https://arxiv.org/pdf/2006.13314.pdf
- Introduction
NAS(Neural Architecture Search)는 automatic design of deep learning network를 위한 연구분야이다. 이는 몇몇 데이터셋에서는 인상깊으리만큼 좋은 결과를 내었지만, 어마어마한 연산량 때문에 large-scale tasks (e.g. ImageNet)에는 적용하기 힘들었다. 이를 위해 논문 이전의 다른 방법들은 학습하는 에포크를 줄이거나 학습과 eval 과정에서 전체 target set이 아닌 proxy sets(sampling 값이거나, target과 비슷한 분포를 갖는 작은 집단)을 이용하는 등의 해결책을 제시하였다. 또한 이러한 해결책을 위하여 비록 CNN구조 탐색으로 한정지었지만 더 효율적인 NAS기반 모델인 NASNet과 같은 시도도 있었다.NASTransfer 또한 위와 비슷한 이름의 순서를 가졌다.논문은 CIFAR10과 같은 small scale 데이터셋을 이용에 치중하지 않고, 좋은 proxy sets을 설계하고, 성공적으로 transfer하는 방법을 실험적으로 연구하여 proxy sets과 architecture사이의 의존도를 밝히려 한다. - NASTransfer Benchmark
2.1 목적
논문의 목표는 각각 다른 NAS methods와 proxy sets에 대한 architecture transfer 성능을 diagnostic 정보로 제공함을 목적으로 한다.
2.2 데이터셋과 proxy sets
데이터셋으로는 CIFAR10, CIFAR100, ImageNet1K, ImageNet22K를 사용하였다. proxy sets으로는 2가지 방법을 사용하였는데, 하나는 N개의 classes를 선택하여 그들 모두를 사용하는 1)random selection방식과few shot learning과 비슷하다?, 다른 하나는 각 class 내에서 전반적인 분포를 유지하며(각 클래스마다 퍼센트를 유지하며) uniform하게 sampling하는 2) uniform selection 방식이다.
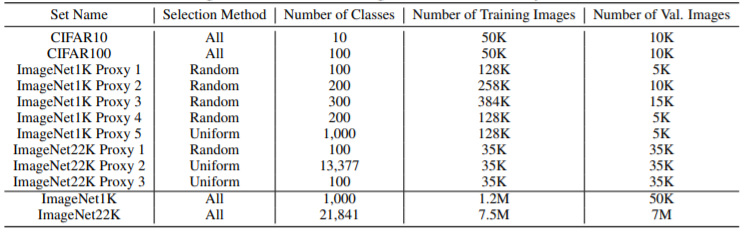
3. 분석 결과
3.1 Transferring Architectures
각 NAO, ENAS, DARTS는 NAS의 방법들
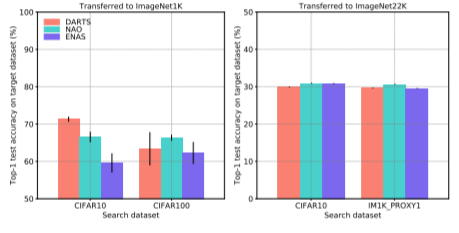
3.2 Direct Search using Proxy Sets
탐색에 있어서 target dataset에서 직접 추출한 proxy sets의 이점을 확인하기 위하여 탐색된 구조와 randomly sampled 된 결과의 성능을 비교하였다. 각 방법은 5번씩 탐색하였고, 결과의 평균과 분산값은 아래 그림3와 같다. 1)medium scale의 균일한 분포를 갖는 데이터셋을 분석하였을 때 (==ImageNet1K), classes와 예제의 갯수는 최소한도가 보장되는 한 성능에 크게 영향을 미치지 않았다. 이는 표1 기준으로 proxy 1,2, 3의 결과를 뒤에서 비교하였을 때 알 수 있다. 또한, class의 갯수를 줄여 random sampling하는 것이 모든 class를 유지하는 것보다 더 좋은 성능을 보였다 이는 proxy 5의 결과를 통해 알 수 있을 것이다.
2)다음으로 치우친 class 분포를 갖는 large scale datasets를 분석하였을 때는(==ImageNet22K) proxy set에 따라 전체적인 성능 뿐만 아니라, NAS 방법마다 성능의 순위도 바뀌었다. 표1을 기준으로 proxy1의 방법은 다른 sampling에 비해 우수한 성능을 내었다. proxy2, 3의 방법은 모든 NAS 방법에서 낮은 성능을 보였고 DARTS 방법론은 하위성능을 내는 모델에서 상위성능의 모델로 바뀌었다. 이렇한 결과를 통해 Proxy set 설계의 중요성을 확인할 수 있으며, random sampling시 클래스 당 이미지의 갯수를 유지하는 것이 class의 갯수를 유지하는 것보다 중요함을 입증한다.
외에도 다양한 실험이 있다
4. Conclusion
NAS를 위한 proxy sets을 디자인할 때 주의할 점은 다음과 같다
1) 클래스 당 이미지의 갯수가 proxy sets 전체의 갯수보다 중요하다
2) proxy set의 도메인은 target dataset에 대한 architecture 성능에 별로 영향을 미치지 않는다
3) proxy set이 target set에서 직접 sampled 되었을 때 (비록 도메인이 달라도 상관 없지만) 클래스 별 이미지의 수를 유지하는 것이 모든 클래스를 유지하는 것보다 좋다.
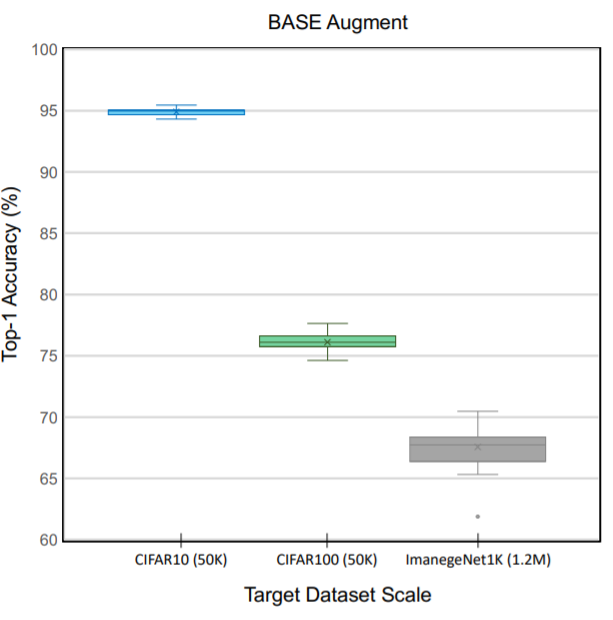
4) target dataset의 크기가 증가하였을 때, proxy set과 NAS method 선택은 training protocol 이나 hyper-parameter 보다 데이터 argumentation이 더 중요하다
5) random sampling은 이미 강력하지만, proxy-set과 search method의 선택조합을 통해 여전히 개선의 여지가 있다
참조 링크
http://research.sualab.com/review/2018/09/28/nasnet-review.html