Keywords: Image captioning, pretraining, transfer learning
[논문링크]
introduction
시각적 표현을 학습하는데 있어 일반적으로 pretrain된 CNN을 이용한다. 이러한 접근법은 성공적이나, human workers에 의한 정보이므로 pretrain을 위한 데이터셋을 추가하기에 비용이 많이 든다. 이러한 이유로, unsupervised pretraining 방식이 인기를 끓었었다 그러나, 적은 이미지로 높은 수준의 visual representations을 학습하는 것 또한 비용을 줄이기 위한 대책이 된다. 이 논문은 후자를 이용하려 하였으며, 궁극적으로는 textual annotations을 이용해서 학습하는 것이 ImageNet으로 supervised하게 또는 unspervised하게 pretrain된 다른 결과와 비등하거나 더 낫다는 것을 보인다. 즉 visual과 language를 이용한 pretraining으로 visual feature의 경쟁력을 높일 수 있음을 보이며, 이러한 이점에 비해 language를 이용한 labeling이 더욱 의미있는 정보를 기존 annotation보다 더욱 쉽게(classification label 항목을 정하거나, 정제할 필요가 없음) labeling할 수 있다고 밝힌다.
Method
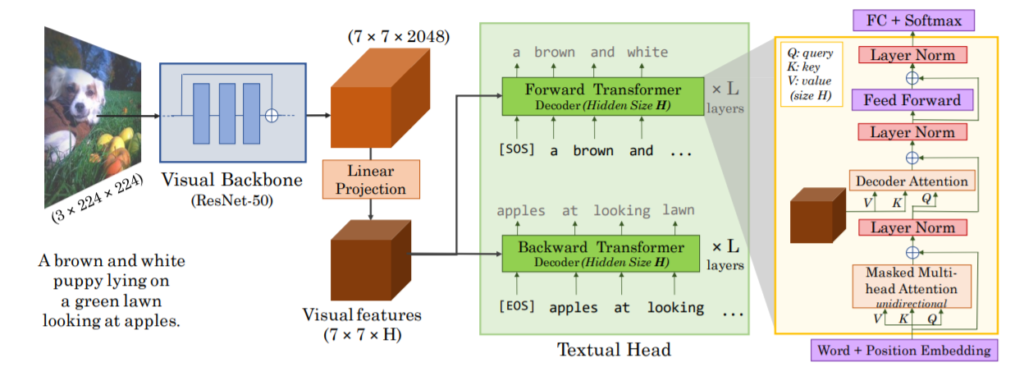
이 논문의 목적은 caption이 있는 이미지 데이터셋을 이용하여 downstream visual recognition task (이미지 분류, 물체인식, instance segmentation, low-shot recognition 등) 를 위한 visual representation을 학습하는 것이다. captioning을 통한 정보가 많은 주석(일반적인 주석은 고양이, 케이크 라는 정보만을 갖는다면 captioning을 이용한 주석은 케이크를 바라보는 고양이, 붉은 케이크 등 더욱 많은 정보를 갖고 있다.)을 통해 visual representation을 학습하기 위하여 image captioning model을 학습하였다. 이 구조는 그림1과 같이 소개되었다. 모델은 visual backbone과 textual head로 이루어져있다. visual backbone은 이미지의 visual features를 추출하고, textual head는 visual features를 통해 caption C를 token별로 예측한다. taxtual head는 양방향 captioning으로 작동한다(forward model: tokens을 왼쪽에서 오른쪽으로 예측, backward model: tokens을 오른쪽에서 왼쪽으로 예측) 이는 caption token의 log-likelihood를 최대화 하기 위해 token by token이 아니라 한번에 학습된다 Loss 함수는 다음과 같다.
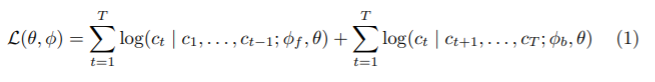
이때 θ, φf , and φb는 각각 visual backbone, forward, backward 모델의 파라미터들이다.학습 이후 textual head는 폐기하고 visual backbone은 downstream visual recognition tasks에 사용된다.
실험결과
이 논문은 실험을 통해 language annotation(==caption)의 의미밀도가 high-quality의 visual representation을 적은 데이터로 학습할 수 있음을 보이고자 한다. 논문은 ResNet-50을 random 초기화 후 제안하는 방식으로 학습하였다. 데이터로는 COCO Captions를 사용하였다.학습 이후 visual backbone을 이용하여, downstream recognition tasks를 해결한다. 비교한 모델들은 다음과 같다. Random, ImageNet-supervised(IN-sup), PIRL[1], MoCo[2]
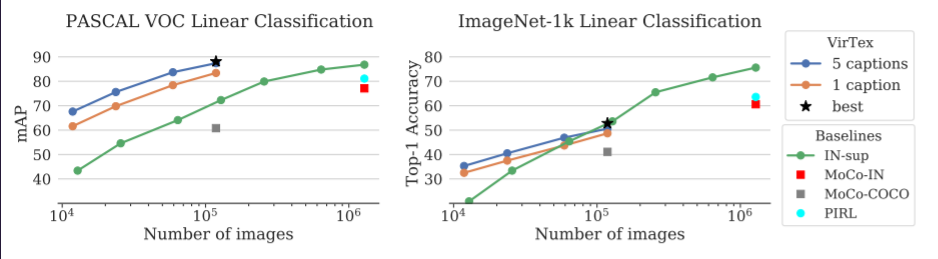
Ablations
1. captions은 정말로 의미 밀도가 좋은가, 또한 bicaptioning( 양방향 captioning )는 정말로 강력한 training signal에 효과적인가?

2. bigger transformers가 더 좋은가?
기존의 language modeling 연구에서 큰 Transformers가 더 좋은 textual features를 학습하는 경향을 보였다. VirTex모델도 이러한 경향을 보이는지 실험하였다.

3. bigger visual backbones이 더 좋은가?
더 큰 visual backbones이 visual recognition task에서 성능을 개선시키는 경향이 있다. 저자는 이러한 경향을 VirTex에서도 확인할 수 있는지 실험하였다. 실험 결과는 표3에서 확인할 수 있듯이, visual backbone이 더 넓거나 깊을때 (즉 더 클때) 성능이 향상됨을 확인하였고, 이때 IN-sup(ImageNet-supervised model)와 비슷한 성능을 보이거나 더 좋은 성능을 보임을 확인할 수 있다. IN-sup의 결과와 비교를 위해 회색글씨로 결과를 나타낸 것을 표3에서 확인할 수 있다.

외에도 Fine-tuning(위는 frozen visual backbone 실험)을 통한 Transfer나 Image Captioning와 같은 다양한 실험을 하였다.
[1]Misra, I., van der Maaten, L.: Self-supervised learning of pretext-invariant representations. In: CVPR. (2020)
[2] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR. (2020)
의문점
1. 논문에서는 classification라벨이 기존 라벨보다 정제의 가정을 거칠 필요가 없어 쉽다 하였지만, 사람마다 라벨링의 깊이 (ex 고양이, 갈색 줄무늬를 갖는 고양이, 갈색과 흰색이 줄무늬를 갖는 고양이)가 다를 수 있기 때문에 이러한 부분에서 더욱 정제비용이 들 것 같다는 의문이 든다.
2. 여러개의 이미지에서 “케이크를 보는 고양이”를 나타낸 사진은 많지 않을 것이라 생각한다. 즉, “케이크를 보는”이 풍부한 정보가 되는것이 아니라 “고양이” 라는 라벨에 노이즈의 역활을 하면서 성능이 향상된 것이 아닐까 하는 궁금증이 생겼다. (풍부한 정보탓이 아닌 class가 갖는 instance의 다양성에 노이즈를 통해 불확실성을 주면서 성능이 높아진것이 아닐까)
관심있는 연구 분야로 리뷰를 하셨군요. 이 논문에서 같이 고민해보고 싶은 문제를 먼저 물어보고 싶습니다.
이 논문의 출발점은 이미지에 레이블링을 많이 하는 것이 비용이 많이 든다고 했습니다. 그래서 높은 품질의 이미지와 문장을 사용하는 것이 적은 비용이 든다라고 했는데요. 과연 이미지와 높은 품질의 캡셔닝 데이터가 비용이 적게 들까 의문이 듭니다. 데이터의 품질 측면에서는 이해할 수 있는데 비용적인 측면에서 저는 반대 입장이라 리뷰를 쓰신 분 입장에서 이야기를 듣고 싶습니다.
내용 중 궁금한 점도 하나 있습니다. “textual head는 양방향 captioning으로 작동한다.” 부분에서 양방향이 그림의 forward transformer와 backward transformer로 보이는데 이게 어떤 역활을 하는지 모르겠습니다.
좋은 글 감사합니다.
내용의 주제가 흥미로워서 재밌있게 글을 읽었네요.
제 질문 역시 박종민 연구원님의 질문과 유사하게 캡셔닝 데이터의 비용도 만만치 않아 보여서 해당 방법론이 비용 절감을 해결할 수 있을지에 대한 의문이 생기는데 질문에 대한 답변이 아직 없어서 아쉽습니다.
또한 캡셔닝 데이터에 대해 처음 접하게 되었는데, 혹시 캡셔닝 데이터로 유명한 데이터 셋을 해당 논문에서 언급한게 있는지 궁금합니다.