해당 논문은 stereo 영상들로부터 Learning based method으로 disparity map을 얻는 방법을 제안한다.
Group-wise Correlation Network
해당 세션에서는 group-wise correlation stereo network(GwcNet)을 소개한다. GwcNet은 PSMNet[1]의 group-wise correlation cost volume과 3D stacked hourglass network를 개선한 방법이다.
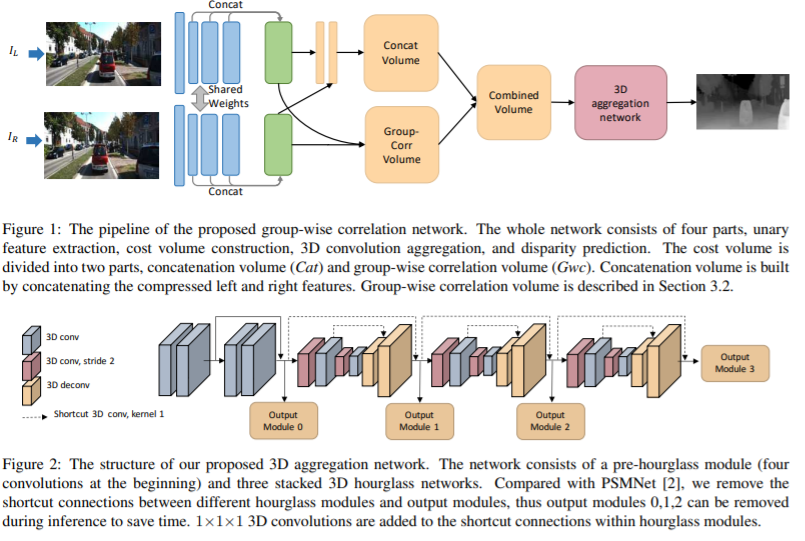
Network architecture

GwcNet의 구조는 Fig 1.에서 보여지는 형태와 같다. 해당 네트워크는 unary feature extraction, cost volume construction, 3D aggregation, disparity prediction (자세한 구조는 table 1. 참고) 4개의 파트로 구성된다.
unary feature extraction는 ResNet 계열의 네트워크를 이용하며 spatial pyramid pooling module이 없는 상태로 추론되어진다. ResNet의 conv2, conv3, conv4의 마지막 feature map의 concatenated하여 320-channel unary feature mpas을 얻는다.
cost volume은 두 개의 파트로 구성되어진다. 첫번째는 concatenation volume은 PSMNet에서 제안한 것과 동일하다. 그러나 보다 적은 채널을 사용한다. 두 개의 회선으로 12개의 채널로 압축된다. 두번째는 논문에서 제안한 group-wise correlation volume이다. 해당 내용은 아래의 세션에서 소개할 예정이다. 이 두 파트는 3D aggregation network의 input으로 사용되어 진다. – Group-wise correlation volume
3D aggregation network는 pre-hourglass module과 3개의 3D hourglass network로 구성된다.(Fig 2.) pre-hourglass module은 batch-normailzation과 ReLU와 함께 4개의 3D convolution으로 구성된다. 3개의 3D hourglass networks는 low-feature의 애매모호함과 occlusion part를 재정립하기위해 인코더-엔코터 구조로 구성되어진다. – Improved 3D aggregation module 참고
Disparity prediction은 3D hourglass network의 출력 모듈로부터 얻은 값으로 disparity map을 예측한다. – Output module and loss function 참고
Group-wise correlation volume
기존의 Learning base stereo matching에서 사용되어진 방식으로 concat volume과 correlation volume이 있으며, 단점들이 존재한다. correlation volume일 경우 왼쪽, 오른쪽 feature간 단일 채널에서만 disparity map을 생산하기 때문에 많은 정보를 잃어버린다. concat volume은 feature에 대한 유사성에 대한 정보가 없으므로, 유사성을 학습하기위해 보다 많은 파라미터를 사용해야한다.
Group-wise correlation volume은 위에 이야기한 단점들을 극복하고자 제안한다. 기본적인 아이디어는 feature를 그룹 단위로 나누고 계산하는 것에 있다.
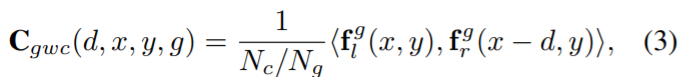
- N_c : 단항 feature
- N_g : 그룹화된 features
- f_{l, r} : 왼쪽/오른쪽 feature map
- d : disparity levels
Improved 3D aggregation module
3D aggregation module은 PSMNet과 동일하지만 중요한 몇가지는 다른 형태로 구성되어져 있다. (1) Fig 2.의 module 0을 추가적인 출력 모듈로 설계하였다. (2) 추론시 출력 모듈 (0, 1, 2)를 제거하여 계산비용을 절감할 수 있다. (3) 1x1x1 3D conv를 각 hourglass module 내의 바로 연결하여 큰 계산비용 증가 없이 성능 향상을 시킨다.(Fig 2. 점선)
Output module and loss function
각 출력 모듈에 대해 2개의 3D conv를 이용하여 1채널의 4D volume을 생성한다. 그 다음, 업샘플링하고 disparity dimension에 맞춰 softmax를 이용한 확률 volume으로 변환한다. (자세한 구조는 table 1. 참고)
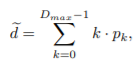
- D_max : 길이
- p : probability p for all disparity levels.
- ~d : disparity estimation
4개의 출력 모듈로부터 얻은 disparity estimation d_i (i = 0, 1, 2, 3)는 smooth L1 loss로 계산되어진다. lamda_i는 하이퍼파라미터로 예측의 계수로 사용되어진다. d^*은 ground-truth disparity map이다.

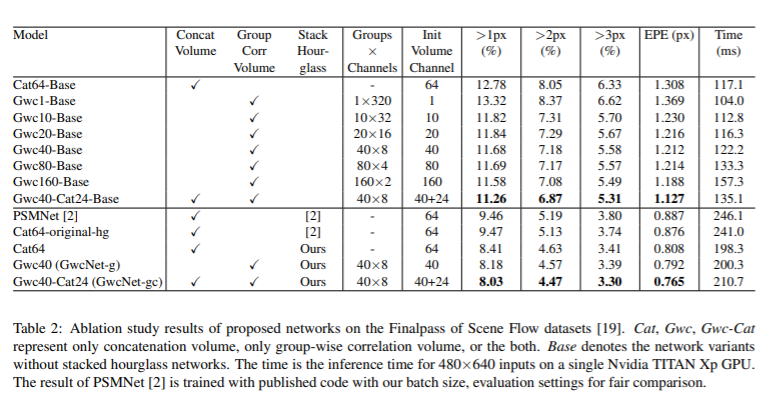
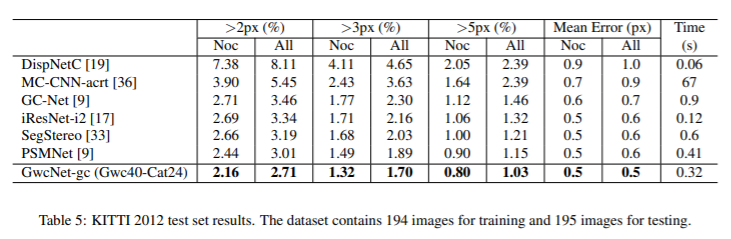
Evaluation
[1] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 5410– 5418, 2018.
PS. 선택한 논문이 처음 접한 분야이기도 하고, [1]의 확장격 논문이다 보니, 생략한 부분이 많았습니다. 시험이 끝나고 [1]과 전통적인 stereo matching 이해하여 해당 리뷰에 대한 이해와 보충을 추가하도록 하겠습니다. 부족한 리뷰 죄송합니다.
그래서 기존 PSMNe에 어떤 부분이 ㅜ문제 여서 ㅇ무엇이 바뀐건가요