intro
이번 주에는 camera calibration에 관련하여 학습하여 그와 관련된 논문들을 학습하던 중 다음과 같은 논문을 발견하여 공부해보았습니다.
논문 내용을 한줄 요약하자면 ‘unsupervised learning을 통해서 Dense Depth,Optical Flow,Camera pose를 예측하겠다’입니다.
우선 왜 우리가 분류문제나 회귀문제를 풀 때 자주 사용하는 supervised learning 방식이 아니라 unsupervised learning 을 통해서 학습할까요?
그 이유는 supervised 보단 성능이 떨이지지만, 첫째 학습하려는 내용의 GT를 만들어내기 어렵기 때문에 특정 domain에 대해서만 라벨을 가지고 학습 할수있습니다.따라서 이를 통해서라면 다양한 domain에 적용 불가능 하겠죠?그래서 다양한 domain에 자유롭게 적용하기 위해서 unsupervised learning 을 사용한다고 합니다.
3D Geometry
그렇다면 Depth,Optical Flow,Camera pose는 무엇일까요? 그리고 왜 이 3개가 동시에 필요한 것 일까요?
depth:이미지에 등장하는 각 pixel이 camera로 부터 몇m떨어져 있는지를 나타내는 Map
optical flow:연속한 두 frame 사이에서 각 pixel의 motion을 나타내는 vector map
camera pose:카메라의 촬영 각도가 시간에 따라 변한 Transform을 구함
위와 같은 것을 동시에 이용해야 하는 이유는상대적인 움직임을 다 고려해서 정확한 object의 움직임을 분석하기 위함입니다.
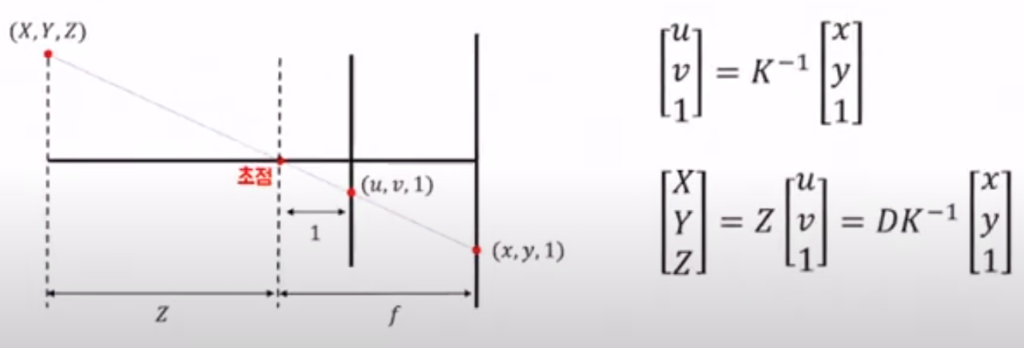
이제 coordinate에 대해서 알아보죠
월드 좌표계=(X,Y,Z)
카메라 좌표계(image coordinate)=(x,y,1)
정규 좌표계=(u,v,1)
image coordinate=(x,y)
x=fx*u+cx (f=pixel:meter를 알기위함)
y=fy*v+cy
이고 정규 좌표계와 카메라 좌표계 사이의 관계인 K는 카메라 내부 파라미터 값인 fx,fy와 cx,cy로 구성됩니다.
이제 카메라의 회전과 평행이동에 따른 좌표 변화에 대해 알아봅시다
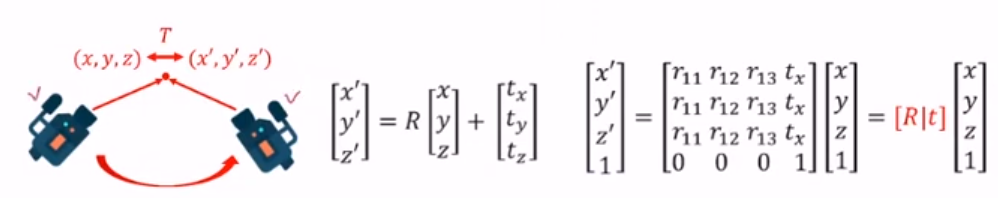
카메라의 회전각도 그리고 평행이동에 따라 이동한 좌표는 회전변환 관계와 평행이동 관계를 고려해 위와같이 구할 수 있습니다.
GeoNet
Rigid and Residual Motion

이 내용이 GeoNet의 핵심 기반이 되는데 카메라 움직임에 의한 Motion과 실제 Object의 움직임에 의한 Motion을 독립적으로 구분(각 계산 시 다른 움직임은 없다는 가정)하여 정의 하고 이를 동시에 계산하여 실제로 object가 어떻게 움직였는지 정확하게 고려할 수 있게됩니다.
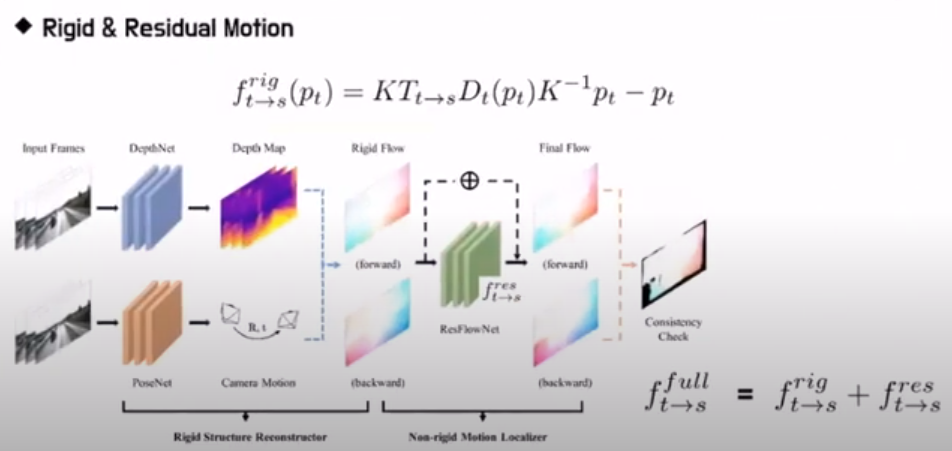
우선 Rigid flow를 구하는 과정은 다음과 같이 image coordinate의 값인 pt값을 K변환을 통해 정규 좌표계로 보내고 여기에 뎁스를 곱해주어 월드 좌표계로 보낸 후 이 상태에서 t->s 즉 타겟 이미지에서 소스 이미지로 가는 변환을 곱해주고 다시 K변환으로 2D로 내려준다
이렇게 되면 결국 첫항(-이전)은 소스 이미지에서 대상의 위치가 되고 마지막 항(-이후)은 타겟이미지에서 대상의 위치가 되어 그 차이(flow)를 구할 수 있다.
마찬가지고 residual flow를 구해서 더해주면 full flow가 나오고 이를 loss 계산에 연결하면 Rigid Motion 과 Residual Motion을 동시에 고려하게되어 object가 어떻게 움직였는지 정확하게 고려할 수 있게됩니다.
참고문헌
https://arxiv.org/pdf/1803.02276.pdf
https://darkpgmr.tistory.com/77
Rigid flow의 내용이 쉽게 이해가 되지 않지만 아무튼 object의 움직임을 알 수 있다는 방법으로 이해했습니다. 위의 가정에서 object를 제외한 다른 것은 변화가 없다는 가정이었으니 두개의 영상 사이에서 object만 움직였겠지요. 그렇다면 object의 움직임의 결과는 어떤 형식으로 나오나요? 변환행렬 같은 것을 얻는건가요?