
Color 이미지로 Object Detection을 수행하는데 있어 밤,안개,먼지 등의 환경은 Detection의 성능을 크게 하락시키는 요인이 됩니다. 그래서 강인한 Object Detection은 앞으로 다가올 자율주행차에 있어서 핵심 기술이고, 이를 위해서 많은 연구가 이뤄지고 있습니다. 대표적으로는 저희 연구실에서 수행중인 Adaptive Fusion이 있습니다.
본 논문도 같은 문제점을 해결하고자 하는 취지로 진행된 연구입니다.

본 논문에서는 color 이미지만 입력으로 주고 invisibility map을 예측합니다. 해당 논문에서 제안하는 시스템을 통해서 구한 invisibility map은 pixel level의 invisibility score를 예측하고, 이를 통해서 color image를 통해 구한 detection 결과가 얼마나 신뢰할 수 있는지를 판단할 수 있게 합니다.
System Overview
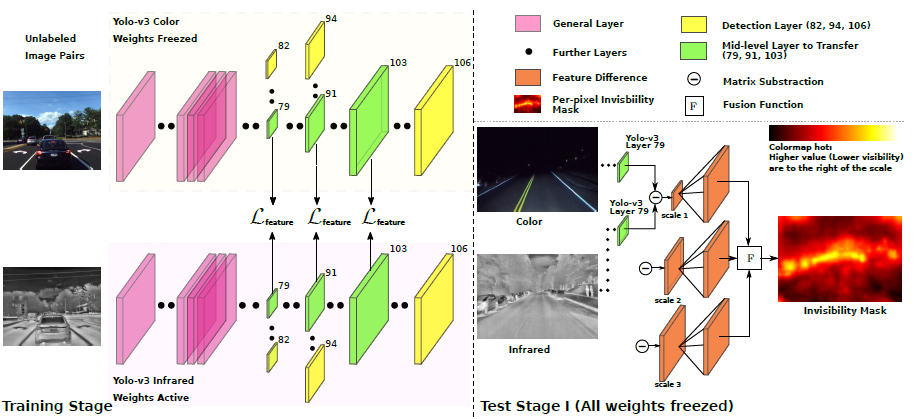
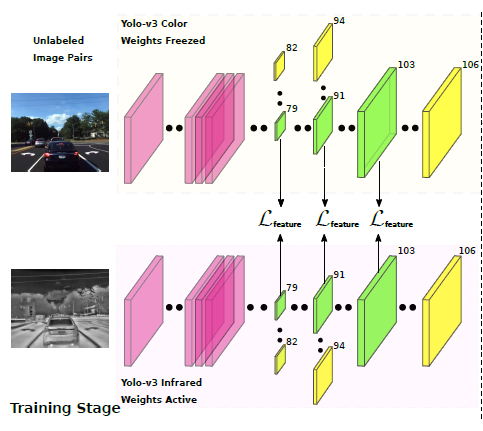
논문에서 제안하는 시스템은 unsupervised 방법으로 color image에서 pixel level의 invisibility maps을 생성한다. 학습과정에서 해당 시스템은 weakly-aligned color-infrared image pairs를 입력받고, 이 image pairs의 geometric differences는 AlignGAN에 의해서 제거되고 aliggn 된다. AlignGAN을 통해서 well-align된 image pair를 만든 후, Knowledge Transfer system을 통해 color domain에서 infrared domain으로 represestation을 transfer하도록 학습한다. 테스트에서는 앞서 언급한 image pair를 통해서 color 이미지의 모든 pixel마다 invisibility score를 추정하도록 한다. (추가적으로 학습된 infrared image의 representation을 이용해 추가적인 수동 라벨링과 재학습 없이도 infrared image 만으로도 object detector를 진행할 수 있다.)
1. Alignment Generative Adversarial Network
해당 논문에서는 weakly-aligned color-infrared pairs로 부터 well-aligned color image를 생성하는 AlignGAN을 제안하고 있다. 해당 네트워크를 나타내는 그림은 다음과 같다.
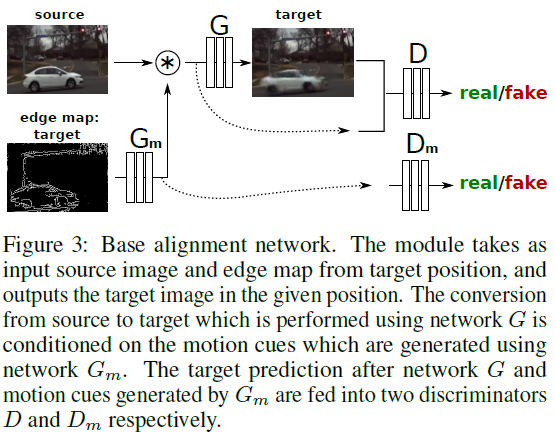
Pix2pix을 기반으로 만든 AlignGAN은 두가지 방법으로 학습을 진행하는데, 첫번째는 color image를 source로, weakly-aligned infrared image는 edge map으로 사용해 학습을 진행한다. 이때 Flownet2를 사용해 만든 이미지를 target으로 사용한다. 두번째는 color image를 source로 그리고 edge map으로는 동시에 다른 카메라에서 촬영된 color image로 사용하며, 이때 taget도 해당 color image가 된다.
2. Knowledge Transfer From Color to Infrared Domains
논문에서 저자는 Color domain의 representation을 infrared domain으로 transffer한다. YOLO v3에서 다른 스케일을 갖는 3개의 mid-level feature들을 가지고 Transfer를 수행한다.
3. Invisibility Estimation
본 논문에서 제안하는 시스템은 2개의 detector를 갖는다. 하나는 richly-annotated data sets으로 학습한 Y_olo_color와 AlignGAN을 통해 well-aligned image pair를 이용해 학습한 Y_olo_infrared 이다. 이 두 detector는 같은 intermediate level feature를 만든다. infrared image가 color image에 비해서 lighting condition에 의한 영향을 훨씬 적게 받아 mid-level feature에서 각 feature 간의 차이가 발생하는데, 해당 모델은 이 차이를 계산해 color image의 모든 픽셀에서 대해서 invisibility score를 추정한다.
Experiments
1. How good is the prediction of the undetected area in the color image?
(생략) 해당 파트는 해석은되도 뭔소린지 모르겠습니다. 도와주실분 구해요
2. Can paired data facilitate detection using transfer learning?
(생략) 해당 파트는 해석은되도 뭔소린지 모르겠습니다. 도와주실분 구해요
3. Which layer is more effective?
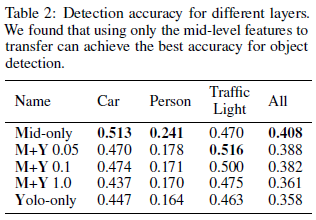
저자는 어디서 합치는게 좋은지 테스트 해봤다고 한다. mid-only feature가 가장 좋은 결과(40.8%)를 나타냈고, mid-last는 36.1%, Yolo-only는 35.8%를 나타냈다고 한다. 그 결과는 위에 표에 나타낸다. 그리고 추가적으로 yolo layer에 다양한 weight를 가지고 평가도 진행했다고 한다. 결론적으로는 그냥 있는 YOLO 모델에서 안건드리고 mid-level feature만 가지고 진행했을때가 가장 좋다고 한다.(왜 실험한거지)
4. How much will the AlignGAN help the detection?
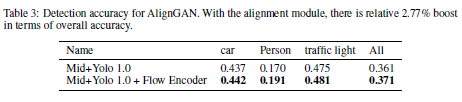
예상대로 AlignGAN을 사용할때 성능이 2.77% 올랐다고 한다.
5. How many pairs are needed to get a good transfer?
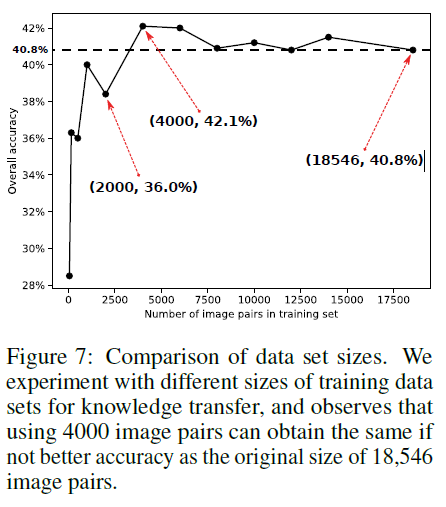
얼만큼의 pair 이미지가 good transfer를 위해 필요한지 실험하였고 위의 결과와 같다고 한다. 4000장을 사용할때가 가장 효과적이였다고 말한다.( 이 실험은 왜 한거지)
Conclusion
본 논문에서 저자는 color image가 주어질때, pixel-level로 invisibility mask를 예측한다. 그리고 이 과정에서 어떠한 manual labelling이 요구되지 않는다. 또한 peer color images에서 transfer 된 mid-level feature를 infrared domain에서의 object detection에 사용하는게 효과적인것을 나타냈다(?) 암무튼 결론적으로 pixel level의 invisibility mask는 multiple sensor를 혼합할때 confidence map으로 사용될 수 있다고 한다.
Review
논문을 읽었는데, 실제 앞에서 말한것과 다르게 논문에는 아무런 내용이 없다. 그냥 정리하면 논문에서 RGB-IR 이미지의 pair를 맞추기 위해서 Pix2pix 기반의 AlignGAN이라는걸 만들어서 pair를 맞췄고 이를 통해서 성능을 2.7% 올릴 수 있었다고 한다. 그리고 RGB-IR을 통해서 어떠한 labeling 없이도 RGB 이미지의 invisibility map이라는 것을 pixel level 로 구할 수 있었고, 이는 실제 RGB 기반의 object detection 수행서 이 map을 활용해 해당 지역의 object 가 FP인지 TP인지 구별하는데 많은 도움을 줄 수 있다고 논문은 이야기하고 있다. 그런데 결론적으로 invisibility map은 어떤식으로 정확도를 평가했는지는 나타내지 않고 그냥 자동차, traffic line, car의 accuracy만 나타내고 있다. 여기서 말하는 accuracy가 pixccel level의 정확도를 말하는 것인가…? 근데 detection accuracy라고 만 표현해서 그것도 모르겠다. 그리고 많은 실험을 진행한것 같은데 이걸 왜 한거지? 라는 생각이 드는 실험들이 있었다. 결론적으로 내가 무슨 실험을 하더라도 충분히 근거를 바탕으로 내가 한 실험의 논리적인 이유를 남들에게 잘 설명하는 것이 중요하다는 것을 알았다. 결론적으로 이 논문에서 원하고자 하는것은 AlignGAN에 대한 정보인데 실제 논문에서는 이에 대한 깊이있는 내용도 디테일하게 설명하고 있지 않아서 별로다… (아래가 AlignGAN을 설명하는 내용의 전부이다.)
