

2012년 CVPR에 나온 조금 오래된 논문이지만 Visual localization을 image retrieval 기반으로 함에 따라 retrieval 성능 향상의 방법을 소개한 이 논문을 리뷰하려 합니다. 참고로 이 논문의 저자는 후에 NetVLAD를 제안하신 분입니다.
1. RootSIFT
매번 SIFT 보다 좋은 성능을 나타낸다고 해서 사용했던 RootSIFT 를 누가 제안한지 모른고 사용해 왔었는데 이번 논문을 보고 본 논문에서 제안했다는 것을 알게 되었습니다. RootSIFT 의 원리는 SIFT와 크게 다르지 않습니다. 그러나 다른 점은 매칭을 할 때 사용하는 descriptor 에 있습니다. SIFT로 얻어낸 descriptor 로 매칭을 할 때, 주로 euclidean distance를 사용하게 됩니다. 만약 이 두 descriptor 가 unit vector 라면 두 벡터 사이의 거리 계산은 다음과 같이 나타내어질 수 있습니다.
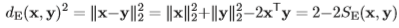
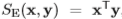
그러나 본 논문의 저자는 위 식처럼 euclidean distance 로 구하는 것보다 Hellinger kernel 을 적용시켜 구하는 것이 더 효율적이라고 제안했습니다. Hellinger kernel 이란 식 (3)과 같이 나타내집니다.
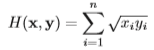
그리고 몇가지 수학적인 과정을 거치면 Hellinger kernel 을 SIFT descriptor 에 적용할 수 있습니다. 우선적으로 SIFT descriptor 를 normalize 합니다. 원래는 L2(euclidean distance) normalize 를 했다고 가정했지만 L1 normalize 를 해도 unit vector 가 되기에 SIFT descriptor 를 L1 normalize 합니다. 그러면 식 (1) 과 같이 짧게 표현이 됩니다.
그 후 각 vector 요소들에 root 를 씌웁니다. 그럼 식 (4) 와 같이 S_{E} 가 Hellinger kernel 로 변환 되는 것을 알 수 있습니다.
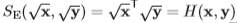
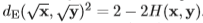
이렇게 변환 되어 식 (5) 와 같이 나타낸 것을 RootSIFT 로 제안하며 기존 SIFT 와 비교했을 때 descriptor 에 root 만 씌운 것과 같기 때문에 SIFT 이후 과정을 그대로 적용할 수 있는 장점이 있다고 합니다. 그리고 성능 면에서도 Oxford 105k dataset 기준 0.515에서 0.581 로 올릴 수 있었다고 합니다.
2. Discriminative query expansion
주로 QE 라고 불리우는 query expansion 은 retrieval system 에서 성능 향상의 주된 영향을 끼칩니다. 그 중에서도 average query expansion 은 주어진 query 에 대해 tf-idf(Term Frequency – Inverse Document Frequency, 한 문장 내에서 단어가 얼마나 중요한지 확인하는 지표) 라는 유사도로 순위를 매기고, top-rank 된 이미지들 중에서 spatial verification 을 하는 과정을 거칩니다. Spatial verification 이 되고 query 와 동일한 부분에 해당하는 ROI의 BoW vector도 얻어낼 수 있으며 query와 이미지들의 ROI BoW vector 들을 함께 평균내어 얻은 vector 로 database 에서 query 에 대한 후보군을 다시 뽑게 됩니다.
이러한 AQE 의 방법과 달리 본 저자는 DQE (Discriminative Query Expansion) 의 방법을 제안합니다. DQE도 AQE의 BoW vector를 이용한 방식과 동일합니다. 그러나 AQE 는 tf-idf 로 유사도 점수를 매길 때, 평균내어진 query의 idf로 가중된 BoW vector를 사용합니다. 반대로 DQE 는 SVM 으로 훈련된 가중치를 사용하게 됩니다. 이는 Fig 2. 에서 볼 수 있듯이 AQE는 두 벡터 사이의 거리로만 표현한 것과 달리 DQE는 SVM 으로 학습시켜 positive 와 negative 를 임의의 경계로 나눠 순위를 매겼고, Oxford 5k 데이터 셋에서 약 1% 정도의 성능 향상을 얻었습니다.
3. Database-side feature augmentation
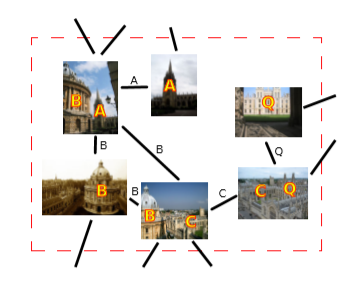
이 논문 이전 Turcot 과 Lowe라는 연구자들은 retrieval 의 성능을 올리기 위해 Fig 3. 과 같이 그래프에 있는 모든 인접 이미지의 visual word 수로 augmentation 하였습니다. 이는 query expansion 에서의 문제들을 데이터 베이스 측면에서 상호보완해준 방식입니다. 그러나 이 방식은 인접 이미지의 모든 visual word 로 augmentation을 하기에 시각적으로 보이지 않는 visual word 에 대해서도 augmentation 되어 연관성이 없는 인접 이미지도 포함될 수 있습니다. 저자는 이 방식에서 눈에 보이는 visual word 만을 이용하고, query 와 인접 이미지에서 동일한 visual word 에 대해 homography 를 추정할 수 있을 때만 image graph를 만들어 인접 이미지를 구하는 방식인 SPAUG(Spatial database-side feature augmentation) 을 제안했습니다.
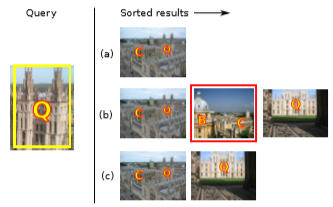
Fig 4. 에서 (a)는 image graph 를 구성하지 않고 tf-idf 유사도가 가장 높은 한 장의 이미지를 선택했을 때, (b) 는 Turcot 과 Lowe 의 image graph 구성방식, (c) 는 제안된 SPAUG 방식으로 image graph 를 구성했을 때이며, (b) 에서 (a) 에 비해 recall 은 올라갔으나 false positive 로 인해 precision이 내려간 것과는 달리, (c) 에서는 recall과 precision이 올라간 것을 확인할 수 있습니다. 또한 정량적으로도 Oxford 105k 에서 4.5% 가량의 성능 향상을 얻어냈습니다.
4. Reference
[1] https://www.robots.ox.ac.uk/~vgg/publications/2012/Arandjelovic12/arandjelovic12.pdf