리뷰를 할 논문을 찾아보던 중 제목이 흥미로워 보여서 가져와봤습니다.
옛부터 프로그래머들이 어떤 프로그램을 만들면, 해커들은 그 프로그램을 공격하고 악용하는 방법을 찾아왔습니다. 그렇다면 딥러닝도 일종의 프로그램이니깐, 해커들이 해킹을 할 수 없을까요? 정답은 가능하다 입니다.
가장 간단한 예시는 이미지 오분류입니다. 이미지 분류는 딥러닝에 가장 대표적인 프로그램인데 이는 다음과 같은 방식으로 학습합니다.
- 입력 영상을 모델에 넣는다.
- (모델의 종류에 따라 다르겠지만) 여러 가공 및 연산을 통해 예상 레이블을 출력합니다.
- 정답레이블과 예상 레이블을 비교하여 오차정보를 BackPropagation 시킵니다.
- 2~3번 과정을 계속 거치며 정답 레이블과 유사한 레이블이 나오도록 합니다.
이러한 이미지 분류 모델은 고양이 사진을 넣었을 때 고양이라고 대답을 하고, 개 사진을 넣었을 때 개 사진이라고 대답을 합니다. 이렇게 똑똑한 모델들도 입력 영상의 값을 조금만 수정하면 엉뚱한 예측값을 나오게끔 할 수 있습니다.
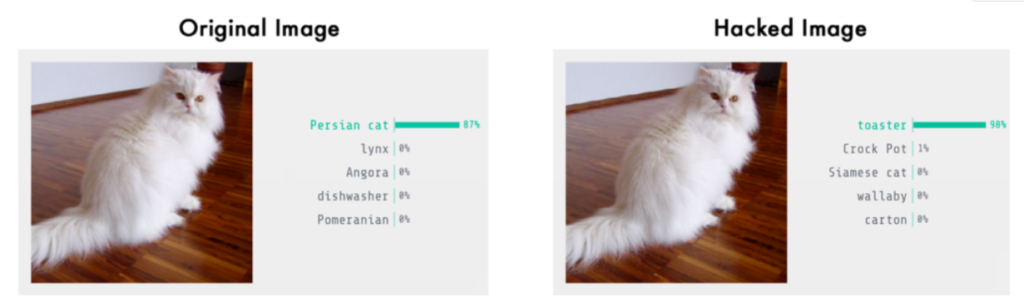
위에 사진을 보 시면 원본 영상을 넣었을 때 페르시안 고양이라고 올바른 예측을 하지만, 해킹된 영상(Adversarial image)을 넣게 되면 모델은 토스터기라고 잘못된 값을 예측하게 됩니다. 사람의 눈에는 두 영상 모두 같아 보이지만, 모델한테는 완전히 엉뚱한 예측을 하게끔 만드는 치명적인 영상입니다.
이러한 Adversarial image는 어떻게 만들 수 있을까요? 방법은 아주 간단합니다. 위에서 설명드린 이미지 분류 모델은 예측과 정답의 오차를 모델 파라미터에 backpropagation하여 학습을 하였다면, Adversarial image를 만들기 위해서는 backpropagtion을 입력 영상에다가 하면 됩니다.
- 해킹을 하고자하는 영상을 입력으로 넣는다.
- 모델의 각종 연산을 통해 예측된 레이블을 출력합니다.
- 예측된 레이블과 우리가 원하는 adversarial label간에 오차를 구한 후 입력 영상에 backpropagation을 진행합니다.
- 2~3과정을 반복하여 adversarial image를 학습합니다.
위와 같은 과정을 통해 기존의 이미지 분류 모델에 대하여 잘못된 예측을 하는 adversarial image를 만들 수 있게 됩니다. 하지만 위와 같은 방식으로 하게 되면, 입력 영상이 사람 눈으로 봤을 때 원본 영상과 달라질 수가 있습니다. 이를 해결하기 위해서, 해당 학습 과정 중에 원본 영상과 학습되는 adversarial 영상 사이의 차이 값이 최소가 되는 조건을 걸어주면 원본 영상과 매우 동일하지만, 모델은 완전히 잘못된 값을 예측하는 adversarial image가 완성됩니다.
하지만 이러한 방식으로 adversarial image를 학습하기 위해서는 먼저 공격하려고 하는 모델(위에 예시에서는 이미지 분류 모델)의 구조 및 파라미터 등 모델 내부를 알아야만 합니다. 위와 같은 경우를 white-box adversarial example이라고 합니다.
Adversarial Goal
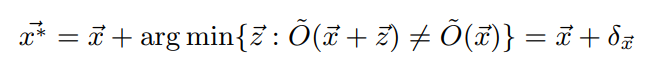
Adversarial attack의 목표는 원본 모델을 속이기 위한 가장 작은 변화값(Perturbation)을 찾는 것입니다. Perturbation의 최소값을 구하는 수식은 위와 같은데 해당 수식에 나오는 변수들은 다음과 같습니다.
- \overrightarrow{x^{*}} : Adversarial image
- \overrightarrow{x} : Original image
- \overrightarrow{z} : Perturbation
- \delta_{\overrightarrow{x}} : minimal Perturbation
위에서 설명했듯이 white-box 경우에는 원본 영상에 더해줄 minimal Perturbation을 찾기 위해서 gradient descent와 backpropagtion이 필요했었습니다.
하지만 해커들은 대부분 상황에서 이러한 모델 내부에 대해서는 알지 못하고, 어떤 입력을 줬을 때 어떤 확률 분포로 결과값들이 나온다 정도만을 알게 됩니다. 이를 black-box adversarial example이라고 합니다. 그렇다면 black-box 경우에는 어떻게 minimal Perturbation을 구할 수 있을까요?
논문에서는 우리가 공격하려는 기존 모델을 대체할 수 있는, 유사 모델을 만드는 방법을 제안합니다. Target DNN을 통해 원본 모델의 Decision Boundary를 근사하는 유사 모델을 만들고, 이 유사 모델을 통해 adversarial dataset을 만드는 것입니다.
유사 모델을 구하고, adversarial datset을 만드는 알고리즘은 다음과 같습니다.

- S_{0} : 초기 데이터셋
- \widetilde{O} : 원본 모델
- \widetilde{O(\overrightarrow{x})} : 원본 모델에 쿼리 데이터를 넣어 생성된 레이블.
- F : 원본 모델에 대한 유사 모델
- D : 데이터 셋 S를 원본 모델 \widetilde{O} 에 넣었을 때 생성되는 레이블의 집합
먼저 첫번째로 입력 도메인을 대표할 수 있는 최소한의 입력 데이터셋 S_{0} 를 지정해야 합니다. 예를들어, 입력 데이터셋이 MNIST일 경우에, S_{0}는 0부터 9까지 총 10장의 이미지만을 가지고 있으면 됩니다.
그리고 유사 모델 F를 정의해줘야 하는데, 이는 논문에서 말하길, 원본 모델의 입력과 출력을 보고 원본 모델이 어떤 모델을 베이스로 했을 것인지 추측해야 한다고 합니다… 예를들면 어떤 모델에 입력이 영상이고, 출력이 그 영상의 레이블이라면 해당 모델은 CNN 구조를 사용했겠구나..정도로 예측하면 된다는데 조금 당황스럽네요.
아무튼 그 다음에는 원본 모델의 Decision Boundary를 근사할 수 있도록 유사모델 F를 반복적으로 학습합니다. 일단 데이터셋 S에 대한 레이블 값을 구하기 위해 해당 데이터들을 \widetilde{O} 에 넣어줍니다. 그 다음에 해당 레이블 셋 D와 정의해준 유사 모델 F를 학습합니다.
그 후에 자코비안 방식으로 Data augmentation을 진행하여 기존 데이터셋 S_{n}을 S_{n+1} 로 만들어서 데이터셋의 크기를 늘려줍니다. 이렇게 늘어난 데이터셋은 유사 모델 F가 원본 모델의 Decision boundary에 더 정확히 근사하게끔 만들어준다고 합니다.
해당 알고리즘을 도식화하면 아래와 같습니다.
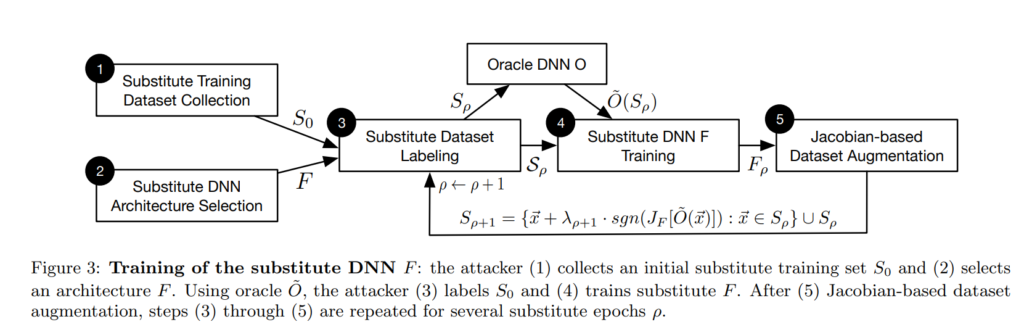
위의 과정을 통해 원본 모델에 근사된 유사 모델 F를 구하였으면 black box 경우가 white box로 봐도 무방하기에 이제 백프롭을 이용하여 minimal Pertubation을 구할 수가 있게 됩니다.