

이번 ICIP 2020 에 Multispectral image 를 이용한 해당 논문이 나오게 되었습니다. 논문에서 제안한 네트워크의 주된 아이디어인 cyclic fusion 의 반복적으로 feature 를 더해가는 방식과 detection, segmentation을 동시에 학습하는 multi-task learning 방식은 성능 향상을 위해 detection task 에서 흔하게 사용되던 방식이었는데, 이러한 방식들의 조합으로 SOTA 를 찍었습니다. 저자가 이 방식들을 어떻게 구성하여 성능을 높일 수 있었는 지 리뷰하도록 하겠습니다.
1. Proposal Module : Cyclic fuse-and-refine module (CFRM)
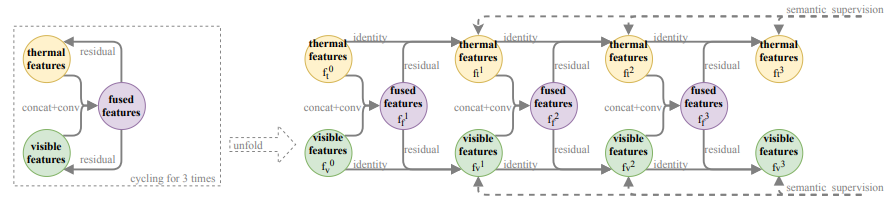
1.1 Fuse-and-Refine
우선 multispectral image 에서 각각 feature 를 얻어내고 이를 fusion 하는 과정을 3회 거치게 됩니다. 이로 인해 multispectral 한 feature 들의 표현이 좀 더 일관성 있어지고, RGB와 Thermal 간의 상호보완성을 줄일 수 있다고 합니다. 여기서 상호보완성을 줄일 수 있는 장점을 갖는다는 말은 1.3 에서 설명 드리겠지만 결국 마지막에 매 반복과정의 feature 들을 합하게 되는데 이때 어떤 물체를 가리키고 있는 위치의 feature 값이 상호보완적으로 합해진다면 그 물체의 특성이 상대적으로 더 작게 표현되기에 장점이라고 표현한 듯 합니다.
좀 더 자세하게 multispectral feature를 concat 한 후 Conv+Batch Norm layer를 통과 시켜 fusion 시킵니다. Fusion 시 사용한 모든 반복의 Conv+Batch Norm layer의 weight는 overfitting 을 막기 위해 모두 공유된다고 합니다. 이렇게 fusion 된 feature 와 각 multispectral feature 들과 원소 합을 한 뒤 activation function 을 통과시키고 다음 반복의 multispectral feature 로 사용하게 됩니다.
1.2 Semantic supervision

앞서 설명드린 것과 같이 여러 번의 fusion 을 하게 되면 vanishing gradient 문제가 생길 수도 있습니다. 저자는 이를 막기 위해 feature fusion 의 가이드 역할로 semantic segmentation 을 사용했습니다. Fusion 된 각 multispectral feature 에 1×1 Conv 연산으로 채널을 두 개로 변환한 뒤 사람인 부분과 아닌 부분으로 나뉜 segmentation mask로 이를 튜닝하게 됩니다.
1.3 Final Fusion
3회의 반복을 거친 뒤 생기는 6개의 multispectral feature 들을 모두 원소 합한 뒤 평균을 내어 통합된 feature 로 표현하게 됩니다.
2. Experiment
본 방법은 Fusion SSD 기반으로 실험하여 VGG backbone 에서 conv4_3 까지는 동일하며 이후에 제안된 CFRM 을 적용해 실험 하였습니다. 비록 FSSD 기반을 하였으나 저자는 제안된 모듈은 고른 네트워크와 독립적으로 작용된다고 합니다.
글리고 Loss function은 detection 과 segmentation 을 같이 학습한 SDS RCNN, MSDS RCNN 과 동일합니다.

Fig 4. 는 반복 횟수에 따른 예측된 semantic segmentation mask 차이를 보여줍니다. 반복할 수록 mask가 정교하게 예측되는 것을 확인할 수 있습니다.
3. Result
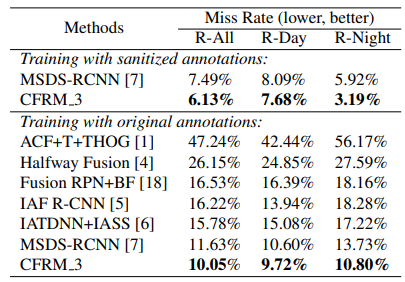
KAIST Dataset 에서 제안된 CFRM 은 본래의 annotation 과 MSDS RCNN 에서 튜닝하여 제공한 annotation 에서 모두 SOTA 에 해당하는 성능을 달성하게 되었습니다.

그리고 Table 2. 를 통해 SOTA 를 찍을 수 있었던 성능 향상 요인에 CFRM 이 확실히 기여했다는 것을 확인할 수 있습니다.
FSSD를 베이스로 하고 있네요. 해당 연구를 구현하고 우리 아이디어 적용이 가능한지 확인해 보는 것 혹은 우리쪽에 해당 연구의 아이디어를 적용하는 것 Cross로 체크해 주세요.
이 논문에서 보라색 fused feature 를 concat 하고 conv로 인코딩하는 부분을 adaptive fusion module 로 대체 하여 fusion 한다면 아이디어를 적용할 수 있을 듯 합니다