
1. Introduction
- GNSS를 사용한 Localization 은 현대 도시에서 한계를 보이기 때문에 Visual 방식을 사용해야함
- visual 방식으로 는 lidar 방식과 vision 방식이 있다
- Lidar 방식은 아직 차에 달기에는 부족함이 많고 , 이미지를 통한 local localization에 문제가 많다는 연구들이 있다.
- 현재 이미지를 사용한 localization 은 CNN이나 RF를 많이 쓴다. 그치만 이방법론들은 데이터의 의존도가 높다는 단점이 있기 때문에 자율주행에 부적합하다
- 많은 HD Map 구축 회사들은 Lidar 정보와 영상정보를 같이 제공한다. 그리고 이러한 3D HD Map은 미래 자율 주행차에 상용 될것이다.
- 2D-2D 에서의 localization 의 성능과 3D-3Dlocalization 의 성능은 우수하지만 2D-3D 의성능은 센서의 차이로 인해 낮은 게 현 상황이다.
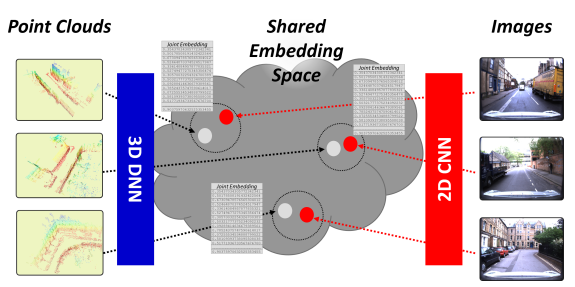
- 이 논문에서는 3D Map 과 RGB image을 DNN을 사용해 global visual localization problem 해결하는 방식을 제시한다.
- [그림2] 와 같이 다른 두 센서를 하나의 공간에서 표현하여 문제를 해결한다.
2. Proposed approach
기존 visual place recognition techniques 과는 다르게 Query 이미지가 나타내는 point cloud point를 Retrieval 한다. 이미지와 point cloud 를 비교하기 위해서 , 다른 데이터라도 같은 장소라면 비슷한 표현을 하게 하는 Embadding space를 학습한다. 이 논문은 [1]과 [2]로 부터 영감을 많은 영감을 얻었다.[1] 과의 큰차이점은 inference에서 RGB 영상만을 필요로 하기 때문에 자율주행 차에서 활용가능성이 크다는 것이다. 그리고 [2]보다 큰스케일에서 동작한다는 장점이 있다.
Global Localization을 풀기 위해 메트릭 러닝을 사용했다. EVs라는 공간에서 EV라는 벡터로 두 센서가 변환되어 메트릭 러닝을 통해 학습한다.
2.1 2D Network Architecture
RGB 이미지는 두가지 과정을 거친다. 1. CNN으로 local feature로 만든다. 2. 고정된 벡터로 변환되 EV에 제공한다. local feature를 만들기 위해서 VGG16과 RestNet18 둘다 실험에 사용했다. 그리고 고정 벡터로 변환을 위해 NetVLAD와 MLP(MultiLayer Perceptron) 을 사용해 실험을 했다.
2.2 3D Network Architecture
2D network 와 비슷하게 3D 도 비슷한 과정을 거친다. 3D point로 부터 local feature를 얻는 모델의 SOTA 방식은 현재 확실하지 않으므로 여러 방식의 비교가 필요했다. 따라서 여러 모델을 사용해봤는데, 첫번째로는 PointNet, 두번째는 EdgeConv[3] 마지막으로 SECOND[4]를 사용했다. 세개의 네트워크는 placerecognition에 맞게끔 변환 시켜서 사용했다. 그리고 세개의 네트워크를 NetVLAD와 MLP를 사용해 고정벡터를 얻었다.
위 모델들을 모두 다른 입력 데이터를 사용하기 때문에 기존 평가 방식을 적용시켜 제공한다.
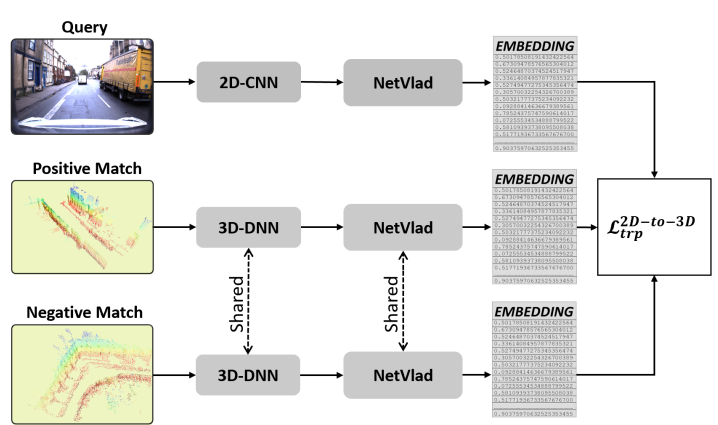
2.3 Teacher/Student Training
2D와 3D를 공유하는 DNN을 위해, teacher/student 방식을 사용한다. Teacher network는 각각의 공간을 학습하여 효율적인 Descriptor를 생성한다. student network는 Teacher network 가 생성한 것과 비슷한 output을 내도록 학습한다.
2D network 를 triplet Loss를 이용해 학습해 Teacher Network를 고정시킨다. 그다음 그림 3에서 같이 Query 이미지와 Positive point cloud 의 vector 의 차이가 줄어드는 Loss[식 1]로 student network를 학습한다.
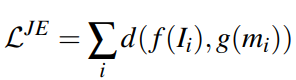
2.4 Combined Training
2D와 3D 모두학습하기 위한 총 로스는 다음과 같다.
Same-Modality metric learning: 각각의 space를 teacher 로써 학습하기위해 각각의 space를 triplet으로 학습한다 . 식은 식2 와 같다.
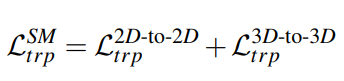
Cross-Modality metric learning.: student network를 학습하기위한 loss 이다. 식은 식3과같다.
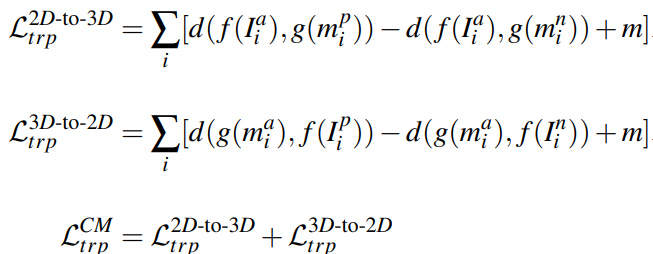
total loss는 식 4 와 같다.
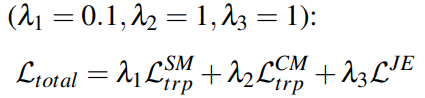
3. Results

2D-2D 과 2D-3D 성능은 기존 방법론들과 성능이 비슷하고 3D-3D 의성능은 SOTA성능을 보인다. 원하던 2D-3D의 성능은 두 테스크만의 성능의 비해 낮지만 제안하는 방법론의 참신성의 비젼은 제시할 정도의 성능으로 보인다.
# 결론
localization을 한번에 딥러닝을 통해 해결하는 방식을 찾다가 Pose 계산까지는 아니지만 3D 포인트까지 찾아내 많은 단계를 생략해내는 방법론을 찾아서 기분 좋은 마음으로 읽었다. 읽으면 읽을 수록 이 논문에서 제시하는 전체적인 느낌이 뭔가 MDII랑 비슷하게 다른 두 도메인을 하나의 공간에 표현하고자 한다는 것에 이 테스크를 이러한 방식으로 해결한다는 것에 굉장히 참신하다고 생각이 되었다. 결과적인 성능은 살짝 아쉬운 느낌이 있지만 그래도 이 논문과 [2[ 를 통해 모든 것을 DNN만으로 해결할 수 있을 것라는 생각을 해 굉장히 큰 비젼을 보았다. 이제 Regreesion만으로 pose를 계산하는 논문을 찾아서 읽어볼 생각이다.
# References
[1] PointNetVLAD: Deep Point Cloud Based Retrieval for Large-Scale Place Recognition
[2] 2D3D-MatchNet: Learning to Match Keypoints Across 2D Image and 3D Point Cloud
[3] Dynamic Graph CNN for Learning on Point Clouds
[4] SECOND: Sparsely Embedded Convolutional Detection
도심 자율주행을 위해 많은 회사에서 사용하는 2개의 센서 데이터를 퓨전하는 것으로 이해하면 되겠네요.
1. 논문에서 접근하는 방향 (섹션 2)에서 EVs라는 공간이 그림2의 shared embedding space로 이해하면 되나요?
2. 섹션 2.2에서 point clouds data를 3개의 네트워크를 사용했다는 뜻이 앙상블인가요? 아니면 3개 중 하나를 택했다는 건가요? 제 생각엔 비교를 해서 하나를 택한것 같은데 다른 이야기는 없었나요?
3. 메타러닝의 학습(섹션 2.3)에서 식1에서 두개의 차이(distance)를 계산하는 것으로 이해했습니다. 그렇다면 f(I)와 g(m)이 뜻하는 것은 무엇인가요?
(-) 섹션 2.1의 내용이 중복으로 작성된 것으로 보입니다. 오탈자의 경우 눈에 안보일 수도 있지만 이런 것은 글을 완성하고 한번만 다시 읽어봐도 찾을 수 있을 것으로 생각됩니다.
1. 넵, 그렇게 이해하시면 될 것 같습니다
2. 3개를 모두 사용해보고 서로의 성능을 비교해봤다는 것입니다. 사실 뒤에 각각 모델에 따른 성능도 있는데 제가 이 논문에 중요한 부분은 그 부분이 아니라 판단해 첨부하지는 않았습니다
3. f와 g는 각 도메인에서 netvlad 벡터를 생성하기 위한 모델입니다. 예를 들어 f는 vgg+NetVLAD g는 PointNet+NetVLAD 이런식입니다
좋은 논문 리뷰 잘읽었습니다.
조금 이해가 안되는게 있어서 질문드립니다.
2D에서 feature를 잘 추출할수있는 Teacher Network와 3D에서 feature를 잘 추출할 수 있는 Teacher Network 각각은 freeze 시키고, 새로운 Student Network를 학습시키는 방법인가요?? 그리고 지금 loss를 보면 결국 total loss라고해서 2Dto2D, 3Dto3D, 2Dto3D, 3Dto2D 등의 loss들이 합쳐져서 모델을 학습시키는거 같은데, 2Dto2D, 3Dto3D Loss에도 미소량이지만 0.1의 가중치를 더해서 loss를 backward 시키고 있습니다. 2Dto2D, 3Dto3D의 Teacher 네트워크는 freeze시켰는데, 해당 loss도 total에 포함시키는 이유는 무엇인지 설명하고있는지 궁금합니다.
NetVLAD 학습시 결국 Query가 2D면 pos,neg는 3D로, Query가 3D면 pos,neg는 2D를 사용하는거 같은데, 두 feature가 완전히 다른 Teacher network를 가지고있고, 이를 통해서 만들어진 feature를 metric learning으로 학습해봤자 서로 다른 도메인에 서로다른 네트워크로 만들어진 feature라 최선의 방법은 아니라고 생각되는데, student network가 Teacher network의 성능은 최대한 가져가면서 netvlad 사용시 두 다른 도메인의 서로다른 네트워크로 만들어진 feature간의 gap을 줄이는 feature를 만들어낼 수 있도록 student network가 학습되는건가요?
좋은 질문 감사합니다 .
이 논문에서 제시하는 학습 방식이 결국에는 2D끼리 NetVLAD를 학습시키고 그걸 teacher로 두고 2D-3D가 비슷한 벡터로 만들자 입니다. 사실 성능 자체도 보면 두 도메인의 갭을 완전히 줄였다 정도의 성능을 보이고 있지 않아서 최선이라고는 말씀드릴 수 없습니다 . 하지만 이논문에서는 위 방식으로 2D와 3D 간의 갭을 줄일 수도 있다는 방향성을 제시한게 크다고 이야기 하고 있어서 뭐 저도 그렇게 틀린 말은 아니라고 생각합니다
그 제가 리뷰한 부분에 착오가 있었네요 감사합니다.
그 Total loss에 해당 하는 네트워크부분들은 학습할 때 Freeze 시키지 않는다고 합니다. 그래도 Teacher /student loss 와 total loss의 상관 관계부분을 파악하지 못해서 조금더 읽어봐야 할 것 같습니다
혹시 Teacher network의 구조에 대한 자세한 설명이나 이를 보여주는 그림이 있을까요?
Teacher network라고 해서 따로 모델을 설계한 것이 아닌 학습 시에 Teacher는 freeze시키는 방향으로 했습니다. Teacher 모델의 학습은 기존 한 도메인의 대한 Netvlad학습과 동일합니다