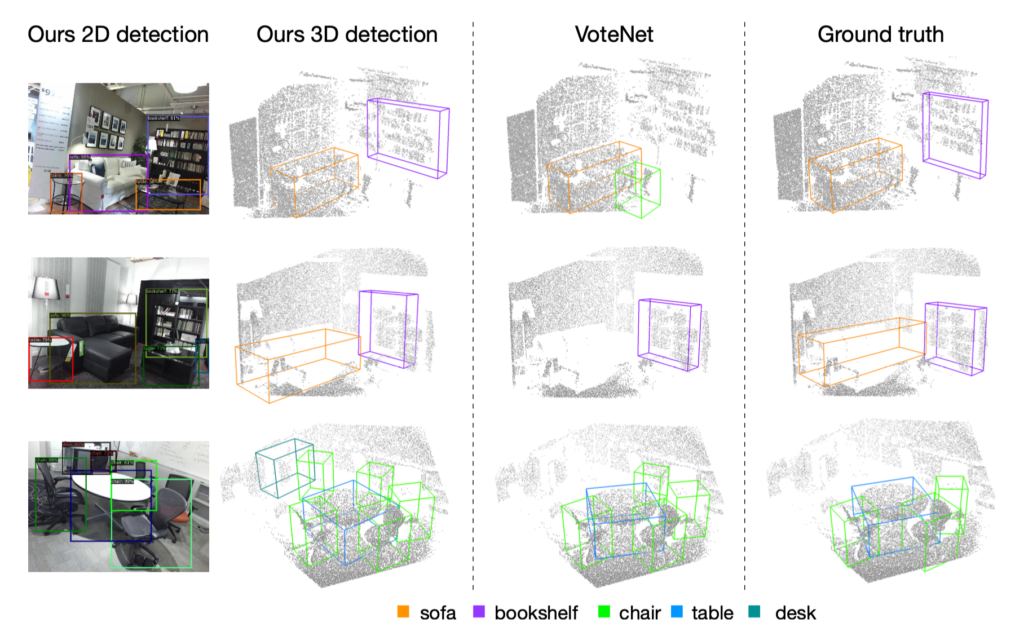
그림 3의 결과가 참 재밌는데 GT에서 미처 표시하지 못한 object까지 찾아서 그려주는 것을 세번째 row에서 확인할 수 있습니다.
예전에 Point++에서 나왔던 질문 중 비슷한 형태의 object를 분류하는 것에 있어 어려울 것 같다는 내용이 있었습니다. 물론 완벽하게 마네킹과 사람을 구분하는 것은 기대하기 어렵겠지만 RGB 값을 사용함으로써 texture를 표현함으로써 해당 이슈에 대해 발전 가능성이 남아 있는 것으로 생각됩니다. 그리고 제안된 모델은 당연히 2D detector의 성능에 따라 달라질 수 있으며 추론 시간 또한 2D detector의 속도에 달려있는 것이 문제라고 생각합니다. 결국 실시간으로 3D object를 찾기 위해 raw point clouds에 집중하여 성능과 속도 모두 만족스러웠으나 다시 2D detector를 사용함으로써 시간이 늘어나게 되었습니다. 물론 2D detector를 요구사항에 맞게 (성능 우선 또는 속도 우선) 변경하면 되는 이야기지만 단순 raw point clouds 만을 사용한 것에 비해 아쉬울 수 밖에 없습니다.
참고:
[1] Deep Hough Voting for 3D Object Detection in Point Clouds
[2] Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
[3] PointNet++: Deep Learning on Point Sets for 3D Classification and Segmentation