
논문: Deep Hough Voting for 3D Object Detection in Point Clouds
블로그 시리즈:
1. Review: PointNet
2. Review: PointNet++
블로그 시리즈에서 언급한 바와 같이 이번 논문은 작년 서울에 있었던 ICCV2019에서 oral presentation을 진행하고 best paper에 nominate[1]된 VoteNet입니다. 참고로 oral presentation 영상은 아래의 영상을 참고해주세요.
VoteNet은 최근 3D object detection 연구는 정보 손실이 발생하는 2D detector에 크게 의존하는 것을 극복하고자 PointNet++[2]을 사용하여 point clouds data에서 feature를 뽑아서 object detection을 하는 새로운 end-to-end 파이프라인을 제시하고 있습니다. 이름에서 유추할 수 있듯이 network 중간에 Hough voting[3] 방법을 적용하였습니다. 공식 코드는 https://github.com/facebookresearch/votenet 에서 확인하실 수 있습니다.
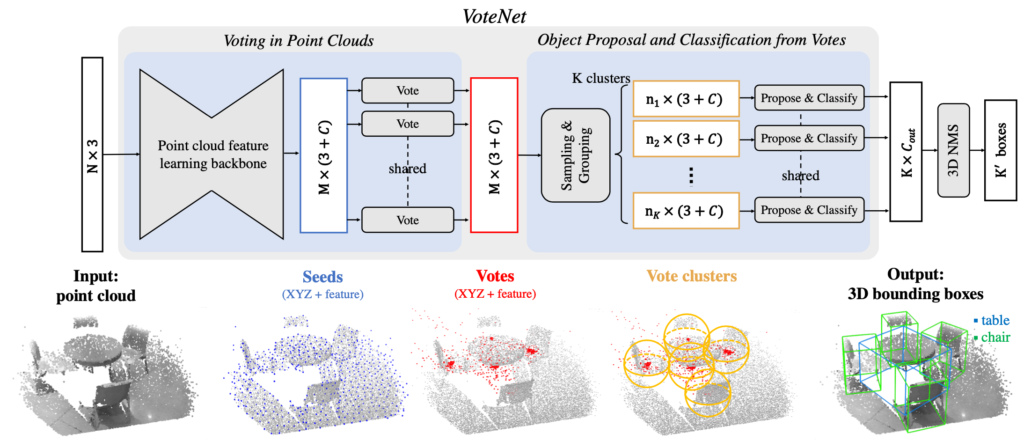
우선 VoteNet의 구조는 그림 1과 같습니다. 크게 4단계로 이루어지며 각 단계는 (1) Interest points 찾기(그림 1에서 Seeds), (2) Voting, (3) Vote clustering, (4) Object proposal 입니다.
(1) Interest points
PointNet++를 통해 feature를 뽑아내는 과정입니다. 그림 1에서는 Seeds라고 표기되어 있고, 각 feature의 (x, y, z) 좌표와 길이가 C인 feature vector를 모두 M개를 얻는 과정입니다.
(2) Voting
[3]은 Hough transfrom을 이용하여 2D object detection을 하는 방법을 서술한 논문입니다. VoteNet에서는 deep neural network와 3D data를 사용하기 위해 심플한 방법을 사용합니다. 여기에서 저자의 성향을 볼 수 있는데 PointNet과 PointNet++와 마찬가지로 network는 2개의 perceptron layer를 사용하였고, 각 layer마다 batch normalization을 수행하여 vote를 얻게 됩니다. Interest points로 부터 생성된 voting들은 같은 object에 더 가까워지는 효과를 가져다 줍니다. 왜냐하면, voting의 학습을 위해 ground truth에서 object의 bounding box center에서 떨어진 거리를 줄이는 방법으로 학습하기 때문입니다.
(3) Vote clustering
그림 1과 같이 M개의 vote를 uniform random sampling하는 방법을 택합니다.이렇게 sampling한 vote들로 서로 이웃하는 것들끼리 K개의 clustering에 속하는 sample을 구분해 주면 됩니다.
(4) Object proposal
각 clustering의 sample을 이용하여 3D bounding box를 만들게 되는데요. 여기서 제안하는 proposal generation의 구조도 voting에서 쓰였던 MLP와 비슷한 구조이며, 최종 출력으로 K개의 bounding box 정보를 얻을 수 있습니다.

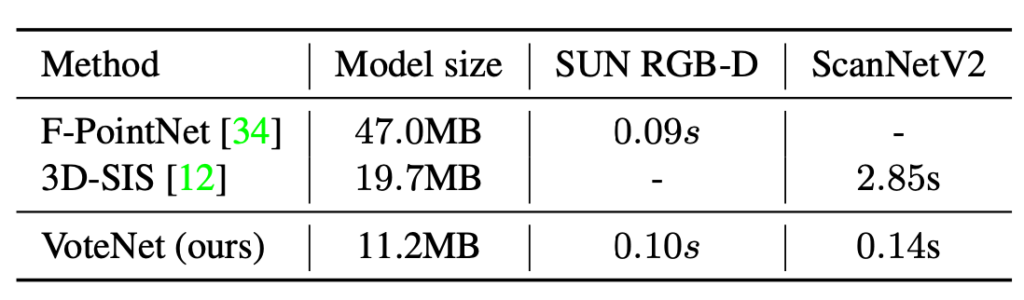
표 1과 같이 VoteNet은 제한된 3D object에 있어서 대부분 좋은 성능을 보여주고 있지만 책장과 테이블에 대해서 성능이 상대적으로 낮은 점을 보았을 때 네모 반듯한 물체보다 좀 더 입체적인 물체에 대해 더 좋은 성능을 가지는 것이 아닐까 합니다. 그리고, 표 2는 다른 연구와 비교하여 모델의 사이즈가 4배가 작고, 실행 시간이 20배 빠른 실행 시간을 보여주고 있습니다.


표 3은 Voting의 적용 유무에 대한 정확도 비교로 Voting이 확실히 성능을 높이는데 효과가 있다는 것을 보여줍니다. 그림 2도 마찬가지로 각 물체별 표현하는 point의 개수가 훨씬 더 많은 것을 확인할 수 있습니다.
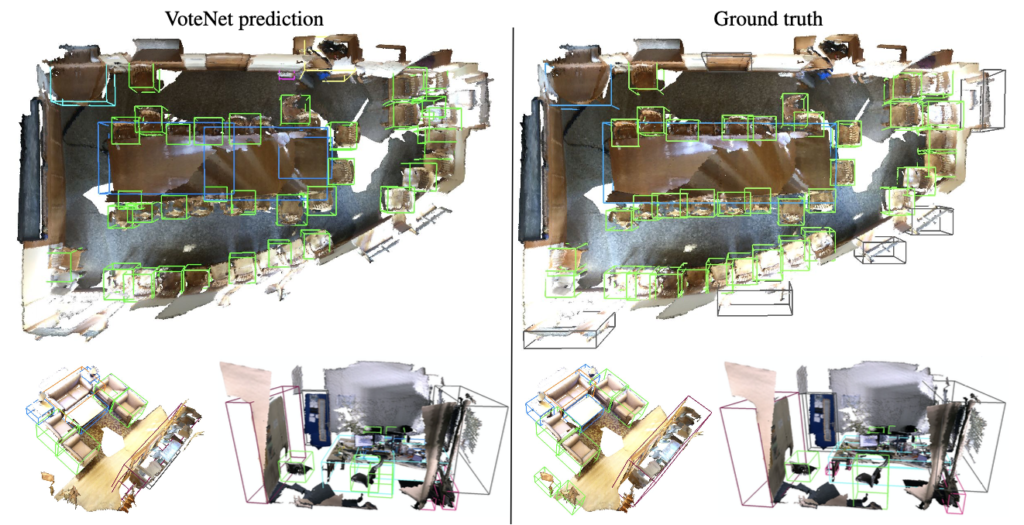

그림 3, 4는 각 데이터셋 별로 ground truth와 비교한 것이며, 상당히 좋은 결과들을 골라서 보여준 것으로 보입니다.
2D의 사례를 미루어보아 3D dataset은 3D convolution을 해야할 것만 같았습니다. PointNet부터 시작한 저자의 아이디어는 raw data의 형식에 주목해서 해결해 나가는 모습을 보여주고 있습니다. 3D object를 colorful하게 reconstruction 하기 위해서는 모순 되는 이야기지만 3D raw data에 주목하는 것이 texture를 적용하기 어렵게 만든다고 생각됩니다. 지난 PointNet++에서 질문이 나온 것과 같이 사람 또는 마네킹을 구분하기 위해서는 texture가 적용되야 문제를 풀 수 있지 않을까 생각합니다.
참고:
[1] ICCV 2019 Awards
[2] PointNet++: Deep Learning on Point Sets for 3D Classification and Segmentation
[3] Object detection using a max-margin Hough transform
[4] ImVoteNet: Boosting 3D Object Detection in Point Clouds with Image Votes
좋은 리뷰 감사합니다
읽다가 조금 이해가 안가는 부분이 있어서 질문 남깁니더
l. layer 를 통과한 Vote를 Sampling을 통해 M개를 얻고 그것들을 K개의 인접 cluster로 구분한다고 이해했느데 맞나요..?ㅁ
2. 1 이 맞다면 그 인접한 feature라는 건 어떻게 구분하나요..? feature의 위치 정보도 있나요…?
3. 2개의 perceptron layer ㅏ용되었다고 하셨는데 그 두개가 하나의 타워에 속한 건가요..? M 개가 output 같은데 뭔가 그림은 M개의 태워에서 Vote가 나오는 거 같아서 살짝 헷갈리네요
1. M개의 포인트가 각 vote를 통해 나온 개수가 M개로 동일한 것이고, sampling을 통해 개수는 M개 보다 줄어들게 됩니다. sampling된 vote들을 K개의 cluster로 묶는 것입니다.
2. vote 데이터에는 [(x,y,z); vote] 와 같은 형식으로 좌표와 feature(여기서는 vote라고 말합니다)를 concatenation 해 놓은 것이므로 위치 정보도 포함됩니다. 참고로 데이터는 각 오브젝트(또는 label) 별로 포인트 좌표도 가지고 있습니다.
3. 질문에서 하나의 타워라는 용어는 멀티레이어를 쌓은 네트워크를 말하는 것으로 이해하고 답변하겠습니다. 일단 일반적인 뉴럴네트워크인데 그림으로 보았을 때 헷갈렸을 수도 있습니다. 그림1에서 shared의 의미는 같은 네트워크를 사용한다는 의미로 일반적인 grandient descent 라고 보시면 됩니다.